同步任务配置
新建任务
同步任务的创建入口在「数据开发->新建任务」,选择数据同步类型,之后还需选择「配置模式」和「同步模式」
配置模式
离线开发支持以向导模式或脚本模式进行同步任务的配置,向导模式的特点是便捷、简单,可视化字段映射,快速完成同步任务配置,但对部分数据源(例如Redis、ElasticSearch)不支持,而脚本模式的特点是全能、高效,可深度调优,支持全部数据源。
| 若选择了向导模式,可修改为脚本模式,如果选择了脚本模式,无法转换为向导模式 |
在脚本模式下,可以在编辑区左上角点击「导入模板」,并选择数据源类型、数据库等信息,确定后即可导入脚本模板,后续可在模板的基础上继续编辑即可。
| 导入模板后,之前填写的信息会被清空并覆盖 |
脚本模式的详细介绍请参考: FlinkX基本情况介绍
脚本模式的编辑中可能需要填写数栈自身的表所在的Hadoop路径信息(Location),您可以通过在SQL脚本中输入 DESC FORMATTED tableName 命令来获取其路径,详情请参考 获取表在Hadoop中的路径
同步模式
标识本任务是否采用增量模式,无增量标识:可通过简单的过滤语句实现增量同步;有增量标识:系统根据源表中的增量标识字段值,记录每次同步的点位,执行时可从上次点位继续同步,关于增量同步可参考:增量同步
任务配置
数据同步任务的配置共分为5个步骤:
-
选择数据来源:选择已配置的数据源,系统会读取其中的数据;
-
选择数据目标:选择已配置的数据源,系统会向其写入数据;
-
字段映射:配置数据来源与数据目标之间的字段映射关系,不同的数据类型在这步有不同的配置方法;
-
通道控制:控制数据同步的执行速度、错误数据的处理方式等;
-
预览保存:再次确认已配置的规则并保存。
数据源/目标配置
关系型与MPP型数据库
关系型数据库与MPP数据库涵盖以下数据源:
MySQL、Oracle、SQLServer、PostgreSQL、DB2、达梦(DMDB)、PolarDB for MySQL、Greenplum、GaussDB、GBase 8a、TiDB
Reader
关系型数据库或MPP型数据库作为数据源,需配置以下信息:
-
数据源
-
表
-
数据过滤:针对源头数据筛选条件,根据指定的column、table、where条件拼接SQL进行数据抽取,暂时不支持limit关键字过滤。利用where条件可进行增量同步,具体说明如下:
增量导入在实际业务场景中,往往会选择当天的数据进行同步,通常需要编写where条件语句,需先确认表中描述增量字段(时间戳)为哪一个。如tableA增量的字段为create_time,则填写create_time>需要的日期,如果需要日期动态变化,可以填写${bdp.system.bizdate}、${bdp.system.cyctime}
等调度参数,关于调度参数的详细信息请参考 参数配置。 -
切分键:离线开发在进行数据抽取时,如果指定切分键,系统可以使用切分键的字段进行数据分片,数据同步因此会启动并发任务进行数据同步,这样可以大大提供数据同步的效能。
-
推荐将表的主键作为切分键,因为表主键通常情况下比较均匀,因此切分出来的分片也不容易出现数据热点。
-
目前离线开发目前支持MySQL、Oracle、SQLServer、PostgreSQL、DB2、GBase 8a、达梦、PolarDB for MySQL8、Phoenix、Greenplum,仅支持数值型字段作为切分键,不支持字符串、浮点、日期等其他类型。如果指定了不支持的类型,则忽略切分键功能,使用单通道进行同步
-
如果在第四步的「作业并发数」大于1但是没有配置切分键,任务将置为失败
-
如果不填写切分键,数据同步视作使用单通道同步该表数据
-
切分键的配置需要与第四步的
通道控制联合使用,下面是典型的应用场景: 假设MySQL的tableA表中,有一个INT类型的字段名为id的主键,那么可以在切分键输入框中输入id字段,并在第四步的"`作业并发数`"中配置为5,则系统会产生5个并发线程同时读取MySQL表,每个任务会根据id字段的值进行数据切分,保证5个并发线程读取的数据是不同的,通过以上机制即可以加速数据读取的速度。
-
-
高级配置:特定场景下,无法满足需求时,支持以JSON的形式传入其他参数,例如fetchSize等。
| 关系型数据库设置作业速率上限和切分键才能根据作业速率上限将表进行切分,只支持数值型作为切分键 |
Oracle读取/写入其他Schema下的表
| Oracle通过用户名来标识Schema,如果需要同步其他Schema下的数据,则不能在下拉列表中选择表,而是直接输入schemaName.tableName,可读取/写入其他Schema的数据 |
Writer
关系型数据库作为数据目标,需配置以下信息:
-
数据同步目标库;
-
目标表;
-
导入前、导入后准备语句:执行数据同步任务之前率先执行的SQL语句。目前向导模式只允许执行一条SQL语句,例如:
truncate table。 -
主键冲突的处理:
-
insert into:当主键/唯一性索引冲突时会写不进去冲突的行,以脏数据的形式体现,脏数据的配置与管理请参考 脏数据管理;
-
replace into:没有遇到主键/唯一性索引冲突时,与insert into行为一致,冲突时,先delete再insert,未映射的字段会被映射为NULL;
-
on duplicate key update:当主键/约束冲突,update数据,未映射的字段值不变;
-
字段映射
请参考字段映射的通用功能
MySQL分库分表
|
目前分库分表模式仅支持MySQL数据源,其他数据源暂不支持 mysql分库分表实际是把表结构完全相同的多张表同步到一张目标表里。所以在数据预览的时候只默认显示第一张表的数据样例。所有数据同步任务都实际只支持单张表的同步(MySQL分库分表是特殊),不存在多张表同步到多张表的同步功能。 |
同一个同步任务,可以同时并发(或串行)读取多个库、多个表,适用于业务库采用了分库分表的情况下,配置方式比较简单,仅需在同一个同步任务中添加多个库、多个表即可。
在页面上勾选「批量选择」,还可以支持按表名搜索、批量选中等操作,便于对大量表配置数据同步。
分库分表的一些限制条件:
-
选中的库、表,表结构需要保持一致(字段名、字段类型),系统不会进行检查,表结构的一致性由用户保证;
-
若MySQL采用分库模式,则不同的数据库需配置不同的数据源,需要在「数据源」模块单独配置;
-
若配置了并发度,则每个并发会分别读取一张表的数据;
| 仅支持MySQL分库分表数据的读取,不支持写入 |
| Batcworks仅支持关系型数据库的普通数据类型,暂时不支持blob、clob、地理空间等特殊类型的数据读/写 |
Hive1.x / Hive 2.x
-
Hive1.x与Hive2.x的配置是基本相同的,详情请参考 Hive1.x与Hive2.x的区别
-
Hive1.x与Hive2.x仅支持Textfile、ORC、Parquet 这3种数据格式,同步的原理请参考 FlinkX读写Hive表的原理
Reader
-
分区:当Hive表作为数据源时,可读取某个分区下的数据:
-
分区填写栏支持填写参数,支持的参数请参考 参数配置
-
非分区表,不用填写;
-
一级分区表,不填写分区,则会读取所有分区数据;填写了分区名(例如
pt = '20200503'),则只读取指定分区的数据; -
多级分区表,可以填写多级分区形式(例如
ptd='20200503' /pdh='120000'),多级分区表,如果只填写一级分区信息(例如ptd='20200503'),则会将下属的所有二级分区数据全部读取;
-
Writer
-
分区:当Hive表作为写入目标时,可将数据写入某个分区:
-
分区填写栏支持填写参数,支持的参数请参考 参数配置
-
动态分区机制:当写入的分区名不存在时,系统按用户指定的分区名自动创建
-
对于非分区表,无需填写;
-
一级分区表,必须填写(例如
pt = '20200503') -
多级分区表,必须填写至最末一级分区(例如
ptd='20200503' /pdh='120000')
-
-
写入模式:
-
insert overwrite:写入前将清理已存在的数据文件,之后执行写入(默认值);
-
insert into:写入前已有的数据不会删除,系统会写入的新的文件;
-
| 不支持路由写入,对于分区表请务必保证写入数据到最末一级分区(HDFS上一个确定的目录) |
字段映射
请参考字段映射的通用功能
Maxcompute
| MaxCompute Reader不支持数据过滤功能。如果您在数据同步过程中,需要过滤符合条件的数据,请创建新表并写入过滤数据后,同步新表中的数据。 MaxCompute Reader不支持同步外部表。 |
Reader
分区:当Maxcompute表作为数据源时,可读取某个分区下的数据:
-
分区填写栏支持填写参数,支持的参数请参考 参数配置
-
非分区表,不用填写
-
一级分区表,不填写分区,则会读取所有分区数据;填写了分区名(例如 pt = '20200503' ),则只读取指定分区的数据;
-
多级分区表,可以填写多级分区形式(例如 ptd='20200503' /pdh='120000'),多级分区表,如果只填写一级分区信息(例如 ptd='20200503'),则会将下属的所有二级分区数据全部读取;
Writer-
写入模式:
-
-
insert overwrite:写入前将清理已存在的数据文件,之后执行写入(默认值);
-
insert into:写入前已有的数据不会删除,系统会写入的新的文件;
HDFS
| 离线开发支持读取/写入HDFS数据源内的数据,但仅支持半结构化数据,其中必须存储CSV或文本格式,且其中的内容必须按照二维表的结构存储,不建议使用此功能进行图像、视频等非结构化数据同步 |
Reader
-
路径:待读取的HDFS文件路径,例如
/user/hive/myTable/如果最后以一个路径,而不是文件名结尾,则会读取这个路径下的所有文件。如果以文件名结尾(例如/user/hive/myTable/a.csv),则只读取指定的文件。若要读取的文件路径,多个路径可以用逗号隔开。 -
分隔符:默认为
\001,支持填写可见字符,例如,,同时支持通过\做转义配置不可见字符,例如,填写可见字符时,只支持1个字符。转义字符需根据8进制ASCII编码填写对应的值,例如\044表示$ -
文件类型:
-
Textfile类型
-
列分隔符:当文件类型为textfile时,需要填写列分隔符,只能填写1个字符(默认值\001)。
-
编码:仅支持UTF-8或GBK,暂不支持其他字符。
-
-
ORC类型、Parquet类型,无需配置分隔符、编码等信息。
-
Writer
-
路径:待写入的HDFS文件路径,例如
/user/hive/myTable,Writer会根据并发配置在目录下写入多个文件。写入HDFS时,文件名是随机生成的,暂时不支持指定文件名。 -
文件类型:
-
Textfile类型
-
列分隔符:当文件类型为textfile时,需要填写列分隔符,默认为
\001,支持填写可见字符,例如,填写可见字符时,只支持1个字符。同时支持通过\做转义配置不可见字符,例如\001。转义字符需根据8进制ASCII编码填写对应的值,例如\044表示$。 -
编码:仅支持UTF-8或GBK,暂不支持其他字符。
-
-
ORC类型、Parquet类型,分隔符、编码信息是无效的。
-
| 写入HDFS时,文件名是随机生成的,暂时不支持指定文件名 |
| 写入时的字段分隔符,需要用户保证与创建的Hive表的字段分隔符一致,否则无法在Hive表中查到数据 |
字段映射
HDFS字段映射的功能,已字段映射的通用功能为基础,除此之外,当HDFS作为源或者目标时,还支持其他配置方式:
-
添加单个字段:点击后在弹窗中补充索引值和字段类型。
-
索引值:表示读取/写入文件中的字段序号,从0开始,不可重复
-
字段类型:建议填写string类型,字段类型不区分大小写。由于HDFS是无类型的存储系统,建议采用string类型,同步过程中不易出错
-
-
文本模式:添加单个字段较为繁琐,也可以采用文本模式,批量编辑字段信息,点击「文本模式」,在弹窗中批量编辑。批量编辑的语法格式为:
index:type,每行一个字段,每一行填写索引值、英文冒号、类型,且以英文逗号结尾,注意最后一行也要以英文逗号结尾 -
添加或删除字段后,可点击每个字段后面的「删除」icon,删除此字段。新添加的字段都会排在最后,若误删除中间的字段,可用文本模式重新添加在中间位置
-
拷贝源字段/目标字段:当数据源、目标为FTP、HDFS等无类型的数据源,且另一半为有类型的数据源时,可点击「拷贝源字段」或「拷贝目标字段」来快速复制有类型的一方,降低批量配置的工作量
FTP
Reader
-
路径:
-
单个文件:
-
读取FTP路径下的单个文件时,需要在「路径」框中填写路径+指定的文件名(含扩展名),例如:/data/shier/muyun/singleFile.csv 系统将读取指定的文件,注意,路径、文件名区分大小写。
-
单路径下多个文件:
BathWorks支持读取FTP某个路径下的多个文件,需要在「路径」框中不指定具体文件,例如:
/data/multiFile .../largeFile_20200613_part1.csv .../largeFile_20200613_part2.csv
在这种场景下,可在「路径」框中填写为:/data/multiFile/,(注意,在路径最后写上/,在正则匹配预览中可以明确预览待读取的文件)即可读取此路径下的2个文件
| 单个路径下读取多个文件,由用户保证这些文件结构的一致性,若不同文件结构不一致,则会导致不可预料的风险 |
若勾选了「编码」、「列分隔符」、「是否包含表头」等选项,这些配置对每个文件都生效。例如勾选了「包含表头」,则将每个文件的第一行均视作表头。
-
路径的正则匹配:支持按照正则的方式批量匹配读取的文件:
/largeFile_20200613_part1.csv /largeFile_20200613_part2.csv /smallFile_20200613_wieieiweiekdkkd29e.csv /smallFile_20200613_kskdoskdsnkf2023e.csv
只需要读取以 smallFile_20200613_ 开头,任意字符结尾的文件,「路径」框填写: /smallFile_20200613_.* ,其中 .* 表示匹配任意字符
正则匹配只对文件名起效,对路径不起效,当指定的正则表达式中既包含路径,又包含文件时,只能匹配到文件,例如:
/data/abc.csv
/data/abc
.../fileName1.csv
.../fileName2.csv
在「路径」框中填写 /data/ab.* ,只能匹配到 /data/abc.csv 文件,不能匹配到 /data/abc/ 下属的文件及目录
正则匹配的几种常见写法:
* 匹配任意字符:.*
* 以…开头:^
* 以…结尾:$
* 正则转义字符:/
-
路径中的系统变量:
「路径」栏支持填写系统变量,可支持的系统变量、自定义变量需参考: 参数配置
假设当前日期为2020年6月14日,FTP中对应今天的路径为:
/data/202006/20200613/fileName......
「路径」中应填写为:/data/${bdp.system.currmonth}/${bdp.system.bizdate}/fileName......
-
多个路径
多路径同步与单个路径是相同的,同样支持正则表达式、系统变量,不再赘述。
-
列分隔符:
默认为英文逗号 , 注意,填写可见字符时只支持1个字符。支持配置不可见字符,需通过 \ 做转义字符,例如 \001 。转义字符需根据8进制ASCII编码填写对应的值,例如 \044 表示 $
| 列分隔符只支持单个字符 |
-
编码:
支持UTF-8和GBK 2种编码格式
-
是否包含表头:
选择是、否
| FTP读取、写入文件时,路径、文件名等信息均区分大小写 |
Writer
-
路径:写入FTP的目录地址,注意必须指定到目录,以
/结束 -
文件名称;
-
临时文件扩展名:当系统写入文件时,会写入一个临时目录,并写入临时文件,支持指定临时文件的扩展名
-
编码:支持UTF-8或GBK,默认为UTF-8
-
列分隔符:默认为英文逗号,与Reader中的列分隔符相同
-
写入模式:支持覆盖或追加
字段映射
FTP字段映射功能与HDFS十分类似,请参考HDFS
Impala
| 当Impala表为Textfile、ORC或者Parquet格式时,使用方式与普通Hive表类似,可参考Hive表配置。 |
Reader
若为Impala+Kudu的形式,仅需选择数据源和表即可,无需配置读取的分区信息。
Writer
若为Impala+Kudu的形式,不能指定具体分区,需补充写入模式。
-
写入模式:
-
Insert:写入
-
update:更新
-
upsert:若主键在表中已经存在,则执行update语义,反之,执行insert。
-
-
flushMode:kudu session刷新模式,
-
auto_flush_sync(默认值):同步刷新模式,客户端会等数据刷新到服务器后再返回,这种情况就不能批量插入数据
-
auto_flush_background:异步刷新模式,客户端会立即返回,但是写入将在后台发送,可能与来自同一会话的其他写入一起进行批处理。
-
manual_flush:手动刷新模式。
-
| flushMode参数不支持页面修改,需在脚本模式中修改 |
字段映射
请参考字段映射的通用功能
Kudu
参考Impala一节的描述
Clickhouse
Reader
-
数据过滤:您将要同步数据的筛选条件,暂时不支持limit关键字过滤。SQL语法与选择的数据源一致。 where条件可以有效地进行业务增量同步。如果不填写where语句,数据同步均视作同步全量数据。
-
切分键:可以将源数据表中某一列作为切分键,建议使用主键或有索引的列作为切分键,仅支持类型为整型的字段。 读取数据时,根据配置的字段进行数据分片,实现并发读取,可以提升数据同步效率。
Writer
-
导入前准备语句:写入数据至目标表前,会先执行此处的标准语句。
-
导入后准备语句:写入数据至目标表后,会执行此处的标准语句。
-
写入模式:写入前已有的数据不会删除,系统会写入的新的文件。
HBase
Reader
-
startRowkey:指定开始rowkey;
-
endRowkey:指定结束rowkey;
-
isBinaryRowkey:指定配置的startRowkey和endRowkey转换为byte[]时的方式,默认值为false,若为true,则调用Bytes.toBytesBinary(rowkey方法进行转换;若为false:则调用Bytes.toBytes(rowkey
Writer
-
读取为null值时的处理方式:
-
skip:表示不向hbase写这列;
-
empty:写入HConstants.EMPTY_BYTE_ARRAY,即new byte [0]
-
字段映射
HBase的字段映射在 字段映射的通用功能的基础上,多了构造rowkey的参数的配置,离线开发支持字符串拼接或取md5函数的方式构造rowkey。
-
rowkey:
-
目前仅支持从HBase结果表中进行rowkey的拼接,暂不支持从源表中取值进行拼接,因此在写入HBase时,组成rowkey元素的字段信息必须来自结果表字段;
-
编写格式,
$(colFamily:colName分别表示列族:列名,中间为英文冒号隔开 -
字符串拼接写法,例如:
$(cf_user:name_$(cf_mrkt:dist,取HBase结果表的cf_user:name和cf_mrkt:dist拼接后作为rowkey值;下划线_也可以替换为其他一个或多个字符,系统仅识别$(的参数 -
md5(函数:使用时,必须以在文本框中以md5开头,支持多字段拼接,例如:
md5($(cf_user:name_$(cf_mrkt:dist
-
ElasticSearch
ElasticSearch暂时不支持向导模式配置,只能通过JSON脚本模式配置,请参考脚本配置
MongoDB
MongoDB暂时不支持向导模式配置,只能通过JSON脚本模式配置,请参考脚本配置
Redis
Redis暂时不支持向导模式配置,只能通过JSON脚本模式配置,且Redis目前仅支持写入,不支持读取,请参考脚本配置
一键生成目标表
在数据同步任务中,若需要将数据同步至一张新表,可点击表名右侧的「一键生成目标表」按钮
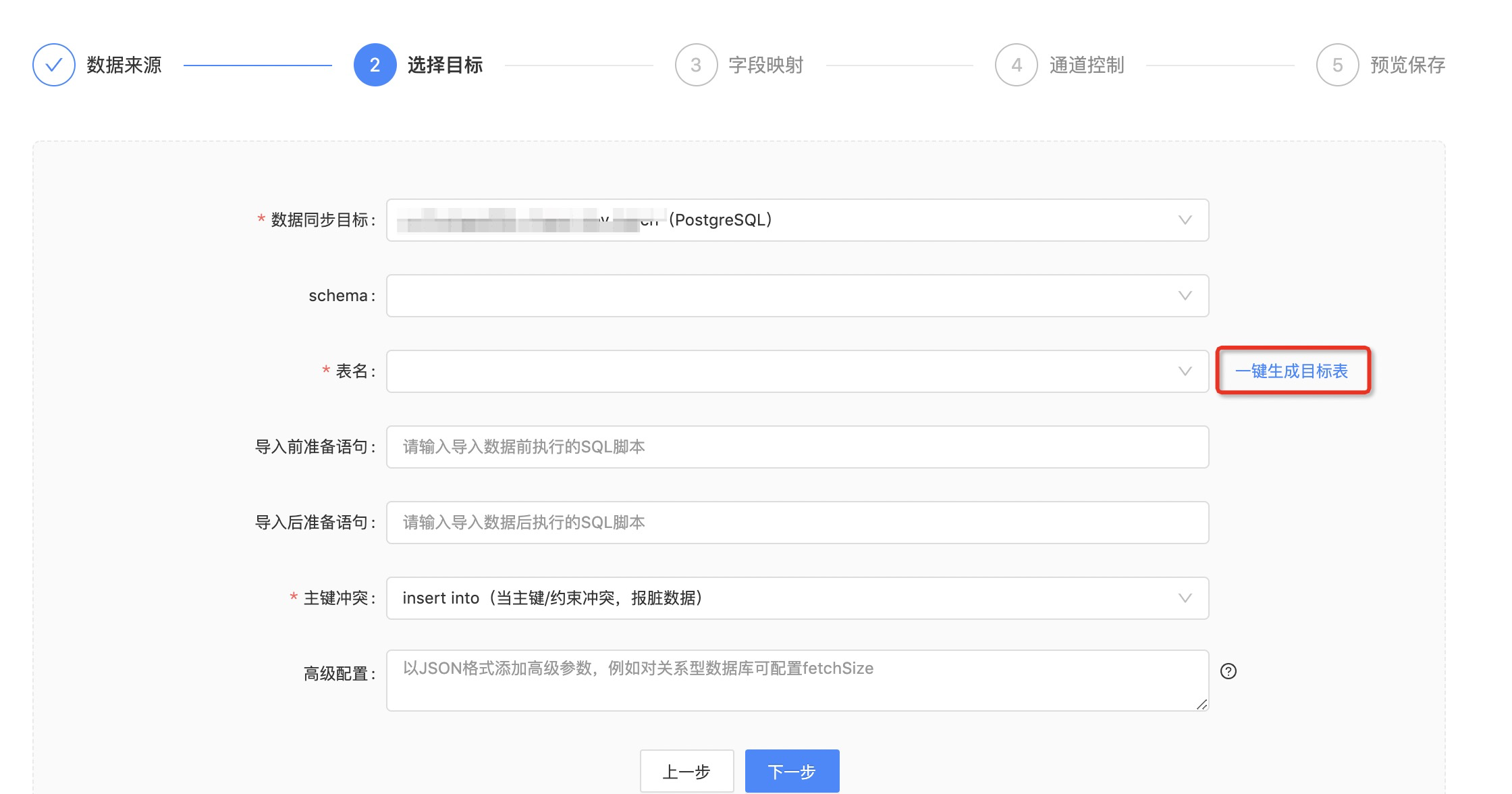
图1.1
“一键生成目标表”功能仅在源表和目标表为表1.1中的类型时存在。
表1.1
| 源表类型 | 目标表类型 |
|---|---|
关系型数据库: 大数据存储: 分析型数据库: MPP数据库: |
关系型数据库: 分析型数据库: MPP数据库: |
“一键生成目标表”中来源表字段类型与生成的目标表字段映射关系如表1.2;
数据来源表类型未做限制,仅对目标表数据源类型做限制,不同数据源类型对应不同字段映射关系如表1.2。
表1.2
源表字段类型 |
目标表字段类型 |
||
Hive及其他 |
GaussDB、Greenplum、PostgreSQL |
Tidb、MySQL |
|
DECIMAL |
DECIMAL 若无精度,默认为(15,0 |
||
INT(数字长度>11位 |
BIGINT |
||
类型中包含 unsigned |
BIGINT |
||
INT UNSIGNED |
INT |
||
UINT8、UINT16、INT8、INT16、INT32 |
INT |
||
UINT32、UINT64、INT64 |
BIGINT |
||
FLOAT32 |
FLOAT |
||
FLOAT64 |
DOUBLE |
||
DOUBLE |
- - |
DOUBLE PRECISION |
- - |
String |
- - |
- - |
varchar(255 |
number(15,5 |
若小数位精度为0,则转为BIGINT,否则转为DOUBLE |
若小数位精度为0,则转为BIGINT,否则转为DOUBLE PRECISION |
若小数位精度为0,则转为BIGINT,否则转为DOUBLE |
特殊:
| 源表字段类型 | 目标表字段类型 |
|---|---|
本单元格需要与上方单元格合并(本行字可删除) |
目标表类型:AnalyticDB PostgreSQL |
任何类型 |
varchar |
点击一键生成目标表出现如图,弹窗中的建表语句可直接修改。
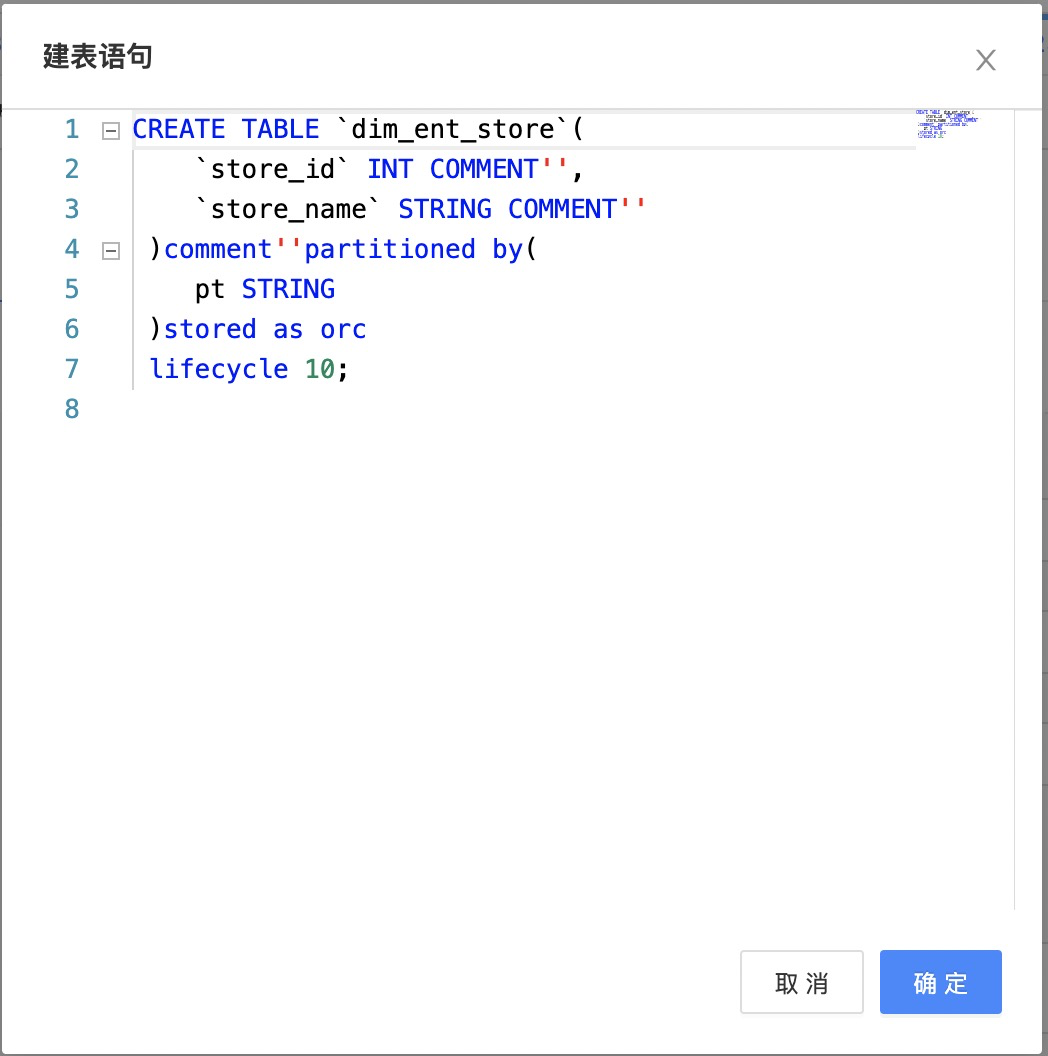
| 请注意检查建表语句中的字段类型:来源表和目标表的字段类型若不匹配可能导致产生脏数据或同步失败。 |
点击确定后,若建表成功,则会自动将新建的表的表名填充至“表名”文本框中。
字段映射
在支持向导模式配置的数据源中,均需要配置字段映射,标识源表与目标表之间每个字段的映射关系。离线开发仅支持「基本功能」中的format转换,不支持其他类型的数据转换功能,不建议在数据传输过程中进行过多的转换,而是在落盘后再转换
基本功能
离线开发所支持的任意数据源、目标之间,字段映射模块支持以下基本功能:
-
支持选择部分字段进行读取/写入。
-
format处理:数据源为字符串类型的字段,若存储了日期数据,且映射到目标库的date或time等时间类型,支持指定format格式,例如
"yyyy-MM-dd hh:mm:ss,若不配置此转换规则,则此数据可能被认为是脏数据。format处理支持Java格式化时间的标准格式,可参考 SimpleDateFormat。 -
支持在数据源一侧添加常量/系统变量作为虚拟字段值,请参考虚拟字段。
| 在配置字段映射时,建议检查源表、目标表之间的字段类型映射关系,建议将目标表的字段类型统一设置为string,并在下游数据加工任务中进行类型转换,提高数据同步环节的可靠性,尤其是写入Hive表 |
连线映射
在源表和目标表的字段之间连线,标识对应的2个字段的映射关系,离线开发目前仅支持一一映射,不支持一对多,或多对一映射。虽然可以手动连线,但建议用户采用同名映射或同行映射,便于快速配置。
同名与同行映射
按照字段名,或者左右两侧的字段序号进行映射匹配,再次点击可取消映射关系。
虚拟字段
支持在数据源端增加虚拟字段,作为附加信息写入到目标端
| 虚拟字段必须被映射至结果表,否则不会生效 |
常量字段
当需要添加某个常量信息至结果表时,可使用虚拟字段的常量字段功能,点击「添加常量」按钮,在弹窗中的「常量值」文本框中输入,例如 shanghai(注意无需输入引号),则此字符串常量将会被写入目标端的指定字段
变量字段
这里的变量字段指的是系统的调度参数,点击「添加常量」按钮,在「常量值」文本框中输入系统变量(变量名称需单独填写),例如${bdp.system.bizdate},则系统将根据周期调度中系统变量的取值作为此字段的值。对于变量字段,同样可以将此字段的内容进行format处理,format处理请参考本页的基本功能。
通道控制
同步速率与作业并发
-
作业速率上限
设置作业速率上限,则数据同步作业的总速率将尽可能按照这个上限进行同步,此参数需根据实际数据库情况调整,默认为不限制,页面可选择1-20MB/s,也可以直接填写希望的数值。当数据量较大,且硬件配置较好时,可以提高作业速率上限,离线开发将会提高同步速度,使用较短的时间完成同步。
| 流量度量值是数据集成本身的度量值,不代表实际网卡流量,实际流量膨胀看具体的数据存储系统传输序列化情况 |
-
作业并发数
| 仅关系型或MPP类数据库才支持作业并发数,具体支持的数据库类型请参考关系型与MPP型数据库 |
作业并发数需要与「数据源」配置中的「切分键」联合发挥作用,系统将一张表的数据切分多个通道并发读取,提高同步速度,如果作业并发数大于1但是没有配置切分键,任务将置为失败。
作业速率上限=作业并发数*单作业的传输速率,当作业速率上限已定,选择的并发数越高则单并发的速率越低,同时所占用的内存会越高,这可以根据业务需求选择设定的值。
错误数据处理
-
错误记录管理
在数据同步任务中,可开启错误记录管理,开启后,任务会将数据同步过程中的错误数据写入指定的Hive表(可指定表名、生命周期)。在数据同步任务的周期执行过程中,每个实例都会将脏数据写入一个分区,每个实例一个分区。脏数据表采用二级分区形式,第一级为任务名称、第二级为同步时间(Unix时间戳格式),用户可在「运维中心-脏数据管理」模块查看表内的数据和原因。
在当前版本中,在页面点击运行同步任务时,不会将脏数据记录在表中,目前仅在周期调度、补数据操作中才会将脏数据写入Hive表。 用户在页面点击运行时,可能会发现脏数据不为0的情况,需通过执行补数据才能查看脏数据的值与报错原因。
-
脏数据数量控制
支持对于脏数据的自定义监控和告警,包括对脏数据最大记录数阈值,当传输过程出现的脏数据大于指定的数量,则报错退出。
支持对于脏数据占比的统计,当任务执行结束后系统才会统计脏数据占总的同步数据的占比,超过阈值将任务置为失败。
| 错误记录占比是数据同步实际执行结束后统计的,并不会在任务同步过程中统计。 |
-
断点续传
断点续传的基本原理请参考 断点续传,对标识字段的要求如下:
-
数据源(这里特指关系数据库)中必须包含一个升序的字段,比如主键或者日期类型的字段,同步过程中会记录同步的点位,任务在中途发生异常失败,在恢复运行时使用这个字段构造查询条件过滤已经同步过的数据,如果这个字段的值不是升序的,那么任务恢复时过滤的数据就是错误的,最终导致数据的缺失或重复;
-
用户需保证此字段的值是数据升序的;