Hive
本节介绍如何在实时计算中配置Hive数据源。
操作步骤
1.登陆数栈DTinsight,进入 实时计算 模块。
2.进入数据源,单击 新增数据源。

3.在 新增数据源 弹窗中,选择数据类型为 Hive。
4.填写Hive数据源的各配置项。
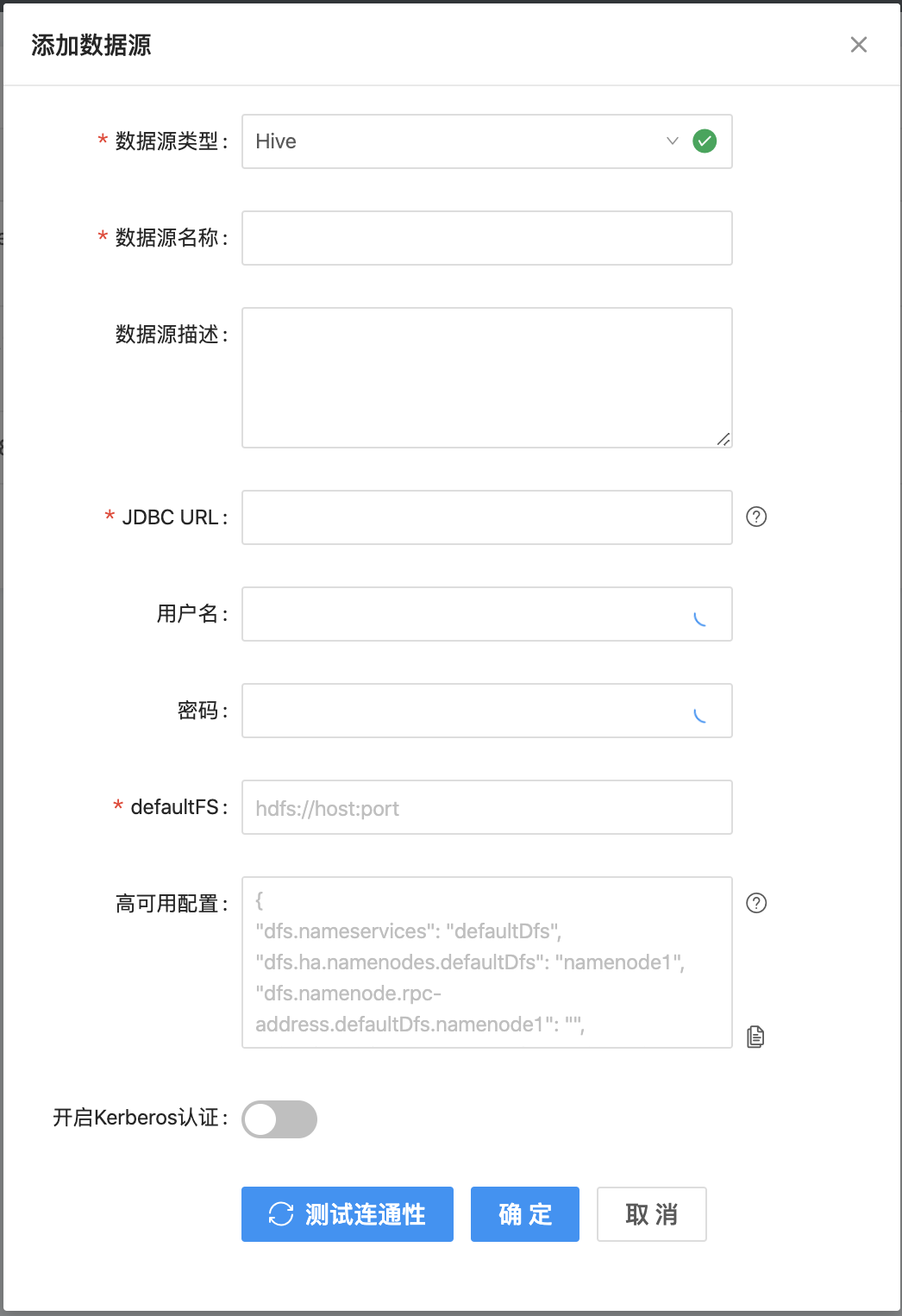
5.点击 测试连通性。
6.测试连通性通过后,点击 确定,即可完成Hive数据源的配置。
配置 |
说明 |
||
数据源名称 |
只能由中文、字母、数字和下划线组成,长度无限制。 |
||
数据源描述 |
对数据源进行简单描述,长度无限制。 |
||
JDBC URL |
JDBC URL链接信息,格式要求如下: |
||
用户名/密码 |
数据库对应的用户名和密码。 |
||
defaultFS |
相当于 fs.default.name,格式如下: |
||
高可用配置 |
补充高可用配置参数,可以使数栈访问高可用模式下的HDFS数据源,高可用配置的示例如下:
|
||
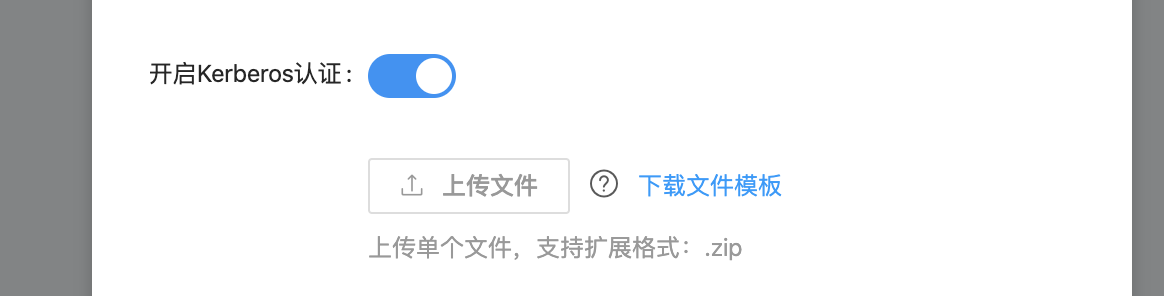
开启Kerberos认证 |
|