模型评估
二分类评估
pipeline.mllib.evaluation.evaluate_v2. EvaluateV2Ai
组件说明:一个综合评估组件,里面包含综合指数、KS/PR/LIFT/ROC曲线及详细信息。根据选择的原始标签列数据,以及明细列的信息,对二分类预测的结果进行评估。评估的内容包括准确率,F1-score,roc-curve等。
组件输入:输入预测组件的输出表,即预测后的数据表
组件输出:输出综合指标表,等频分桶详细数据表,等宽分桶详细数据表
输入桩input
-
input1:输入预测后的数据表。
输出桩output
-
output1:输出综合指标表。
-
output2:输出等频分桶详细数据表。
-
output3:输出等宽分桶详细数据表。
字段设置col_settings
-
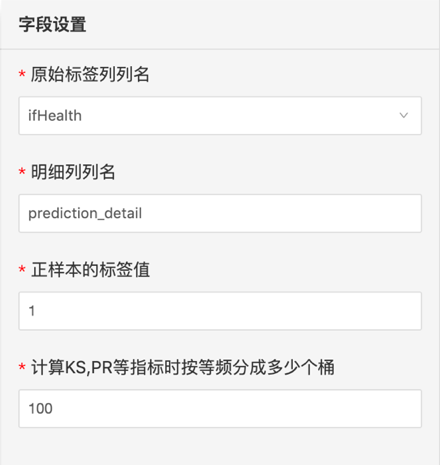
old_label: 真实值列名,必选,单选
-
detail_label: 预测概率列列名,必选,单选
-
pos:正类表情,必选,单选。
-
bin:分箱数,必选,默认100。
回归模型评估
pipeline.mllib.evaluation.regression_evaluation_v2.RegressionEvaluateV2Ai
组件说明:回归指标:基于预测结果和原始结果,评价回归算法模型的优劣,指标包括MSE、MAE、MAPE、R平方值等。
组件输入:输入回归模型预测结果表。
组件输出:输出综合指标表,残差分桶统计
输入桩input
-
input1:输入回归模型预测后的数据结果表。
输出桩output
-
output1:输出综合指标表。
-
output2:输出等频分桶详细数据表。
字段设置col_settings
-
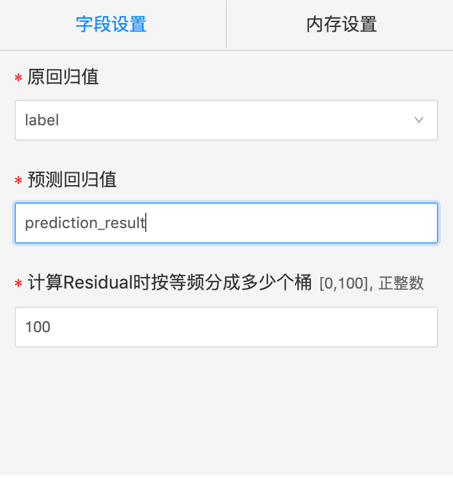
label: 原回归值列,必选,单选
-
pre: 预测回归值列,必选,单选
-
bucket:计算残差时按等频分成多少个直方图分箱数量,必选,默认100
内存设置
-
占用内存大小:可设置组件占用的内存大小,范围[256,64*1024]MB,默认512MB。
-
并发数:可设置组件的并发数,范围[1,9999],默认为1,单线程运行。
聚类模型评估
pipeline.mllib.evaluation.cluster_evaluation_v2.ClusterEvaluateV2Ai
组件说明:聚类模型评估组件,是评估原始数据进行聚类的可行性和聚类方法产生的结果的质量,主要包括:估计聚类趋势、确定数据集中的簇数、测定聚类质量。
组件输入:输入聚类数据表以及聚类模型。
组件输出:输出聚类综合评估结果表
输入桩input
-
input1:输入聚类数据表。
-
input2:输入聚类模型。
输出桩output
-
output1:输出综合指标表。
字段设置col_settings
-
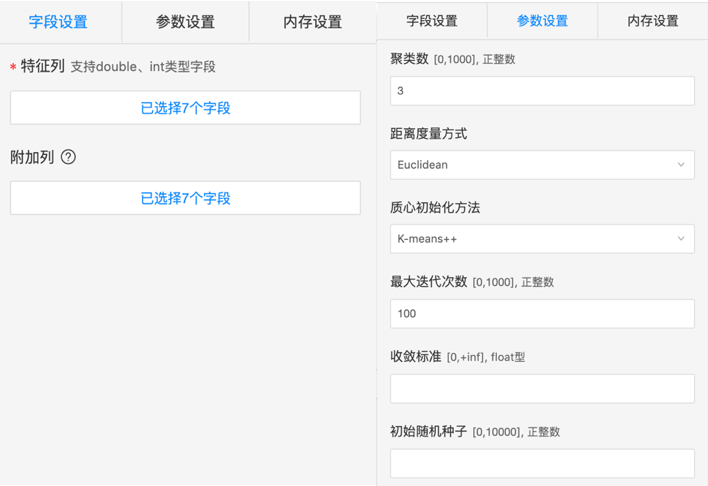
col: 参数评估列,一般全选
内存设置
-
占用内存大小:可设置组件占用的内存大小,范围[256,64*1024]MB,默认512MB。
-
并发数:可设置组件的并发数,范围[1,9999],默认为1,单线程运行。
混淆矩阵
pipeline.mllib.evaluation.confusion_matrix_v2.ConfusionMatrixV2Ai
组件说明:混淆矩阵,是表示精度评价的一种标注格式,用n行n列的矩阵形式表示。其是一个可视化工具,常用于监督学习,在无监督学习一般叫做匹配矩阵。在图像精度评价中,主要用于比较分类结果和实际测得值,可以把分类结果的精度显示在一个混淆矩阵里面。 混淆矩阵的每一列代表了预测类别,每一列的总数表示预测为该类别的数据的数目;每一行代表了数据的真实归属类别,每一行的数据总数表示该类别的数据实例的数目。每一列中的数值表示真实数据被预测为该类的数目。
组件输入:输入分类模型预测结果。
组件输出:输出混淆矩阵相关数据。
输入桩input
-
input1:输入分类模型预测数据表。
输出桩output
-
output1:输出混淆矩阵相关数据。
字段设置col_settings
-
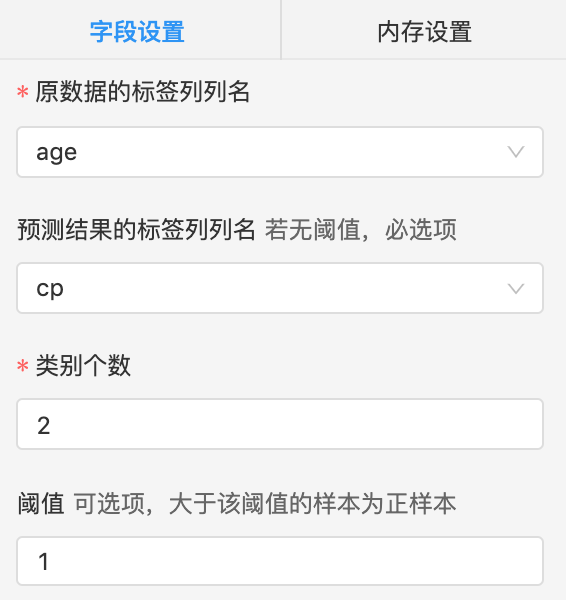
label: 原始数据标签列,必选,单选
-
pre: 预测结果列,必选,单选
-
类别个数:类别个数
-
阈值:阈值
内存设置
-
占用内存大小:可设置组件占用的内存大小,范围[256,64*1024]MB,默认512MB。
-
并发数:可设置组件的并发数,范围[1,9999],默认为1,单线程运行。