规范建表
Hive建表
需求背景
传统的Hive建表,用户会直接通过IDE进行SQL编辑,该方法虽然符合大部分开发的使用习惯,但是会存在诸多不规范的现象。如表名、字段名随意写,没有满足同名同义的要求,导致后续数据理解出现偏差。
功能介绍
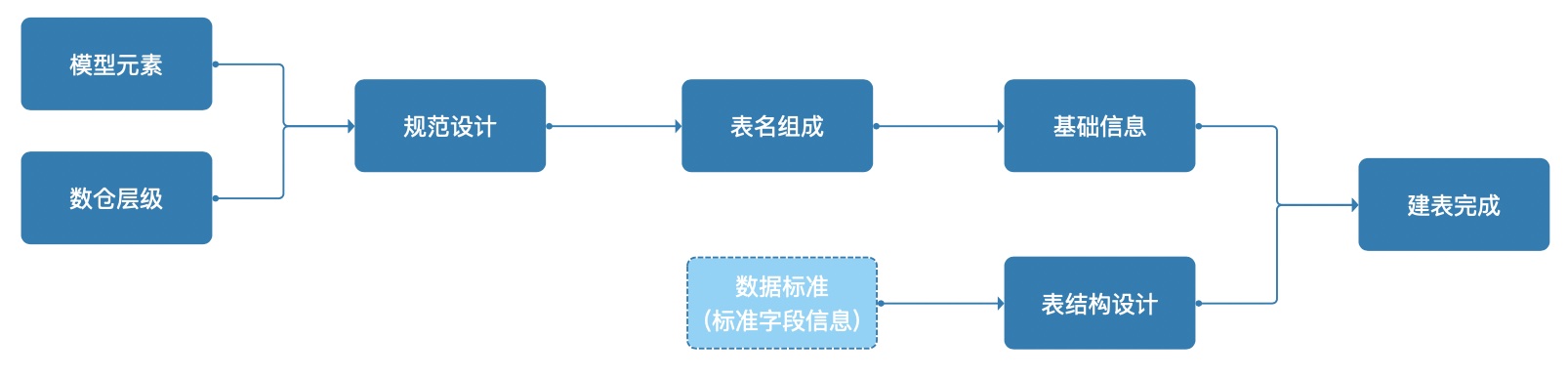
规范设计
-
数仓层级
为数仓数据进行合理的层级划分,系统内置基础的ODS/DWD/DWS/ADS/DIM五个标准的数仓层级,并支持用户根据自己的实际场景进行增删改 -
模型元素
模型元素可以理解为数仓表的属性信息,并且会影响表名的组成结构。系统会内置几个基础属性信息,如业务系统、主题域、更新方式、自定义内容。每个元素可应用在不同的数仓层级中。 -
层级规范设计
每个数仓层级的规范,需要根据实际情况进行合理的设计。下面举两个常见的例子:
ODS层:该层级数据一般用于存储从业务系统同步过来的原始数据,因此模型元素需要把业务系统元素添加进去。
DWS层:该层级数据一般用于存储经过加工的指标数据,因此模型元素需要把主题域元素添加进去。1、每个层级由若干个元素拼接组成,元素内容和拼接顺序,决定了该层级中表名的组成规范;
2、需要为每个层级绑定一个数据库用于存储数据;
建表逻辑
-
基础信息
-
页面会根据选择的数仓层级,对应显示该层级中的模型元素。用户选择相应的模型元素时,表名处会自动拼接元素英文名称。
-
表名处需要手动维护的部分,代表模型元素中的「自定义内容」。
-
表中文名落库时表示表comment信息。
-
存储格式:支持Parquet/ORC/Textfile。
-
生命周期:对于分区表和非分区表有不同的管理逻辑,详见产品内的提示内容。
-
-
表结构
-
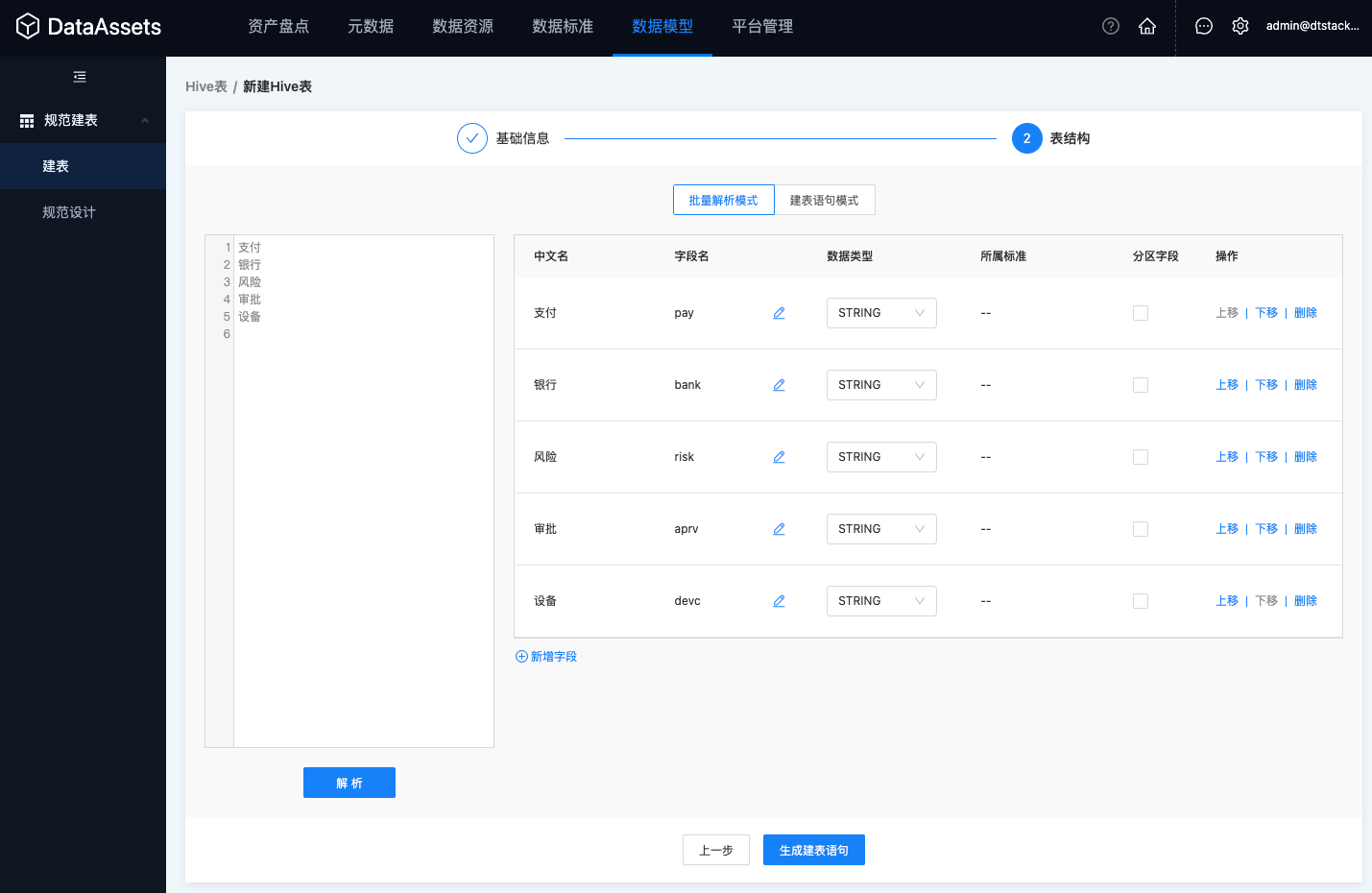
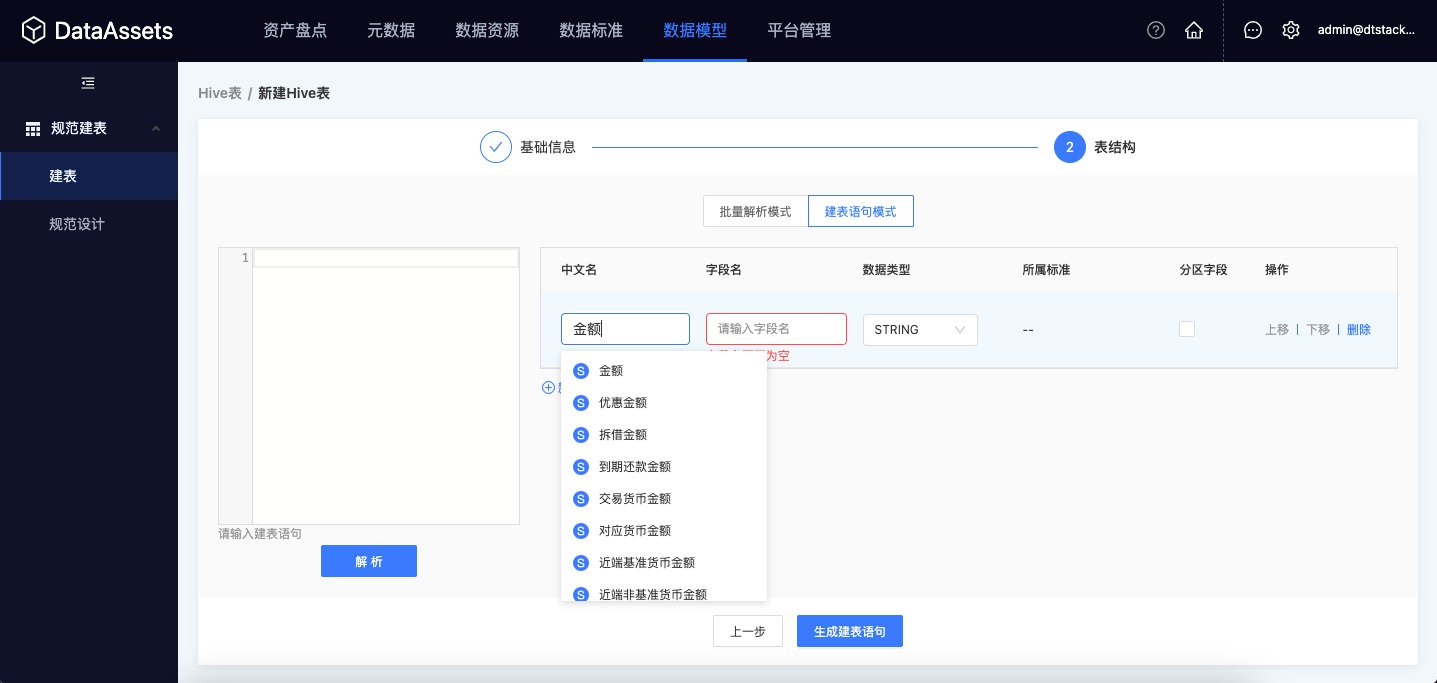
批量解析模式
在左侧输入框中批量输入字段中文名,点击「解析」按钮后,系统会将字段中文名与“数据标准”进行匹配。
1、如果“字段中文名”和“已发布的数据标准”完全匹配,则会自动引用数据标准的信息作为字段信息,完成表结构的创建,此类字段不允许二次修改。
2、如果“字段中文名”和“已发布的数据标准”没有匹配,则会对“字段中文名”进行分词处理,并将分词结果和“词根中文名”进行匹配,自动引用词根的信息作为字段信息,完成表结构的创建,此类字段可进行二次修改。
-
-
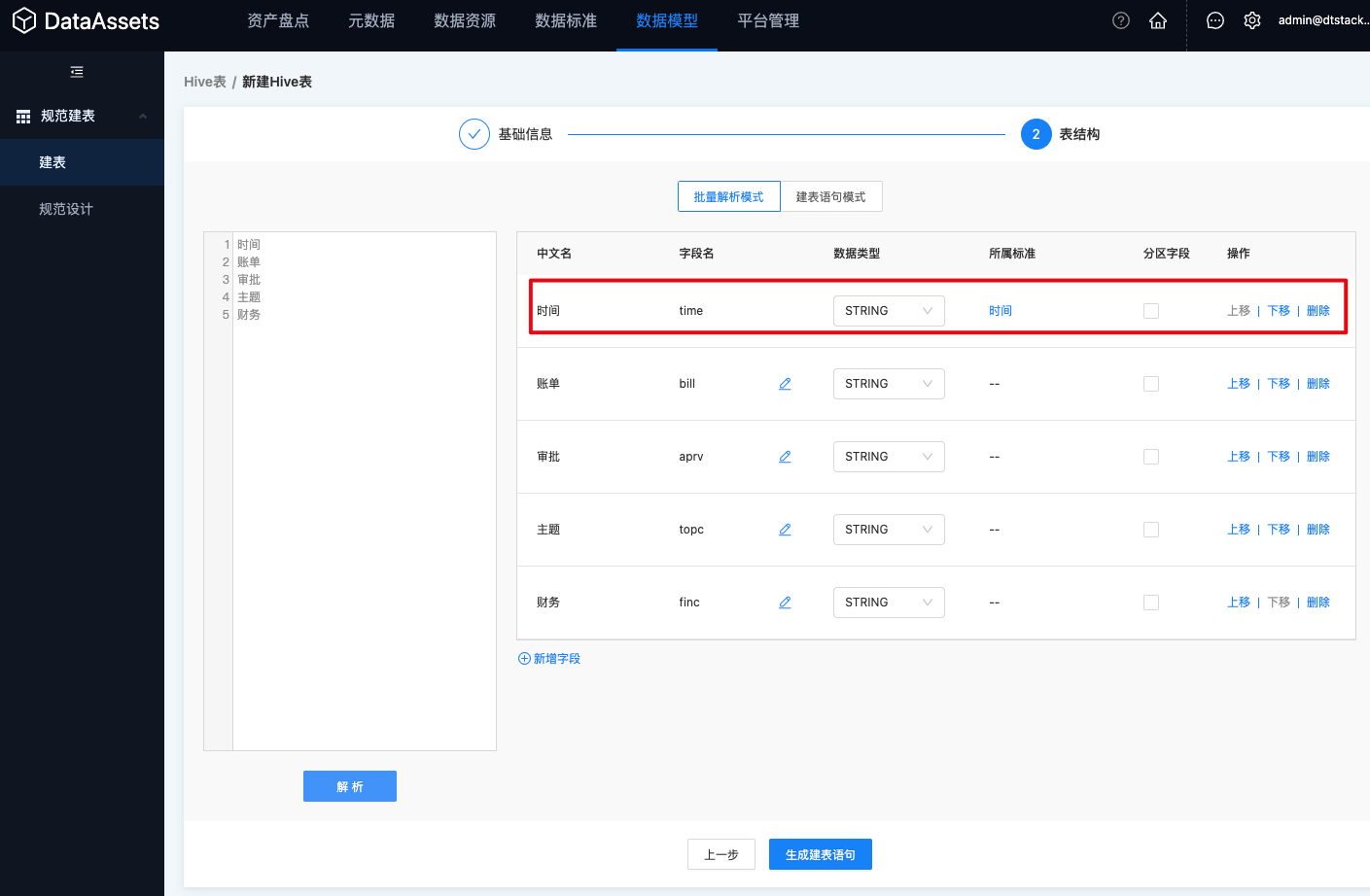
建表语句模式
如果开发人员更习惯传统的SQL模式,可以将编辑好的建表语句粘贴进输入框,点击「解析」按钮后,系统会自动将SQL语句中的“字段名”和“已发布的数据标准”进行匹配,匹配逻辑同【批量解析模式】。
该模式的目的是为了对建表语句在执行前进行一次检查,及时发现不符合规范的字段定义。
-
新增字段模式
在上诉两种模式的基础上,支持单独新增字段。在输入字段中文名的时候,下拉框中会实时匹配“已发布的数据标准”和“词根”。用户选择标准后,自动完成字段的新增。
Flink建表
需求背景
在实时开发平台,每次创建任务时都需要为该任务配置源表、维表、结果表等信息。但是在实时开发平台配置的Flink Table只能在一个任务中应用,无法复用至其他任务。即使配置信息相同,也需要在另一个任务开发页面重新配置。
基于这些问题,由数据资产平台实现Flink Table的管理服务。将创建的Flink Table沉淀为元数据服务,可在多个实时任务中重复引用,提高开发人员的工作效率。
|
如果同时部署了「实时开发平台」和「数据资产平台」,用户可在「实时开发平台」的源表/维表/结果表配置页面,选择「数据资产平台」中创建的Flink Table。 前提是用户拥有Flink Table的表权限,详见数据权限 |
功能介绍
-
数据库管理:维护Flink Table的数据库,其作用是对Flink Table进行分类管理。数据库不允许重名,并且无法删除存在表的数据库。
-
创建Flink Table:
-
映射Kafka
Step1:选择Topic
Step2:配置表信息,包括表的属性元数据和表结构。
属性元数据:会根据「元数据-元模型管理」中,为该数据库设计的元模型内容,显示对应的内容。
表结构:
1、系统随机解析一段json数据,将key值映射到「key」列,并自动填充至「字段名」。如涉及嵌套数据,用户需要手动修改字段名列内容,避免出现「xxx.xxx」的非法字段。
2、维护字段元数据,包括字段中文名、数据类型。
3、因为topic中的json数据结构可能各不相同,解析结果不一定正确。因此用户可以通过「添加映射字段」功能,手动维护topic key和对应字段的信息。
4、可能存在一个映射字段是有多个key加工计算得出,因此用户可以通过「添加自定义逻辑字段」功能,手动维护key列的加工逻辑和对应字段的信息。(常用于源表的EVENTTIME列,如下图)
-
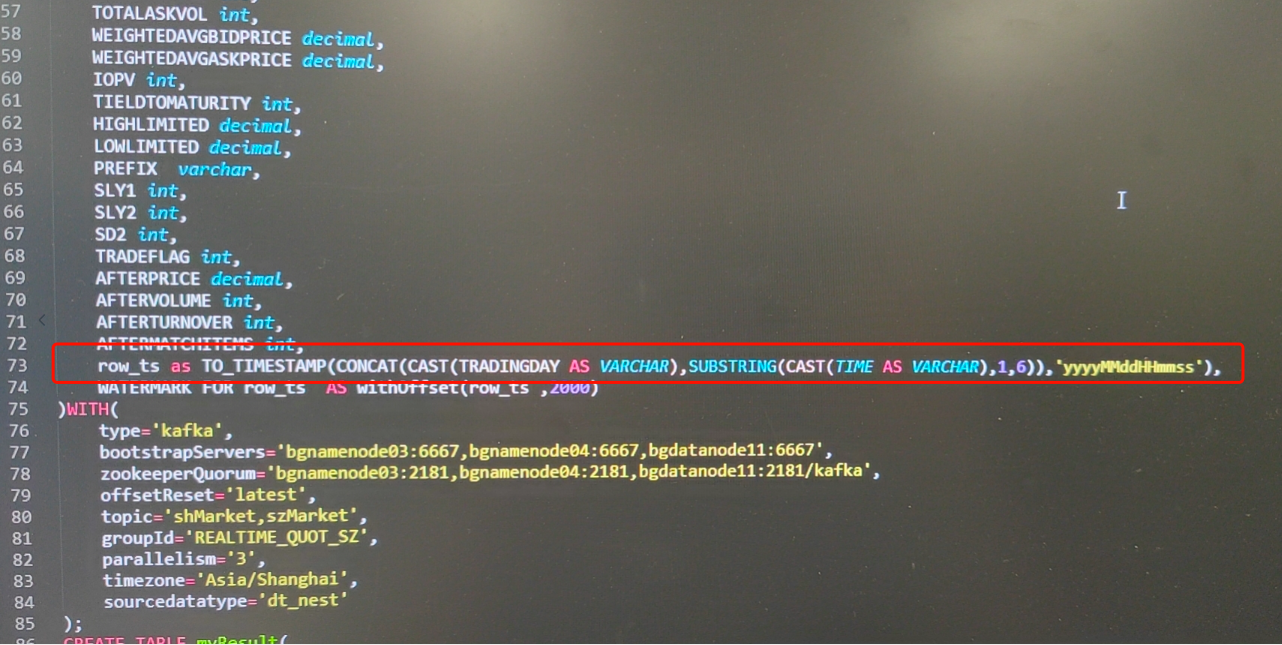
| 最终的表结构确认,在满足平台格式约束的前提下,需要用户自行保障正确性,否则会影响引用该表的实时平台任务的正常运行。 |
Step3:配置参数信息。Kafka映射表只能在实时任务被引用为源表和结果表,因此只需要维护这两项信息即可。配置项的详细说明可在产品页使用查看。
-
映射MySQL
Step1:选择表
Step2:配置表信息,包括表的属性元数据和表结构。
属性元数据:会根据「元数据-元模型管理」中,为该数据库设计的元模型内容,显示对应的内容。
表结构:系统解析源表结构,源表字段名即作为Flink Table字段名,只需要再维护字段中文和数据类型的元数据即可。
Step3:配置参数信息。MySQL映射表只能在实时任务被引用维表和结果表,因此只需要维护这两项信息即可。配置项的详细说明可在产品页使用查看。 -
映射Oracle
基础逻辑同「映射MySQL」