整库同步
概述
整库同步是帮助提升用户效率、降低用户使用成本的一种快捷工具,本质上是一种批量配置同步任务的方式。假设数据库有100张表,原本可能需要配置100次数据同步任务,整库同步功能可以一次性完成100个同步任务的配置。
支持的数据源类型
目前可以支持的数据源包括:
-
MySQL
-
Polardb for MySQL 8
-
Oracle
-
SQLServer
-
PostgreSQL
-
DB2
-
达梦
-
Greenplum
-
TiDB
-
GBase 8a
-
ClickHouse
-
目前仅支持其他数据源至离线开发自带的Hive表配置整库同步,不能向其他Hive库,或其他类型的数据源配置整库同步
-
当离线开发自身的引擎连接了LibrA、Greenplum等非Hadoop的引擎时,也不支持向这些引擎配置整库同步
配置整库同步
配置整库同步的入口在「数据源」页面,在待同步的数据源点击「整库同步」按钮,进入整库同步页面。
整库同步的配置包括:
-
待同步表:将数据源指定的数据库下的所有表,以表格的形式展现出来,可以根据实际需要批量选择;
-
高级设置:
-
表名转换:可填写表名中原有的字符,替换后的字符,例如将
ab替换为ods_ab注意,表名替换中,目前会将表名所有匹配到的地方都做替换,例如表名为abc_ab_table,按以上规则,会被替换为ods_abc_ods_ab_table -
字段名转换:原理与表名转换类似,依然会存在同个字符可能会被多次替换的情况,例如配置字段名转换规则为
d->od,则MySQL中字段名address将会被转换为aododress -
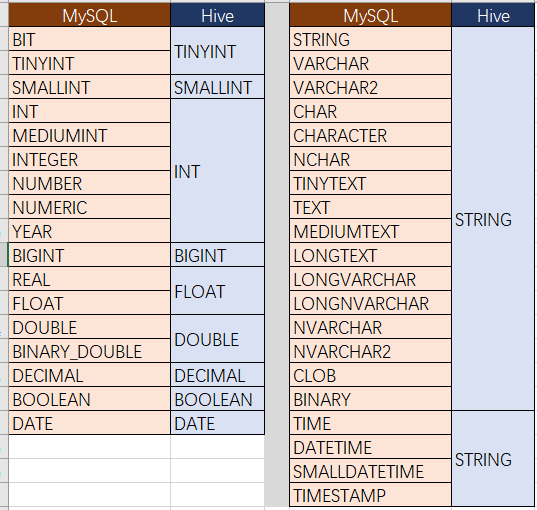
字段类型转换:源表的字段类型转换为Hive表的字段类型
-
| 高级设置中,目前尚不支持表名前统一加前缀等操作,需注意表名可能存在多次替换的问题 |
-
生效日期:整库同步生成的每个任务的生效日期
-
具体时间:整库同步生成的每个任务的具体时间
-
同步方式:
-
增量(根据日期字段):使用同步任务的「数据过滤」功能,根据用户填写的增量日期字段自动拼接SQL,抽取前一天的数据。使用增量方式后,系统将对每张表使用同样的增量字段,配合离线开发调度参数(${bdp.system.bizdate})形成针对每天的数据抽取条件,例如MySQL的拼接(用户点击「发布任务」按钮后,会先对增量字段进行检查,若字段不存在,则此表会配置失败):
-
-- MySQL
STR_TO_DATE('${bdp.system.bizdate}', '%Y%m%d') <= id
AND
id < DATE_ADD(STR_TO_DATE('${bdp.system.bizdate}', '%Y%m%d'), interval 1 day)| 配置增量抽取时,源库每张表的增量字段名需保持一致,若无法保持一致,可分批次分别配置,否则会导致SQL拼接失败 |
-
全量:不拼接增量抽取SQL,全量抽取各表的数据
-
并发配置:为了对数据源进行保护,避免同一时间点启动大量数据同步作业带来数据库压力过大,可选择分批上传,例如:从每日0点开始,每1小时启动3个数据库表同步
-
-
间隔时间:每隔xx小时同步多少张表
-
是否保存配置:保存配置后,可在「数据源-操作-同步历史」按钮中找到历史上配置过的整库同步任务与配置结果,系统仅保留最近5次的历史记录
-
发布任务进度:点击「发布任务」,系统将逐个生成同步任务,可在待同步表的「任务状态」一列查看每张表发布的结果,包括成功或失败信息
-
同步历史:同步历史的入口在「数据源-操作-同步历史」按钮,系统仅记录勾选了保存同步配置,否则不会保留历史记录
-
任务生成的步骤
整库同步批量生成任务,按照如下步骤进行处理,每个任务单独检查,其中部分失败不会影响其他任务的生成
其他说明
由于数据库的表设计规范性的问题,整库上传具有一定的约束性,具体如下:
仅提供每日增量、每日全量的上传方式
如果您需要一次性同步历史数据,则此功能无法满足您的需求,故给出以下建议:
-
建议您配置为每日任务,而非一次性同步历史数据。您可以通过调度提供的补数据来对历史数据进行追溯(从虚节点及其下游开始补数据),这样可避免全量同步历史数据后,还需要做临时的SQL任务来拆分数据。
-
如果您需要一次性同步历史数据,可以在任务开发页面进行任务的配置,然后单击运行,完成后通过SQL语句进行数据的转换,因为这两个操作均为一次性行为。
-
如果您每日增量上传有特殊业务逻辑,而非一个单纯的日期字段可以标识增量,则此功能无法满足您的需求,为了更方便地增量上传,建议您在创建所有数据库表的时候都有:gmt_create或gmt_modify的字段,同时为了效率更高,建议增加id为主键。
整库上传提供分批和整批上传的方式
-
为了保障对数据库的压力负载,整库上传提供了分批上传的方式,您可以按照时间间隔把表拆分为几批运行,避免对数据库的负载过大,影响正常的业务能力。以下有两点建议:
-
如果您有主、备库,建议同步任务全部同步备库数据。
-
批量任务中每张表都会有1个数据库连接,上限速度为1M/s。如果您同时运行100张表的同步任务,就会有100个数据库进行连接,建议您根据自己的业务情况谨慎选择并发数。
-
-
如果您对任务传输效率有自己特定的要求,此功能无法实现您的需求。所有生成任务的上限速度均为 1M/s。