环境参数
什么是环境参数
环境参数是实时任务运行过程中所使用的参数,通过 任务页面 → 右侧边栏 →环境参数 的方式可查看当前任务的对应参数,修改可对任务运行过程中任务并发数、数据一致性,CheckPoint生成间隔等具体内容进行控制,从而使任务得以更好的运行。
Kafka Kerberos认证参数
在FlinkSQL任务中使用开启了Kerberos认证的Kafka数据源时,需要在对应环境参数中手动开启认证参数。
Client : 数据源开启Zookeeper
KafkaClient: 数据源开启Kerberos认证
默认情况下只需要取消注释符号开启 contexts 参数即可。
## kafka kerberos相关参数
## security.kerberos.login.contexts=Client,KafkaClientKafka Kerberos
针对Kafka数据源开启Kerberos情况,需要在环境参数中配置不同的内容,具体如下:
1.Zookeeper开启Kerberos,Kafka没开
security.kerberos.login.contexts=Client
2.Zookeeper、Kafka都开启了Kerberos
security.kerberos.login.contexts=Client,KafkaClient
3.Zookeeper、Kafka都不开启
注销Security参数:
#security.kerberos.login.contexts=Client
共享连接池
在异步访问维表时,若不开启共享连接池时,每个维表将会独立创建连接到目标数据库,在维表数量多且每个维表共享连接池数量较高的情况时,将会对数据库造成巨大压力。针对于这种情况,平台支持通过环境参数开启共享连接池配置.
|
开启共享连接池前提:任务启动在同一个TM上 |
MiniBatch聚合
MiniBatch 聚合的核心思想是将一组输入的数据缓存在聚合算子内部的缓冲区中。当输入的数据被触发处理时,每个 key 只需一个操作即可访问状态。这样可以大大减少状态开销并获得更好的吞吐量。但是,这可能会增加一些延迟,因为它会缓冲一些记录而不是立即处理它们。这是吞吐量和延迟之间的权衡。
下图说明了 MiniBatch 聚合如何减少状态操作:
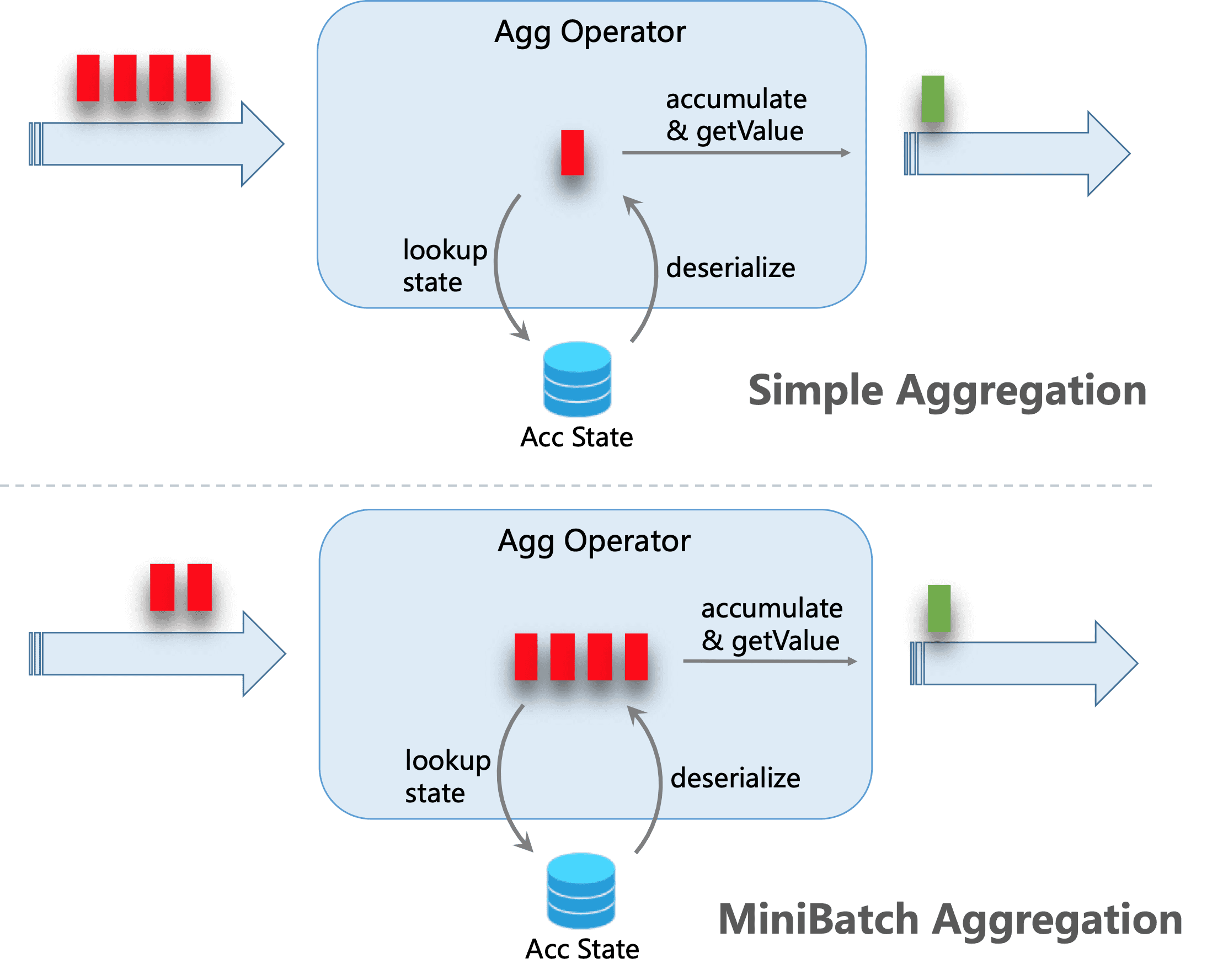 默认情况下 MiniBatch 优化是被禁用的。开启这项优化,需要用户在环境参数中手动设置如下:
默认情况下 MiniBatch 优化是被禁用的。开启这项优化,需要用户在环境参数中手动设置如下:
## 是否开启minibatch
## 可以减少状态开销。这可能会增加一些延迟,因为它会缓冲一些记录而不是立即处理它们。这是吞吐量和延迟之间的权衡
## 是否开启
table.exec.mini-batch.enabled=true
## 状态缓存时间
table.exec.mini-batch.allow-latency=5 s
## 状态最大缓存条数
table.exec.mini-batch.size=5000
## 是否开启Local-Global 聚合。前提需要开启minibatch
## 聚合是为解决数据倾斜问题提出的,类似于 MapReduce 中的 Combine + Reduce 模式
table.optimizer.agg-phase-strategy=TWO_PHASE
## 是否开启拆分 distinct 聚合
## Local-Global 可以解决数据倾斜,但是在处理 distinct 聚合时,其性能并不令人满意。
## 如:SELECT day, COUNT(DISTINCT user_id) FROM T GROUP BY day 如果 distinct key (即 user_id)的值分布稀疏,建议开启
table.optimizer.distinct-agg.split.enabled=true
若开启MiniBatch,则 enabled allow-latency size 三个参数必须同时开启。
更多说明可参考 配置 。
|