分类
GBDT二分类
pipeline.mllib.classification.gbdt_classifier.GradientBoostingClassifierAI
组件说明:GBDT二分类组件,是一种迭代的决策树算法,将多颗决策树的结果累加起来作为最终的预测输出。进行回归预测。
组件输入:输入待处理的数据表。
组件输出:输出特征重要性以及GBDT二分类模型。
输入桩input
-
input1:输入待处理的数据表。
输出桩output
-
output1:输出特征重要性。
-
output2:输出GBDT二分类模型。
字段设置
-
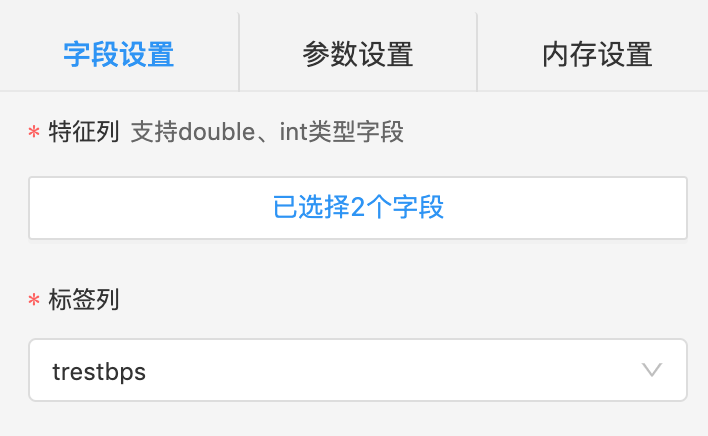
col: 特征列名
-
label: 标签列名
内存设置
-
占用内存大小:可设置组件占用的内存大小,范围[256,64*1024]MB,默认512MB。
-
并发数:可设置组件的并发数,范围[1,9999],默认为1,单线程运行。
模型参数
| 参数名称 | 参数描述 | 参数可选项 | 默认值 |
|---|---|---|---|
loss |
可选,损失函数类型 |
'deviance', 'exponential' |
'deviance' |
n_estimators |
可选,树数量,即弱分类器的个数 |
int |
100 |
learning_rate |
可选,学习率 |
float |
0.1 |
max_depth |
可选,树的最大深度 |
int |
5 |
min_samples_leaf |
可选,每个叶子节点所属的最少样本个数或比例 |
int |
1 |
subsample |
可选,样本采样比例 |
float |
1.0 |
max_features |
可选,训练中采集的特征比例 |
float |
None |
validation_fraction |
可选,测试样本数比例 |
float |
0.1 |
random_state |
可选,随机数产生器种子 |
int |
None |
支持向量机
pipeline.mllib.classification.svm.SVCAi

组件说明:SVM组件,又称为支持向量机,是一类按监督学习方式对数据进行二元分类的广义线性分类器,决策边界是对学习样本求解的最大边距超平面。 SVM使用损失函数计算经验风险,并在求解系统中加入正则项已优化结构风险,是一个稳健的分类器。
组件输入:输入预处理后需要待处理的数据表。
组件输出:输出训练后的支持向量机模型。
输入桩input
-
Input: 输入预处理后需要待处理的数据表
输出桩output
-
model_out: 输出训练后的支持向量机模型。
字段设置col_settings
-
col: 特征列,支持double、int类型字段
-
label: 标签列名
内存设置
-
占用内存大小:可设置组件占用的内存大小,范围[256,64*1024]MB,默认512MB。
-
并发数:可设置组件的并发数,范围[1,9999],默认为1,单线程运行。
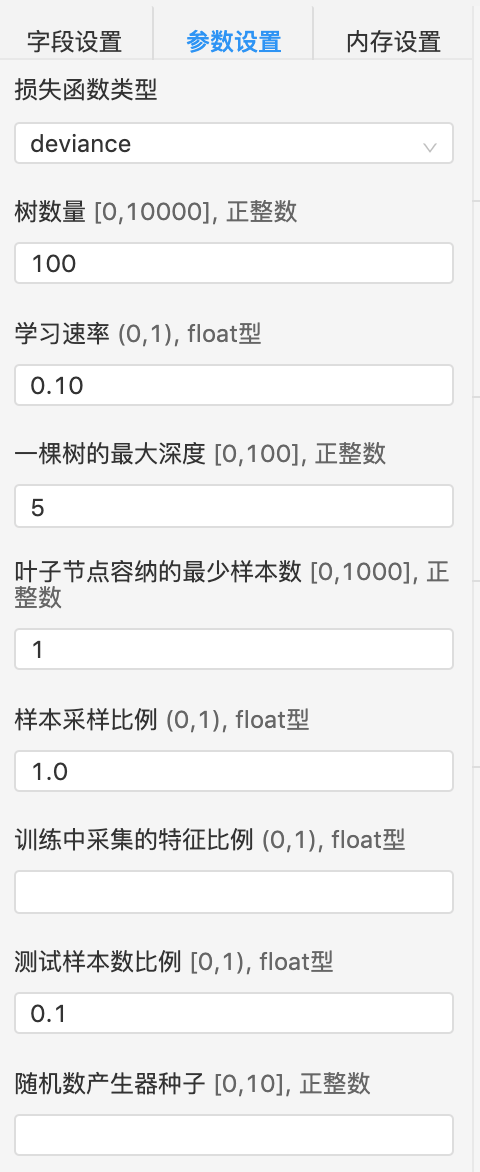
模型参数settings
| 参数名称 | 参数描述 | 参数可选项 | 默认值 |
|---|---|---|---|
kernel |
可选,指定svm的核函数。如果是’linear',会调用linearsvm库进行加速 |
'linear', 'poly', 'rbf', 'sigmoid', 'precomputed' |
'rbf' |
degree |
可选,多项式核的阶。在kernel='poly’时启用。 |
int |
3 |
gamma |
可选,kernel='rbf','poly’和’sigmoid’核时的系数。如果是’auto',则相当于1 / n_features |
'auto', float |
'auto' |
tol |
可选,迭代停止标准 |
double |
0.0001 |
C |
可选,惩罚项系数。C越大,模型泛化能力越强,但精度可能有所降低 |
double |
1.0 |
max_iter |
可选,最大迭代次数 |
int |
1000 |
random_state |
可选,随机算子 |
int |
None |
逻辑回归二分类
pipeline.mllib.classification.logistic_v2.LogisticRegressionV2Ai
组件说明:逻辑回归二分类组件,用于预测当前被观察的对象属于哪个组,最终提供离散的二进制(0或1)输出结果。
组件输入:输入预处理后的数据表
组件输出:输出训练后的逻辑回归模型
输入桩input
-
Input: 输入预处理后需要待处理的数据表
输出桩output
-
model_out: 输出训练后的逻辑回归模型。
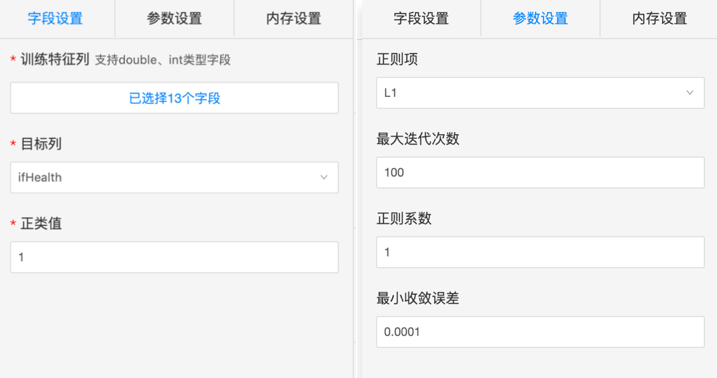
字段设置col_settings
-
col: 特征列,支持double、int类型字段
-
label: 目标列
-
正类值:自定义
内存设置
-
占用内存大小:可设置组件占用的内存大小,范围[256,64*1024]MB,默认512MB。
-
并发数:可设置组件的并发数,范围[1,9999],默认为1,单线程运行。
模型参数setting
| 参数名称 | 参数描述 | 参数可选项 | 默认值 |
|---|---|---|---|
penalty |
可选,惩罚中使用的规范 |
'l1', 'l2', ' elasticnet', ' none' |
'l2' |
max_iter |
可选,最大迭代次数 |
— |
100 |
C |
可选,惩罚项系数。C越大,模型泛化能力越强,但精度可能有所降低 |
— |
1.0 |
tol |
可选,迭代停止标准 |
— |
0.0001 |
线性支持向量机
pipeline.mllib.classification.svm.LinearSVCAi

组件说明:线性支持向量机组件,是一类按监督学习方式对数据进行二元分类的广义线性分类器,决策边界是对学习样本求解的最大边距超平面。 其只支持线性核系数,运行速度远远快于支持向量机。
组件输入:输入预处理后需要待处理的数据表。
组件输出:输出训练后的线性支持向量机模型。
输入桩input
-
Input: 输入预处理后需要待处理的数据表。
输出桩output
-
model_out: 输出线性支持向量机模型。
字段设置col_settings
-
col: 特征列名,支持double、int类型字段
-
label: 标签列名,支持int、double、string类型字段
内存设置
-
占用内存大小:可设置组件占用的内存大小,范围[256,64*1024]MB,默认512MB。
-
并发数:可设置组件的并发数,范围[1,9999],默认为1,单线程运行。
模型参数settings
| 参数名称 | 参数描述 | 参数可选项 | 默认值 |
|---|---|---|---|
penalty |
可选,惩罚因子。l1或者l2,只有在kernel='linear’时启用 |
'l1', 'l2' |
'l2' |
loss |
可选,损失函数。 |
'hinge','squared_hinge' |
'squared_hinge' |
tol |
可选,迭代停止标准 |
double |
0.0001 |
C |
可选,惩罚项系数。C越大,模型泛化能力越强,但精度可能有所降低 |
double |
1.0 |
max_iter |
可选,最大迭代次数 |
int |
1000 |
random_state |
可选,随机算子 |
int |
None |