数据源管理
数据服务提供高可用的数据源,支持MySQL、Oracle、SQLServer、PostgreSQL、DB2、阿里云Analytic DB、RDS、TiDB、Impala、Kylin、ElasticSearch、MongoDB等多种数据源,支持数据连接性测试。
支持的数据源类型
| 数据源分类 | 数据源类型 | 向导模式 | 自定义SQL模式 | 版本 |
|---|---|---|---|---|
关系型数据库 |
Analytic DB |
Y |
Y |
|
DB2 |
Y |
Y |
DB2 9、10 |
|
MySQL |
Y |
Y |
MySQL5.1.5及以上 |
|
Oracle |
Y |
Y |
Oracle 10、11 |
|
SQLServer |
Y |
Y |
SQLServer 2012及以上 |
|
PostgreSQL |
Y |
Y |
PostgreSQL 10.0及以上 |
|
KingBase |
Y |
Y |
KingBase 8.2、8.3 |
|
分析型数据库 |
Impala |
Y |
Y |
cdh6.0以上 |
Kylin |
Y |
Y |
||
TiDB |
Y |
Y |
TiDB 3.x以上 |
|
NoSQL |
HBase |
Y |
N |
HBase 1.2及以上 |
ElasticSearch |
N |
Y |
Elasticsearch 5.X、6.X、7.X |
|
MongoDB |
N |
Y |
MongoDB 4.0及以上 |
数据源配置
生成API的前置条件是需将数据源配置完成。配置数据源的步骤可分为三步。
步骤一:点击数据源管理下的"新增数据源",进入数据源配置窗口。
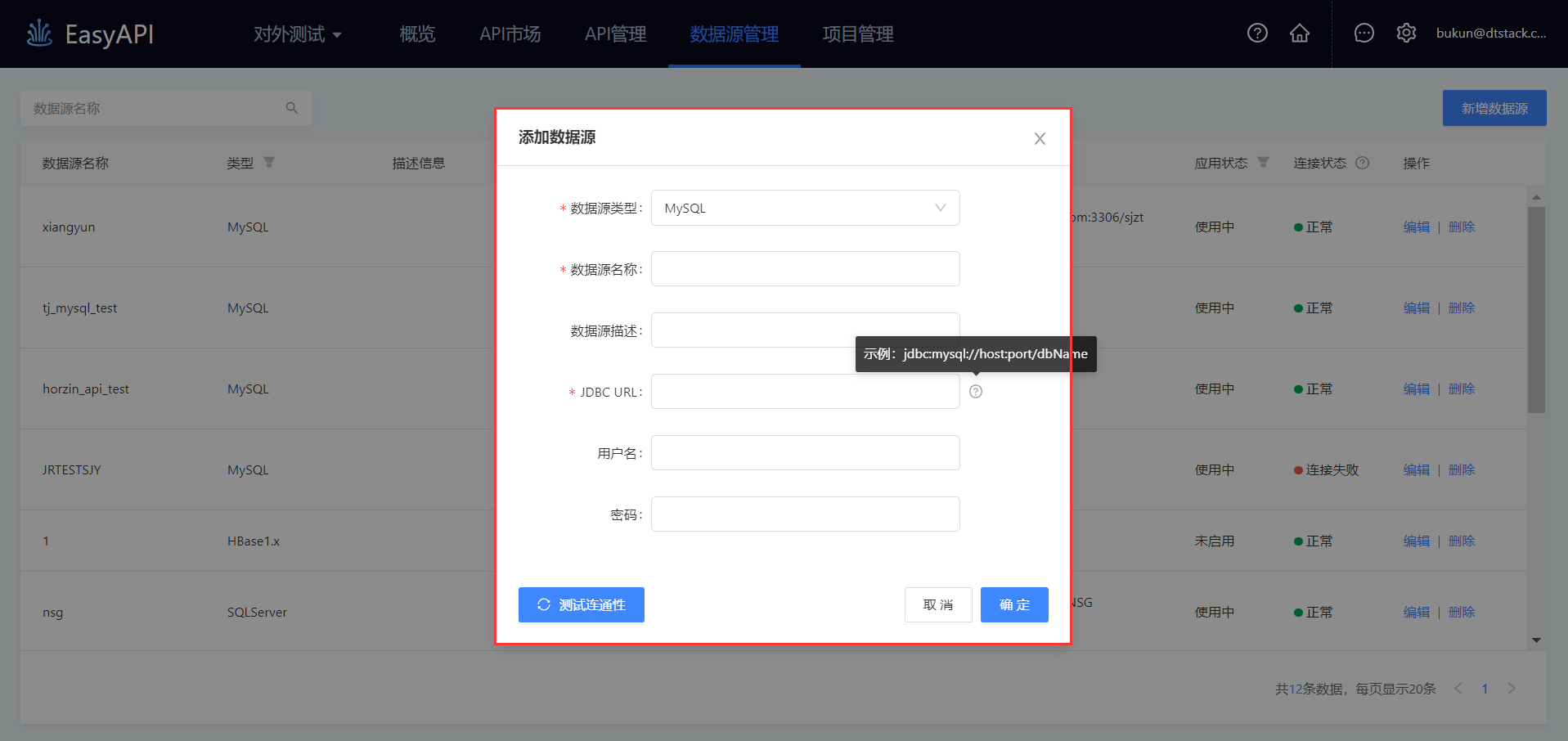
步骤二:配置数据源连接信息,填写数据库连接地址,用户名,密码等。
关系型与分析型数据库
关系型数据库与分析型数据库的数据源配置基本是类似的,其原理为利用JDBC将Java代码连接到数据库,从而向数据库发送SQL命令,并处理数据库返回的结果。下面的描述适用于Analytic DB、DB2、MySQL、Oracle、PostgreSQL、SQLServer、TiDB、Impala、Kylin、KingBaseES8。
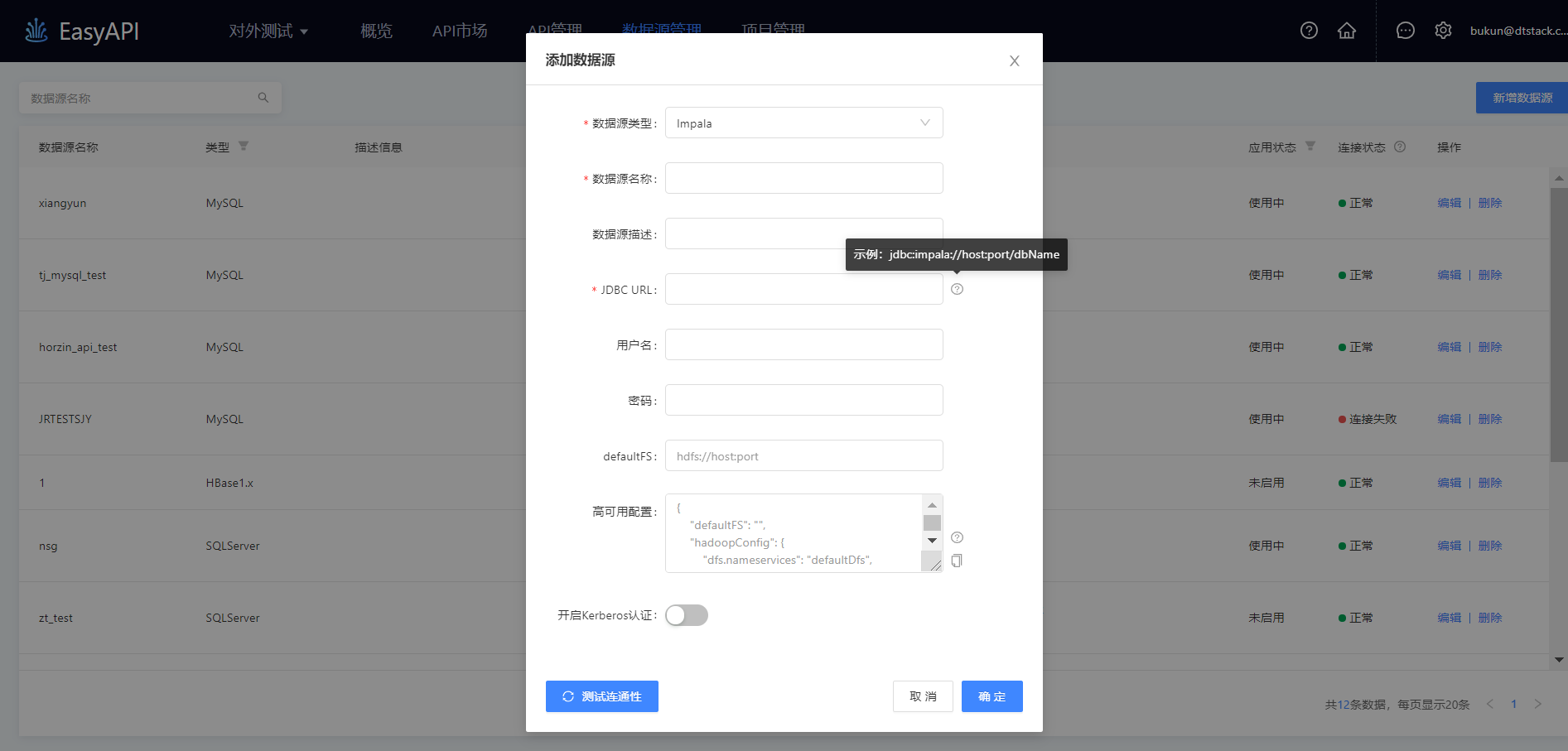
这里以Impala数据源为例,配置数据源所需连接信息如图所示
-
JDBC URL: 访问Impala数据库的连接地址,JDBC URL格式如:
jdbc:impala://localhost:port/dbname
-
host:Impala的host名或ip地址
-
port:Impala的访问端口
-
dbname:Impala的数据库名,用户后续配置API时,可选择库内的数据表。
-
用户名:访问数据库的用户名
-
密码:访问数据库的密码
-
DefaultFS: 默认情况下,此参数配置为:`hdfs://host:port`。
-
高可用配置:补充高可用配置参数,可以使API访问高可用模式下的Impala数据源,高可用配置的格式及示例如下:
dfs.nameservices
dfs.ha.namenodes.${nameservice名称}
dfs.namenode.rpc-address.${nameservice名称}.${namenode名称}
dfs.client.failover.proxy.provider.${nameservice名称}{
"dfs.ha.namenodes.ns1":"nn1,nn2",
"dfs.namenode.rpc-address.ns1.nn1":"172.16.101.196:9000",
"dfs.namenode.rpc-address.ns1.nn2":"172.16.101.227:9000",
"dfs.client.failover.proxy.provider.ns1":"org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider",
"dfs.nameservices":"ns1"
}| 每个数据源必须指定一个DataBase,如果需要从多个库中获取数据,可配置多个数据源 |
NoSQL
NoSQL数据库的数据源配置较为类似,通过连接集群达到数据源配置的目的,例如HBase提供Zookeeper集群地址做为访问地址。下面的描述适用于HBase1.x、2.x,ElasticSearch、MongoDB。
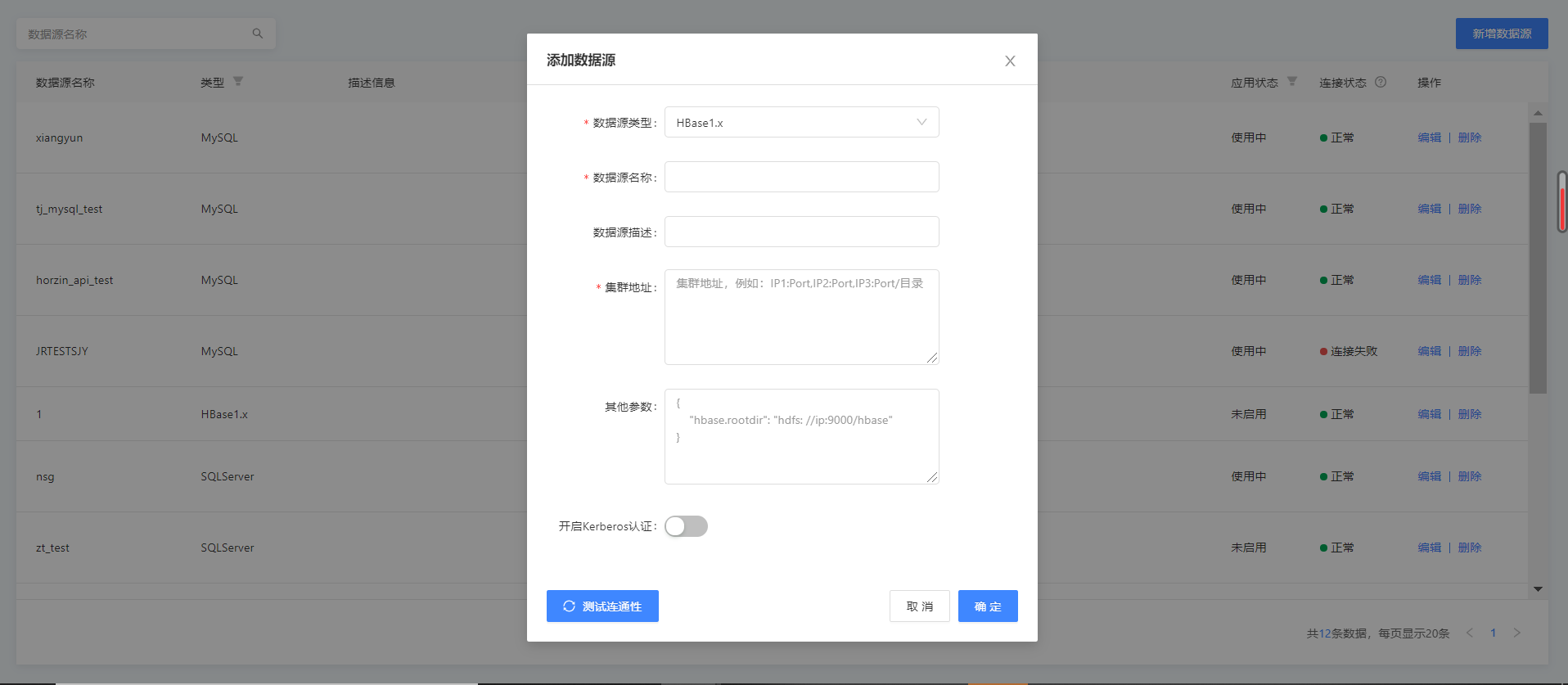
这里以HBase1.x为例,配置数据源所需连接信息如图所示
-
Zookeeper集群地址: 必填,多个地址间用逗号分割。例如:
IP1:Port, IP2:Port, IP3:Port/子目录,默认是localhost。 -
其他参数:以JSON方式传入其他参数,例如:
"hbaseConfig": {
"hbase.rootdir": "hdfs: //ip:9000/hbase",
"hbase.cluster.distributed": "true",
"hbase.zookeeper.quorum": "***"
}-
Kerberos认证:
Kerberos是用于身份认证并且能够提供双向认证的协议。为加强安全性,数据源连接过程中可选择进行Kerberos鉴权,通过获取客户端的principal和keytab文件在应用程序中进行认证。目前数据服务支持Kerberos认证的数据源有HBase和Impala。
以HBase1.x为例,需要进行的操作如下
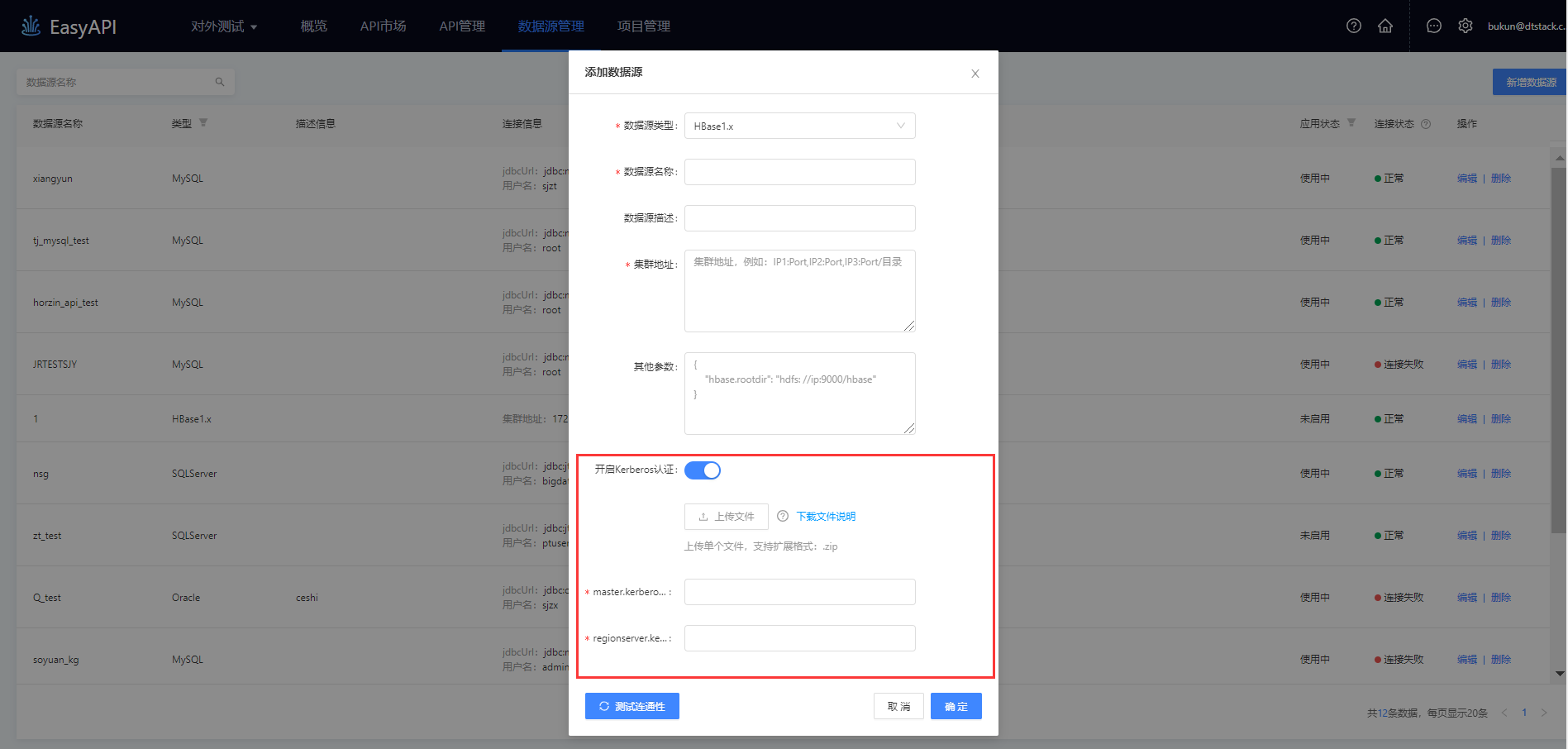
-
第一步:在控制台打开SFTP服务。
-
第二步:上传Kerberos认证文件:下载《文件说明》查看上传Kerberos认证文件的具体要求,随后在上传文件处上传单个zip格式的文件。
-
第三步:确定principal:Kerberos认证主体,系统从用户上传的Kerberos认证文件(在图中的上传文件处按照规则上传)中读取,默认选中第一个principal用户,下拉菜单可切换为其他用户。
-
第四步:输入HBase.master.kerberos.principal、HBase.regionserver.kerberos.principal 开启Kerberos认证的安全集群中HBase的Kerberos用户。
步骤三:测试数据源连通性,完成数据源配置。
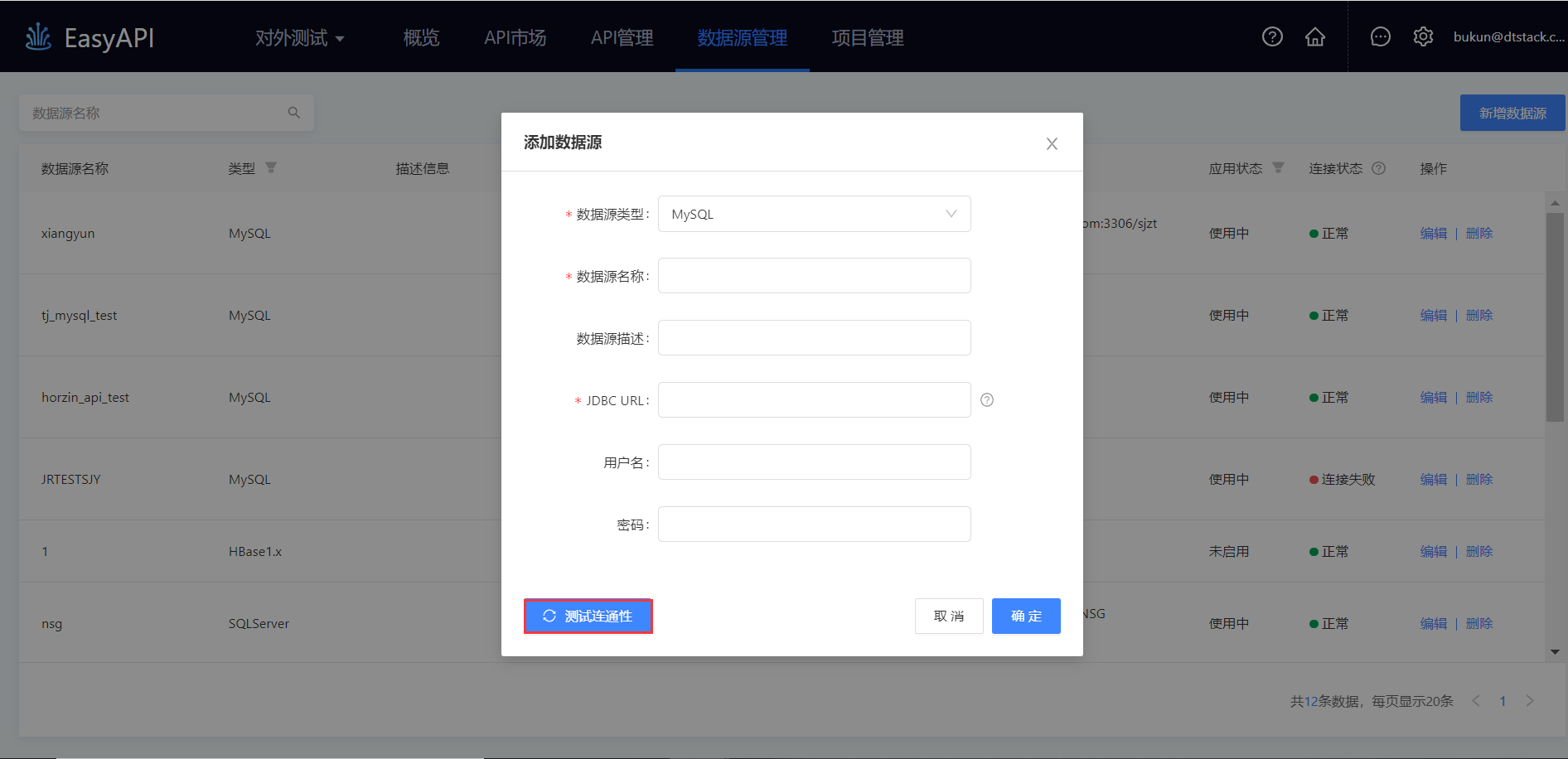
在添加/编辑数据源时,完成参数填写后,需主动测试数据源的连通性,只有数据源连接正常的情况下才可以被添加/编辑。
| 此处的连通性检测只是表示数栈的Web服务器与数据库是连通的,因此此处的连通性成功或失败,并不一定表示底层的连通性。 |
