数据源管理
数据源连接
支持的类型
-
目前支持的数据源包括:Hive(1.x/2.x)、SparkThrift2.x、MySQL、Oracle、SQLServer、TiDB、HBase、Phoenix5.x、Vertica、Kafka(0.10/2.x)、自定义类型
-
Hive(1.x/2.x)、SparkThrift2.x、HBase、Phoenix5.x均支持开启kerberos认证
-
自定义类型:这类特殊的数据源,用户通过手动定义元数据结构,上传元数据文件,可实现线下非结构数据的元数据线上化管理
连接方式
-
各个数据源的连接方式会有些差异,大部分均可通过JDBC完成连接
-
第一次连接成功的数据源,默认会有个初始化的状态。该初始化过程会同步数据源中的库表名称元数据,为元数据采集提供目标选择
-
权限说明:为支撑平台需要采集的元数据内容,对不同数据源类型JDBC账号权限的诉求存在差异。JDBC账号至少需要包含如下权限,详见表格:
| 数据源类型 | 账号需要开通Select权限的表 |
|---|---|
Hive/SparkThrift |
- 需要同步的所有库表 |
MySQL |
- 需要同步的所有库表 |
Oracle |
- SYS.ALL_IND_COLUMNS |
SQLServer |
- SYS.TABLES |
TiDB |
- 需要同步的所有表 |
HBase |
- 需要同步的所有表 |
Phoenix5.x |
- SYSTEM.CATALOG |
Vertica |
- V_CATALOG.TABLES |
| 如需使用资产平台的「预览数据」功能,建议给数据源连接账号开通所有表的查询权限 |
数据库管理
-
点击数据源列表的操作按钮,选择数据库管理进入页面
-
数据库管理:
-
添加数据库:完成数据源连接后,再将需要同步元数据的数据库添加进来(仅限该数据源账号下有权限的数据库),否则执行元数据同步时无法找到目标
-
为什么需要这步操作?
-
在添加数据库的时候,可以维护数据库的元数据信息
-
数据源中部分系统数据库没有元数据采集的必要;部分敏感数据库不能开放元数据采集。
-
-
-
导入元数据:
-
对于该数据源或者数据库中的表,如果已经在线下维护过元数据信息,可以通过导入功能,将线下元数据导入线上
-
前提是在元数据管理中,为该数据源或者数据库维护了元模型,导入的元数据表头和元模型属性项匹配,才可完成导入
-
元数据同步
元数据同步
-
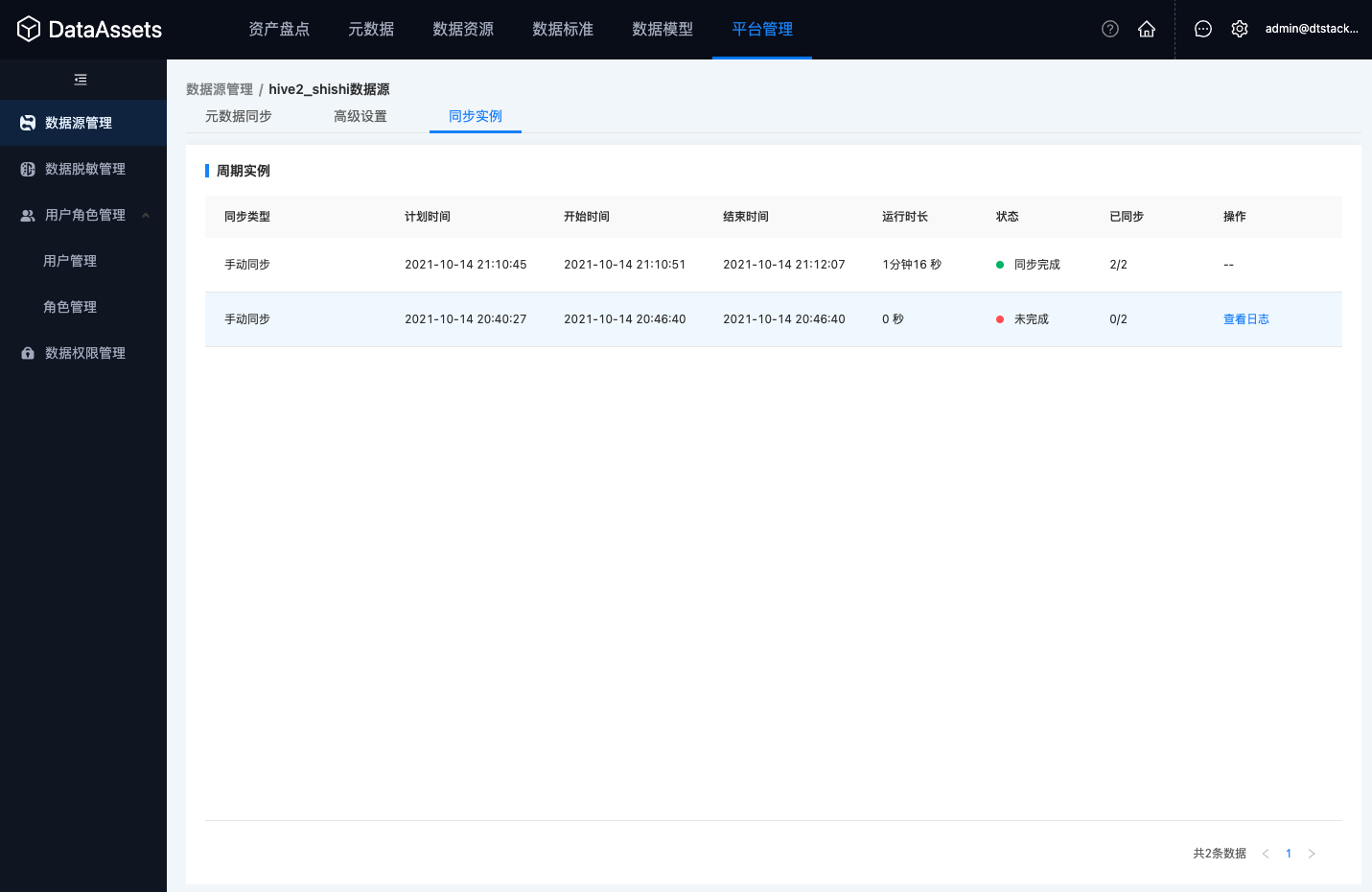
点击数据源列表的操作按钮,选择元数据同步进入页面
-
实现逻辑:通过数据源连接,利用预置的元数据查询SQL,从数据源获取元数据信息,并通过FlinkX引擎,将查询到的元数据同步至资产平台。常见Q&A如下:
-
Q1:同步性能怎么样,对源库有没有压力?
-
A1:元数据采集的数据量和数据采集相比是非常小的,因此性能压力方面不存在瓶颈问题。
-
Q2:为什么有些数据源需要开通所有表的查询权限才能采集元数据?
-
A2:部分元数据信息无法直接在元数据表中直接获取,需要遍历每张表。
-
Q3:元数据采集到底采集了哪些东西?
-
A3:每个数据源均有所差异,具体可查看各个数据源的「数据地图-基本信息」的技术属性和表结构信息
-
-
实现功能:
-
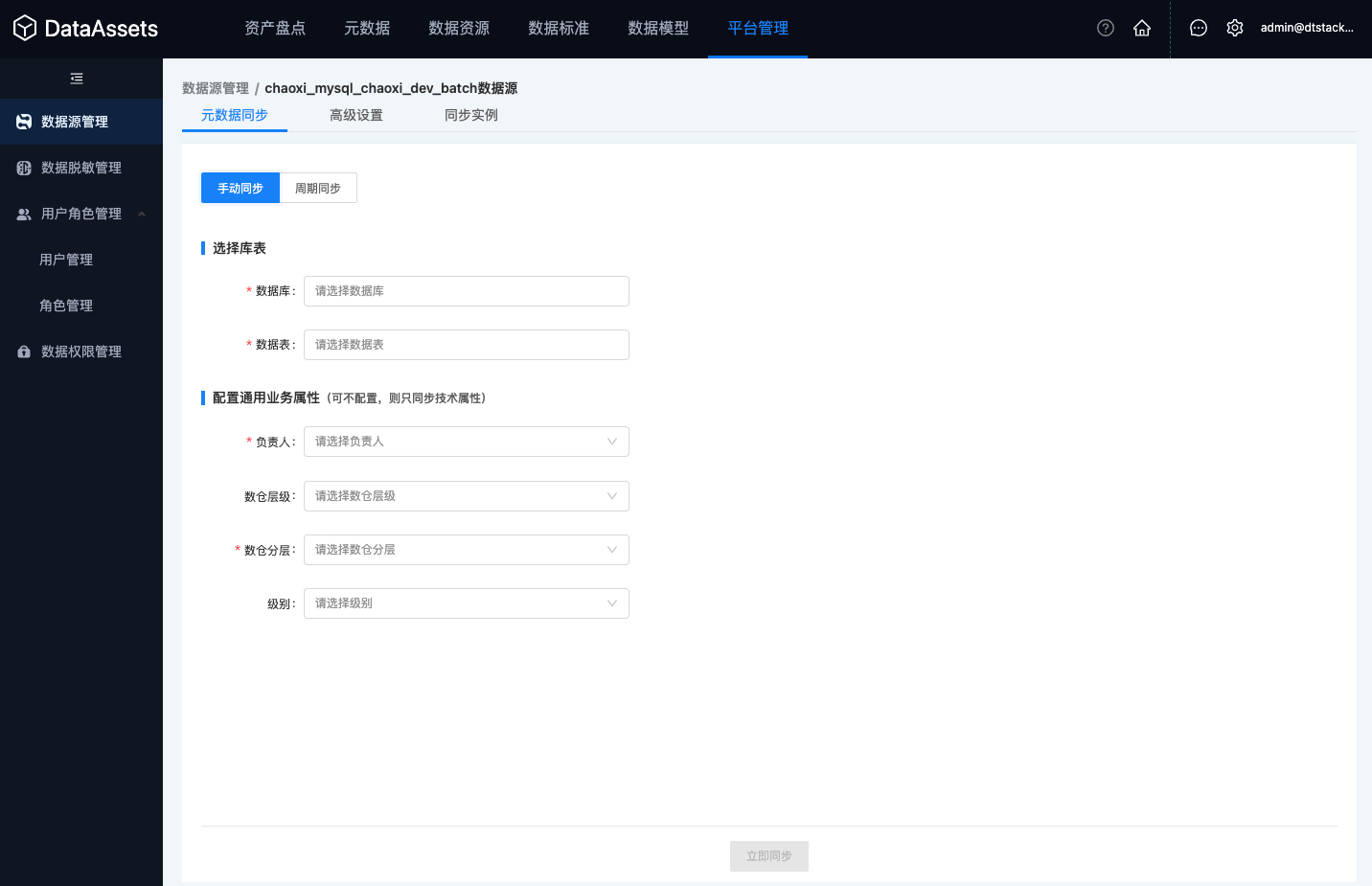
手动同步:指定库表,同步对应库表的元数据信息。
-
-
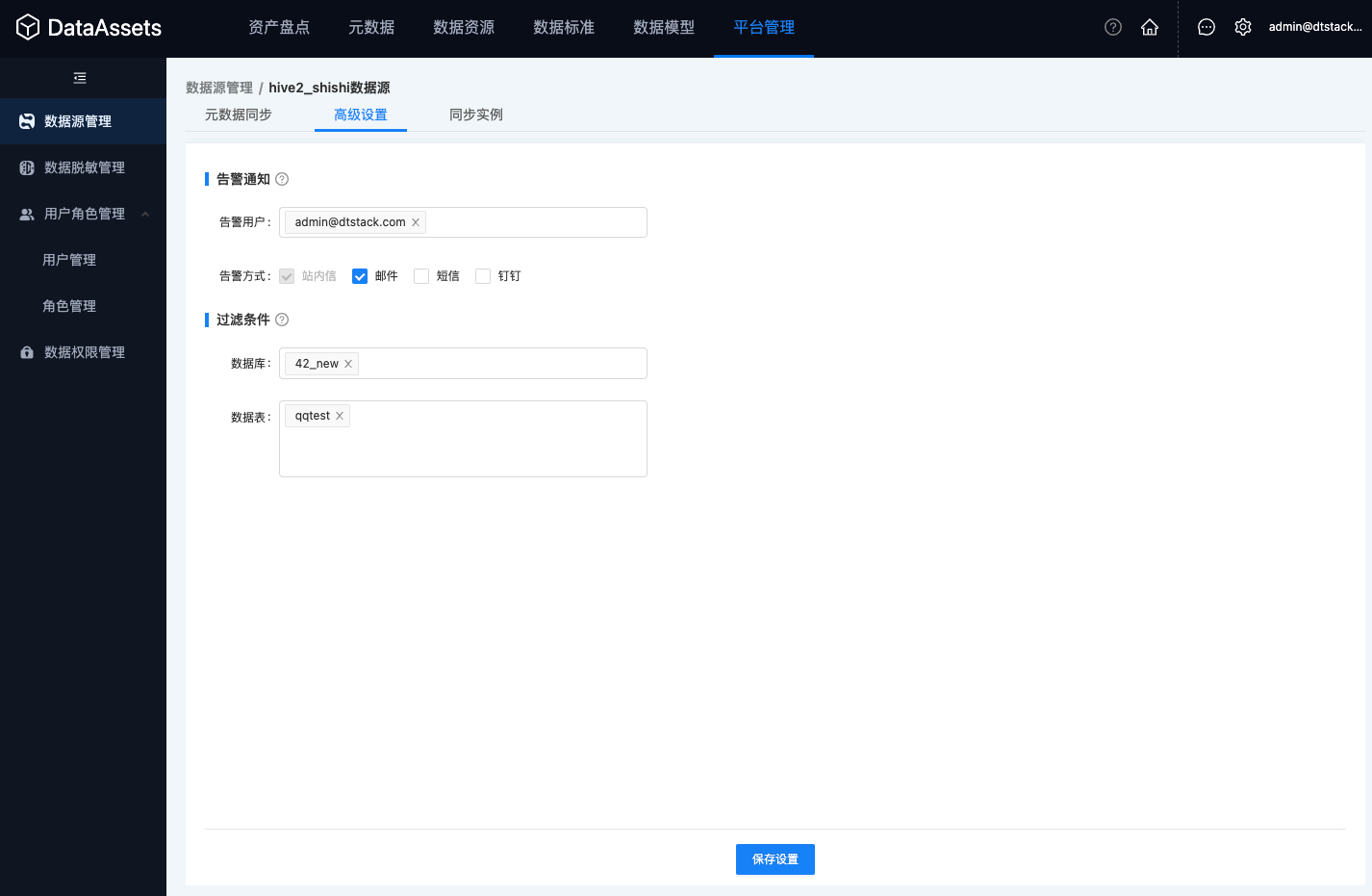
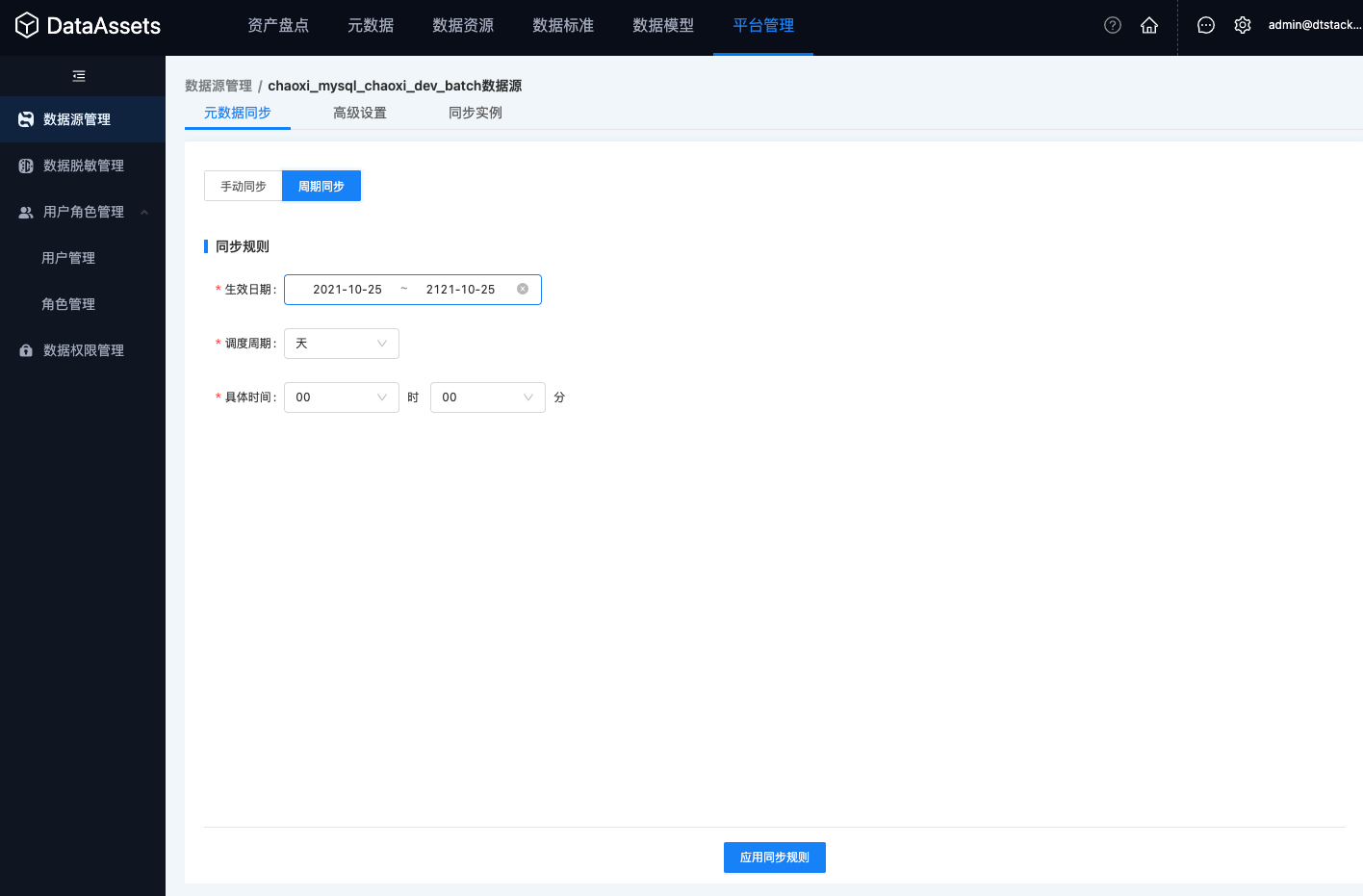
周期同步:配置同步周期和告警通知,系统定期自动同步该数据源中所有库表的元数据信息
· 同步周期:目前支持天、周、月的调度周期;
-
实时同步:开启实时同步后,当源库发生DDL操作时,资产平台会实时同步发生变更的表。
| 实时同步目前只支持“Hive2.x、SparkThrift2.x”数据源,并且对应的数据源连接信息需要在高可用配置中维护上hive.metastore.uris参数 |