新增MySQL实时采集
本节介绍如何在实时计算中配置MySQL实时采集任务。
实时计算支持MySQL数据库的实时采集,当MySQL发生insert、update等操作时,实时采集组件可根据MySQL的Binlog信息立即获取其操作,并实时将变更信息同步至目标数据源。
实时采集-参数配置
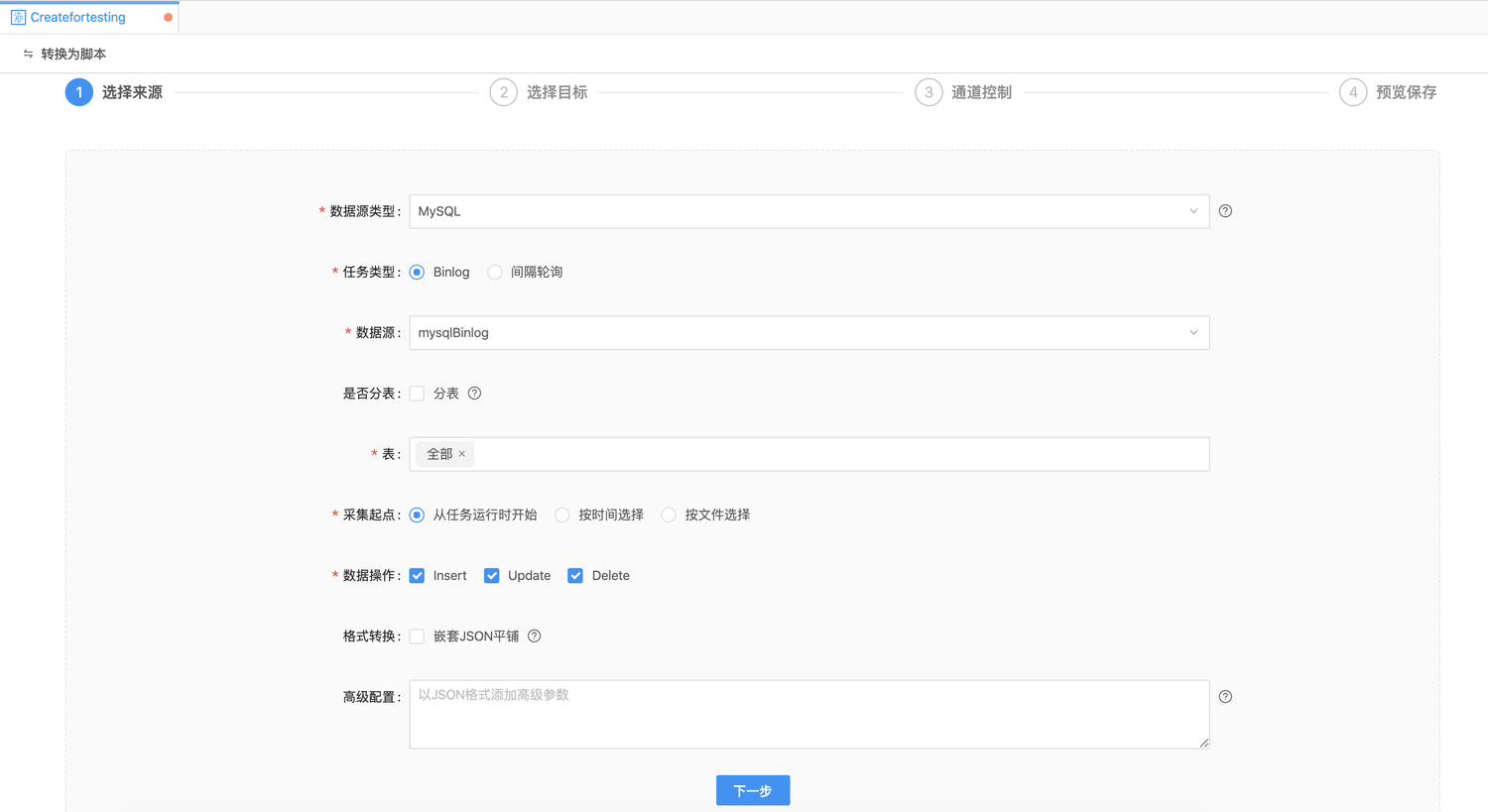
| 配置 | 说明 |
|---|---|
任务类型 |
MySQL实时采集支持两种类型:通过Binlog实时采集、通过间隔轮询进行采集 |
数据源 |
选择对应数据类型的已有数据源 |
是否分表 |
选择分表,可以设置多对多分表、分组写入; image::3-4-2021-13-45-46-PM.png[] |
表 |
选择数据源表,支持多表合并写入一张表; |
采集起点 |
用户可选择从任务运行时开始、按时间选择、按文件选择三种采集起点 |
数据操作 |
支持Insert、Update、Delete三种数据操作类型选择,当发生insert、update等操作时,实时采集组件可根据Binlog等信息立即获取其操作,并实时将变更信息同步至目标数据源 |
格式转换 |
勾选后,系统将会多层嵌套格式的JSON分解为单层结构,例如:{"a":1, "b": {"c":3}},将会被分解为:{"a":1,"b_c":3} |
高级配置 |
以JSON格式添加高级参数,例如对关系型数据库可配置fetchSize,每类数据源支持不同的参数 |
如何开启Mysql_Binlog功能
1.修改配置文件
server_id=109
log_bin = /var/lib/mysql/mysql-bin
binlog_format = ROW
expire_logs_days = 302.添加权限
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%' IDENTIFIED BY 'canal';3.问题排查
采集mysql binlog 发现采集不到数据
(1)查看binlog是否开启
show variables like '%log_bin%' ;
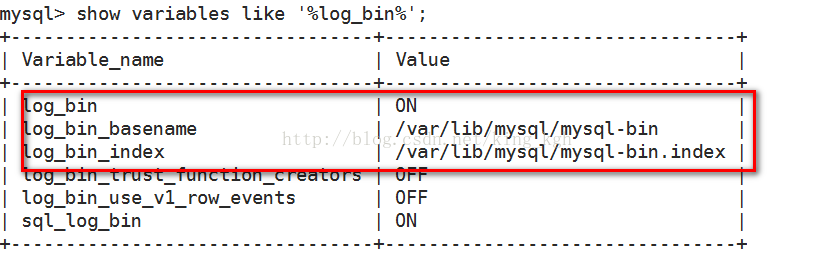
(2)binlog_format 是否设置为ROW
注意 binlog_format 必须设置为 ROW, 因为在 STATEMENT 或 MIXED 模式下, Binlog 只会记录和传输 SQL 语句(以减少日志大小),而不包含具体数据,我们也就无法保存了。
(3)从节点通过一个专门的账号连接主节点,这个账号需要拥有全局的 REPLICATION 权限。我们可以使用 GRANT 命令创建这样的账号:
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT
ON . TO 'canal'@'%' IDENTIFIED BY 'canal';
参考:https://blog.csdn.net/zjerryj/article/details/77152226
间隔轮询-参数配置
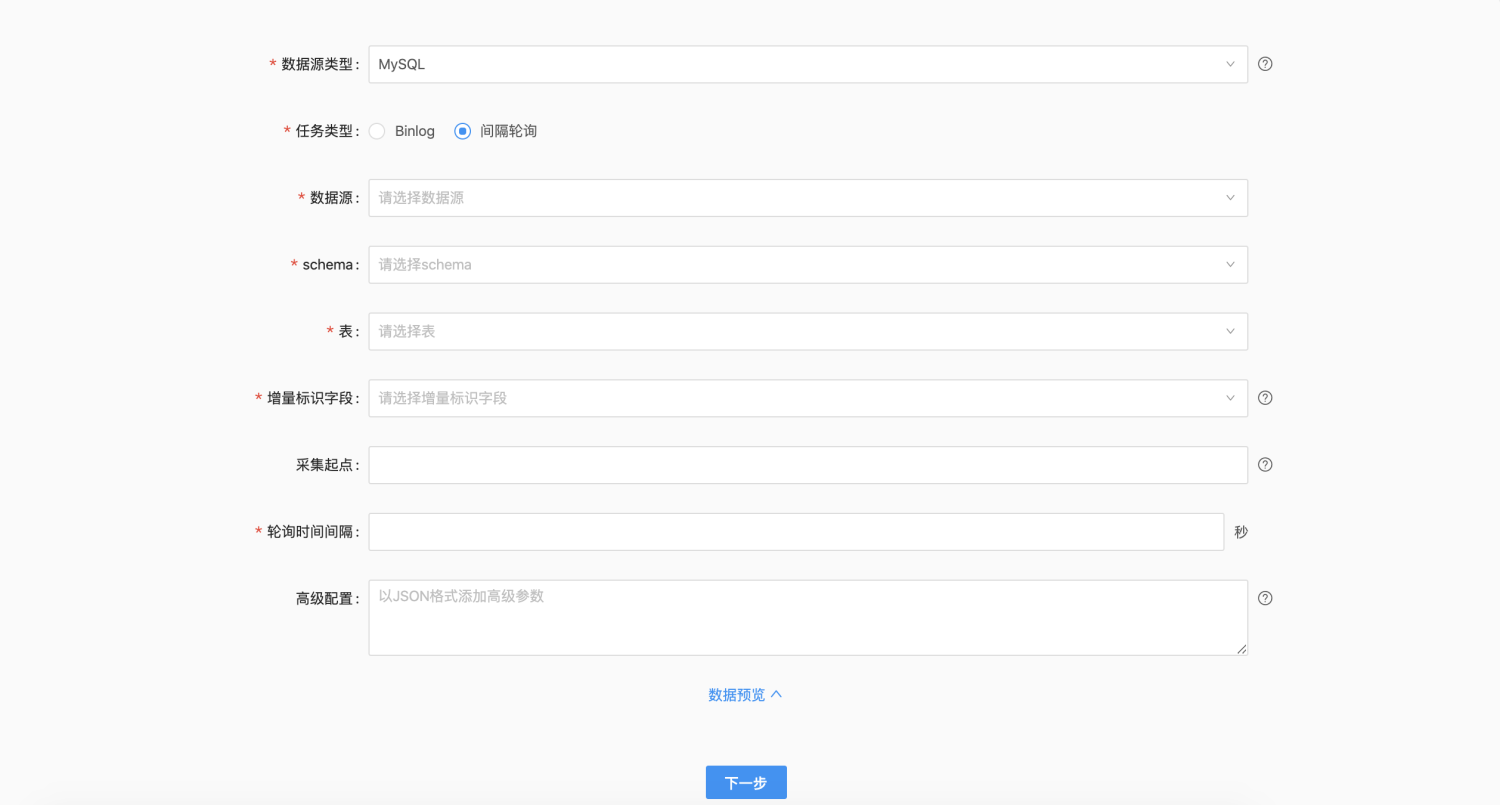
| 配置 | 说明 |
|---|---|
任务类型 |
MySQL实时采集支持两种类型:通过Binlog实时采集、通过间隔轮询进行采集 |
数据源 |
选择对应数据类型的已有数据源 |
Schema |
选择数据源下指定Schema |
表 |
选择数据源表,支持多表合并写入一张表; |
增量标识字段 |
用户需选择增量标示字段,每次同步时,系统自动记录增量标识的最大值,下次运行时,会从上一次的最大值继续同步数据,实现增量同步;支持将数值类型、Timestamp类型作为增量标识字段 |
采集起点 |
用户根据选择的增量标示字段设定相应的采集起点,若不填则默认从头开始拉取数据,输入格式请在"数据预览"中参考所选增量标示字段内容。采集时不包含采集起点,例如采集起点为40 则采集开始时不会包含id=40这一条数据。 |
轮询时间间隔 |
手动设定轮询时间间隔,单位为秒 |
高级配置 |
以JSON格式添加高级参数,例如对关系型数据库可配置fetchSize,每类数据源支持不同的参数 |
| 从mysql—binlog采集数据到kafka时,Flink1.12与FLink1.10的数据输出格式不一致,不影响数据结果。 |
操作步骤
具体操作可参考快速开始中的 实时采集。