增量同步
数栈数据集成模块对增量同步的支持有过滤条件和定点增量标识2种,2种方式的异同:
| 对比点 | 过滤条件 | 定点增量 |
|---|---|---|
适用范围 |
关系型数据库(MySQL、Oracle、SQLServer、PostgreSQL、DB2) |
|
对源表的要求 |
数据量可大可小,配置简单,有较为可靠的时间戳、自增标识即可 |
数据量较大,对增量标识字段要求高,要求源表的标识必须为整形或Timestamp类型(Oracle数据库可以为字符串),且要求标识字段保持稳定,不会出现错误值、空值等异常 |
对目标表的要求 |
任意目标类型 |
必须为Hive或HDFS类型 |
工作流的支持 |
可以放在工作流中 |
不能出现在工作流中 |
补数据的支持 |
可识别补数据时的业务日期信息 |
忽略增量标识信息,全量补数据 |
多表的支持 |
支持MySQL分库分表 |
单表 |
依赖的支持 |
支持全部依赖方式 |
必须配置为自依赖模式 |
出错处理 |
简单,补数据即可 |
若任务出错,无需人工处理,下一次同步时会自动从上一次点位开始。若源表的增量标识出错,例如增量标识不稳定,重新从0开始,则人工无法干预,下次同步时,将不读取数据(已保留的标识大于读取的标识,将会被认为没有增量数据) |
定点增量标识
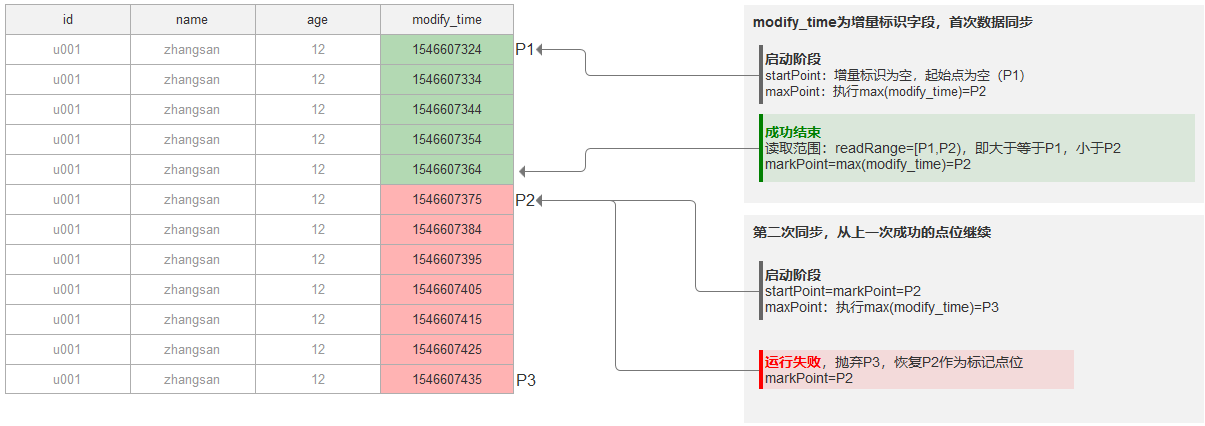
定点增量的本质,是同步任务每次成功的运行结束后,都会记录本次同步的“点位”,下次同步时,会从上次记录的点位继续开始同步,这种方式要求源表具有稳定的增量标识。 系统在同步任务启动时,会先读取源表增量标识的最大值(防止数据重复),之后再从上一次成功结束的点位继续运行,直至刚读取的最大值,若在此期间,源表有新的数据插入,新插入的数据不会被读取。
正常同步过程

如上图所示:
-
首次同步
-
假设此时源表中包含的数据为P1~P2之间的数据
-
首次同步时,增量标识为空,会从第一条数据开始同步(startPoint=P1),并在初始化阶段,在源库执行一次查询,获取最大点位(maxPoint=P2)
-
实际同步的数据范围: readRange=[startPoint,maxPoint)=[P1, P2) ,即 P1 ⇐ readRange < P2 ,注意不包括等于P2点位的数据
-
成功结束,则更新增量标识(markPoint=P2)
-
下一次同步时,startPoint=markPoint=P2
-
-
第二次同步
-
启动时,startPoint计为上次同步成功终止的点位(P2)开始,即
startPoint=markPoint=P2 -
启动时,在源库执行一次查询,获取最大点位(maxPoint=P3)
-
在读取的过程中,数据被不断的插入(P4~P5之间的数据)
-
由于已获取了P4作为最大点位,所以实际同步的数据范围,
readRange=[startPoint,maxPoint)=[P2,P3) -
任务成功结束,更新增量标识(markPoint=P3)
-
下一次同步时,startPoint=P3
-