实时采集概述
在流计算的场景中,典型的方案是将数据实时打入到Kafka,再由流计算引擎从Kafka中读取数据完成分析处理
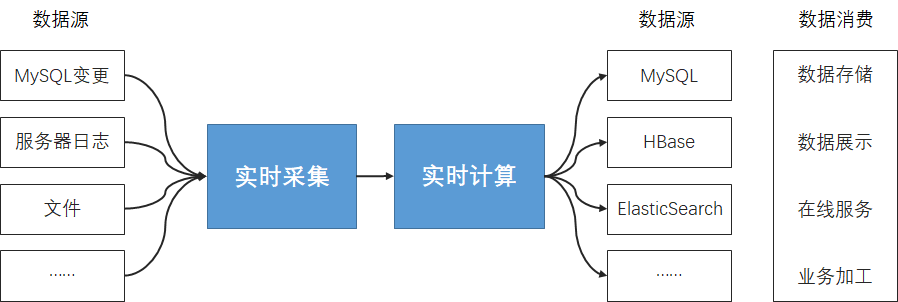
实时采集简介
类似离线数据同步的概念,实时采集依然提供一套抽象化的数据抽取插件(称之为Reader)、数据写入插件(称之为Writer),并基于此框架设计一套简化版的中间数据传输格式,从而达到任意结构化、半结构化数据源之间实时传输。
支持数据源类型
当前版本的流计算支持的数据源较为有限,目前支持数据源如下:
-
MySQL
-
Oracle
-
SQL Server
-
Polardb for MySQL 8
-
EMQ
-
Kafka
-
Restful API
-
WebSocket
-
Socket
-
Beats
未来会扩充如下数据源:
-
KafkaDistribute
-
Netty
-
TCP
-
stdin
-
文件
-
Redis
-
ElasticSearch
-
MongoDB
支持写入模式
实时采集
数据源 |
支持 |
MySQL |
Kafka、Hive、HDFS |
Oracle |
Kafka、Hive、HDFS |
Kafka |
Kafka、HDFS、Hive(手动选表或DDL建表) |
SQL Server |
Kafka、Hive、HDFS |
PolarDB for MySQL 8 |
Kafka、Hive、HDFS |
EMQ |
Kafka、Hive |
TIDB |
Kafka、Hive、HDFS |
DB2 |
Kafka |
Restful API |
Kafka |
Socket |
Kafka |
WebSocket |
Kafka |
实时采集和间隔轮训有什么区别?
实时采集本质是通过读取数据库中的日志文件,比如MySQL Binlog文件,首先需要数据库开启binlog功能,而后插件通过解析Binlog文件,逐条读取用户Insert、Update、Delete操作(此处以MySQL为例,不同数据库对应不同的操作类型),将其以流式数据的方式记录在Kafka中,供后续Flink进行消费。实时采集的优点是读取压力小,数据准确,缺点是需要管理员手动开启日志服务才可使用。
间隔轮训是通过JDBC发起查询请求,通过短间隔的查询数据的方式来达到一个近似实时采集的功能。间隔轮训优点是不需要手动开启日志服务,缺点是间隔轮训间隔过短且轮训数据量大时,容易给服务器带来较高的负担。
写入目标表及关系
数据源 |
结果表 |
写入表 |
写入模式 |
MySQL Binlog |
Kafka(EMQ) |
- |
- |
MySQL Binlog |
Hive |
自动建表 |
追加 |
MySQL Binlog |
HDFS |
- |
追加 |
MySQL 间隔轮询 |
Kafka(EMQ) |
- |
- |
Oracle LogMiner |
Kafka(EMQ) |
- |
- |
Kafka |
Hive |
手动写入 |
追加 |
Kafka |
HDFS |
- |
追加 |
PolarDB for MySQL |
Kafka(EMQ) |
- |
- |
PolarDB for MySQL |
Hive |
自动建表 |
追加 |
SQL Server |
Kafka(EMQ) |
- |
- |
SQL Server |
Hive |
自动建表 |
追加 |
SQL Server |
HDFS |
- |
追加 |
EMQ |
Kafka(EMQ) |
- |
- |
EMQ |
Hive |
自动建表 |
追加 |
EMQ |
HDFS |
- |
追加 |
实时采集开发模式
类似离线的数据同步任务,实时采集同样提供两种开发模式:向导模式和脚本模式。
-
向导模式:提供向导式的开发引导,通过可视化的填写和下一步的引导,帮助快速完成实时采集任务的配置工作。向导模式的学习成本低,但无法享受到一些高级功能。
-
脚本模式:您可以通过直接编写实时采集的JSON脚本来完成实时采集开发,适合高级用户,学习成本较高。脚本模式可以提供更丰富灵活的能力,做精细化的配置管理。
| 实时采集任务的配置模式在创建时指定,指定之后不可变更。代码编写前需要完成数据源的配置和目标表的创建。 |
数据采集模块主要由以下几部分构成:
-
数据源管理
-
实时采集任务的配置与执行