用户流失率预测
实验基础信息
-
实验名称:用户流失率预测
-
实验英文名:UserChurn
-
所属类目:用户运营
-
实验描述:根据用户历史特征数据,以及用户是否流失标签,建立XGB分类模型,预测用户是否会流失,以及流失的概率
-
主要应用算法:XGB分类
数据说明
-
数据来源:Kaggle比赛数据,Telco电信公司用户流失数据。
-
数据属性:二分类数据(churn列,Yes为流失,No为否)。
-
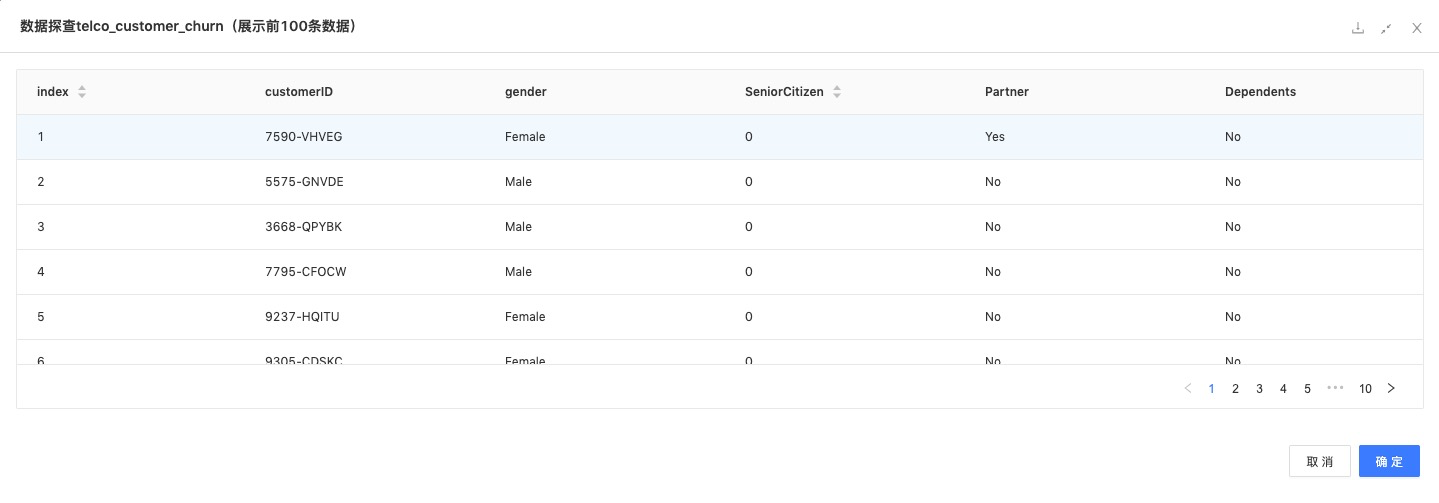
数据详情:数据集为用户信息,包含用户id、专线数量、服务类型、是否进行技术支持、是否上网看电视、是否上网电影、月消费金额、总消费金额、交费周期等21列数据。
实验搭建
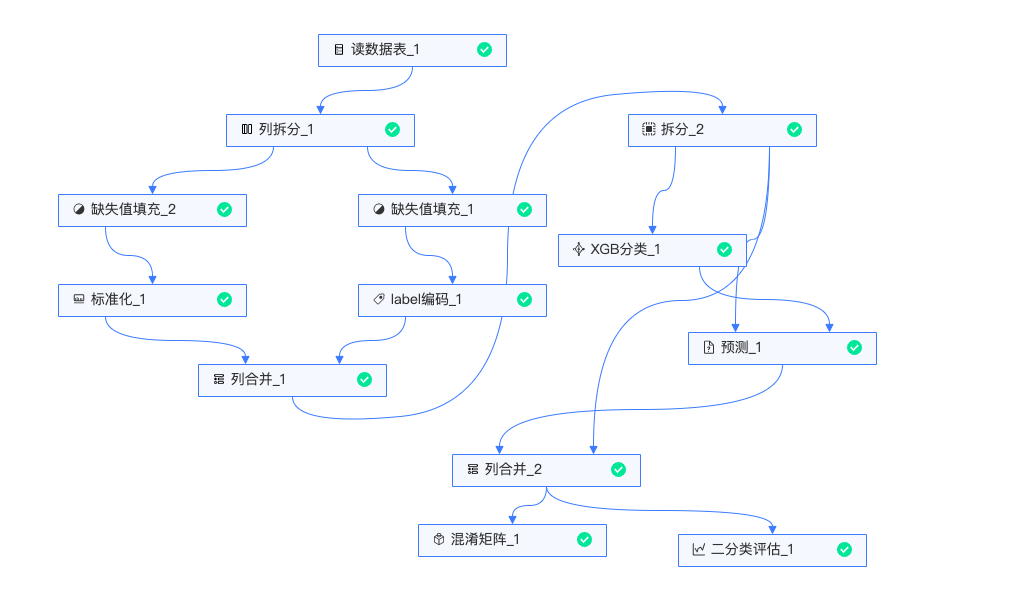
实验整体流程如下:
-
读数据:读入原始数据。
-
列拆分:将数字类型(连续特征)和string类型(分类特征)分开。
-
缺失值填充:数值类型缺失值用中位数填充,String类型的缺失值数据用众数填充。
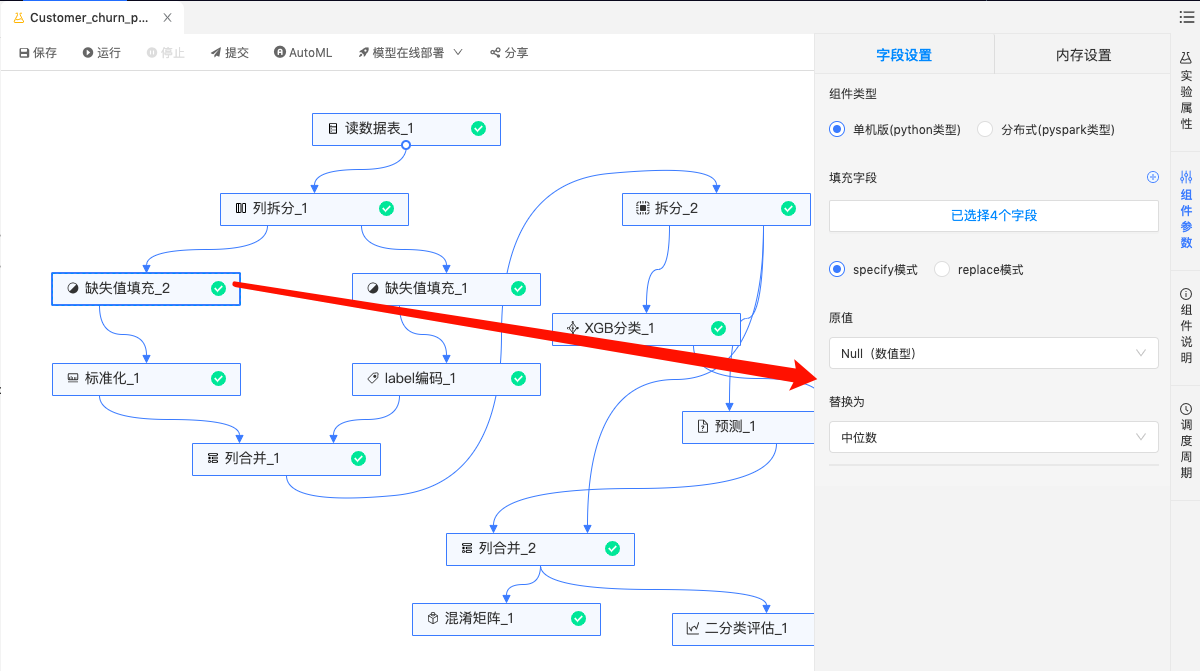
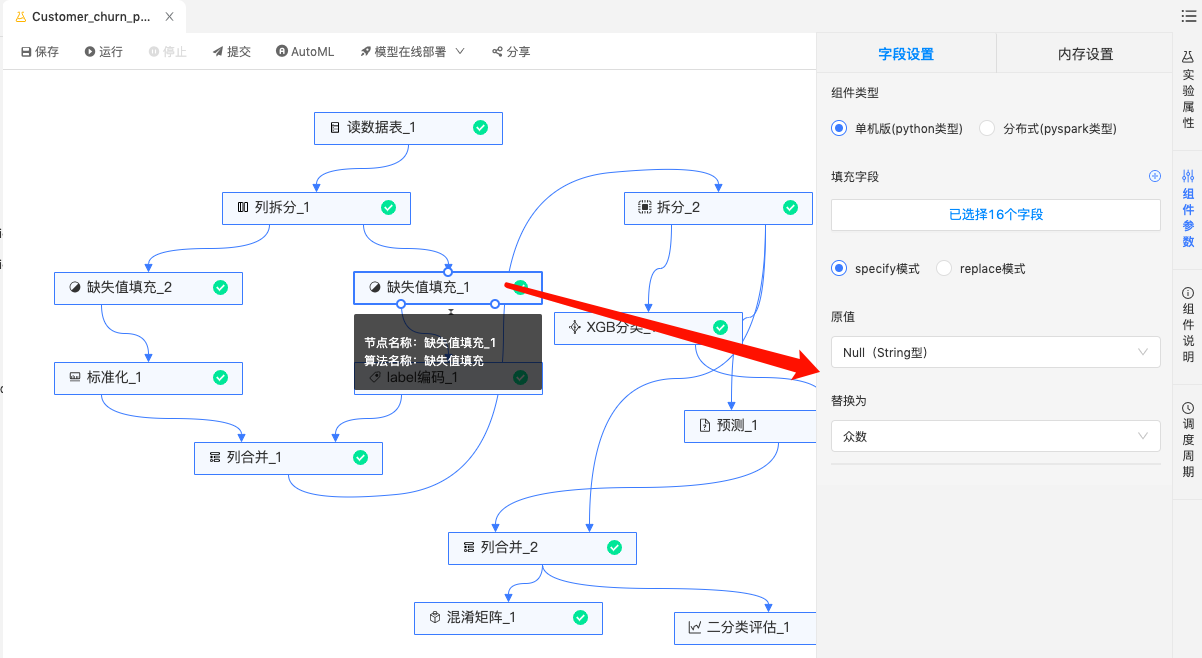
-
标准化组件:数值类型的连续型进行标准化。
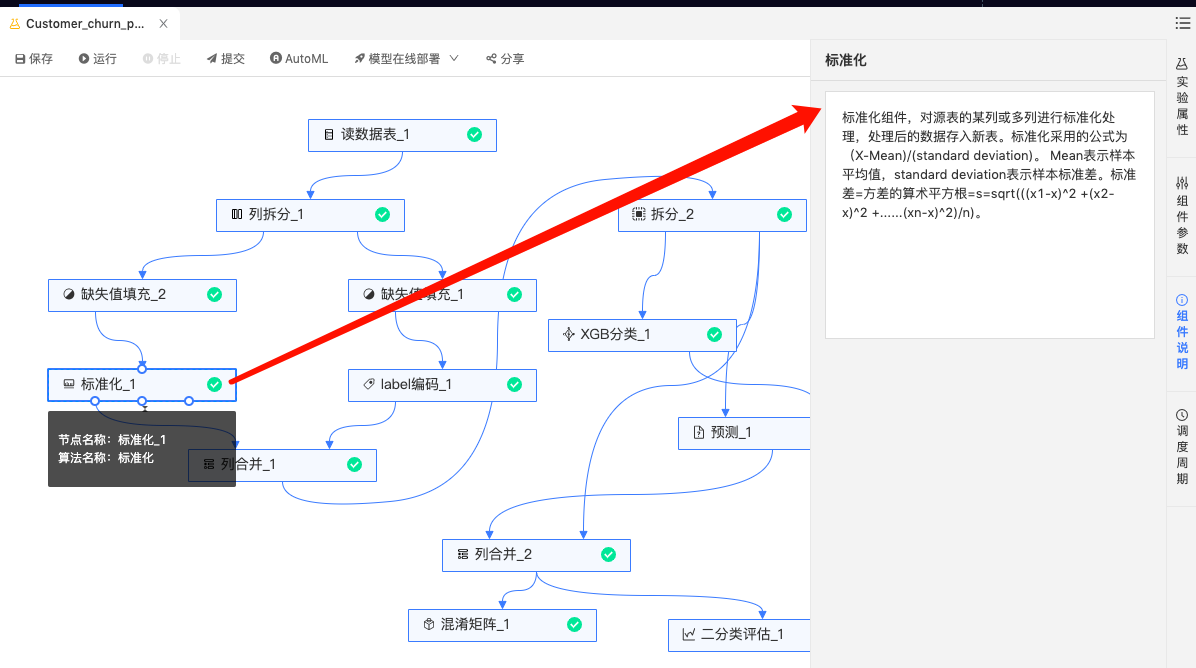
-
label编码组件:String类型的分类特征进行标签编码。
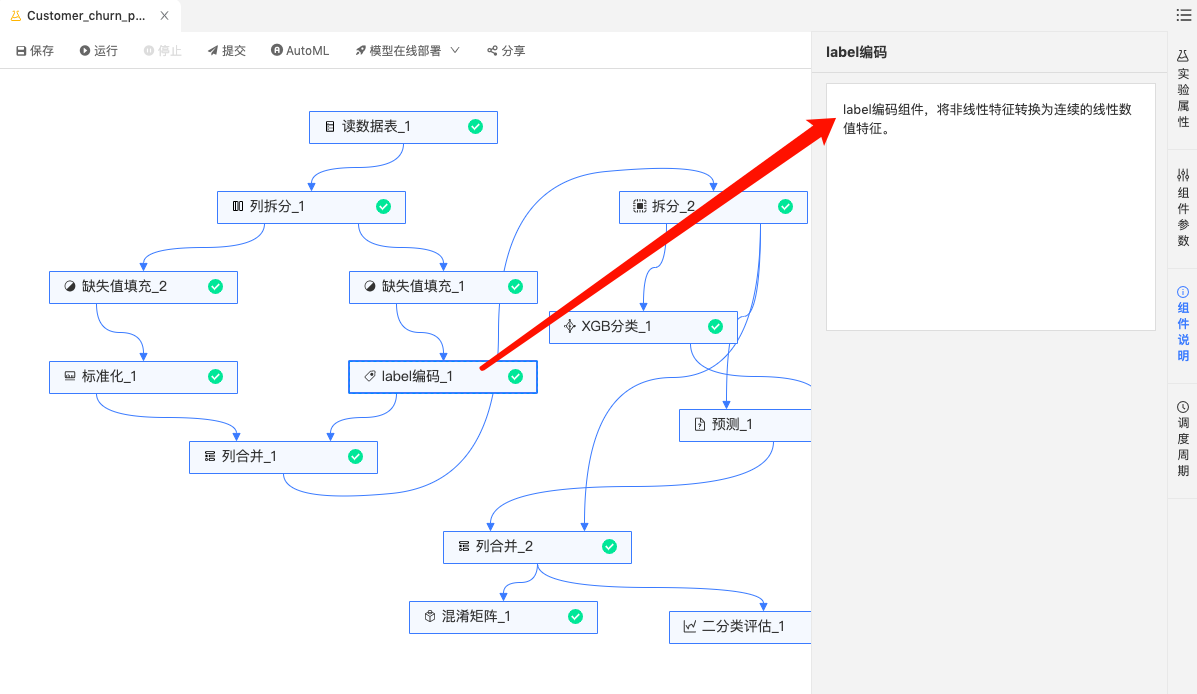
-
列合并:将数值类型、String类型处理过的数据进行合并。
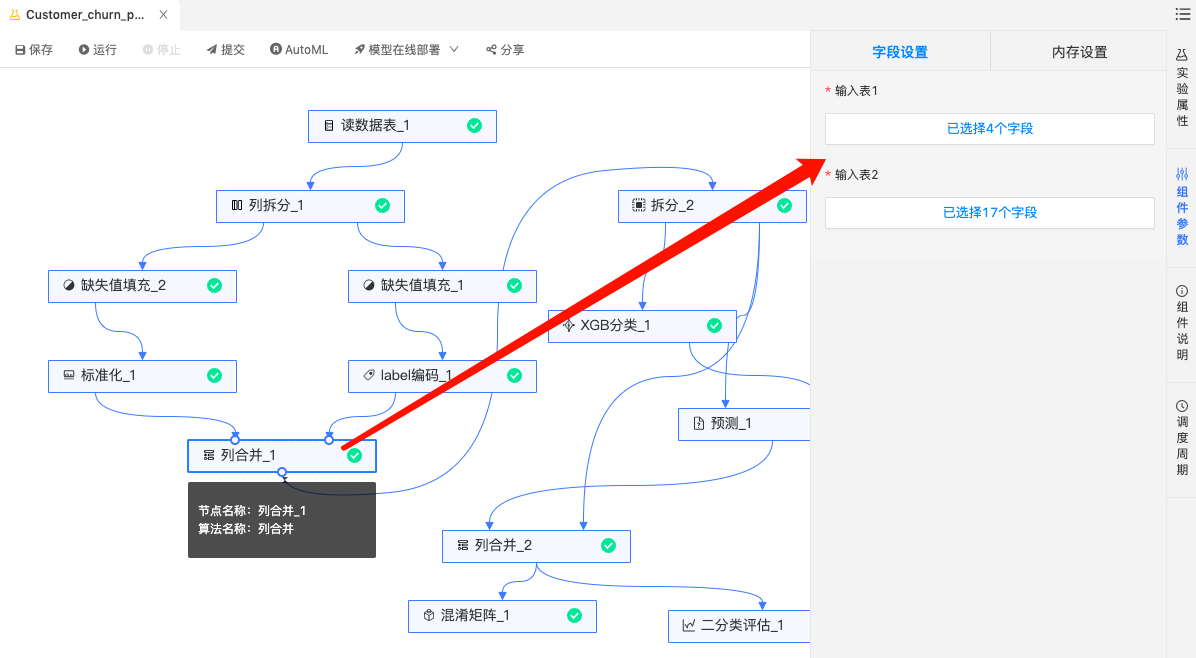
数据结果:
-
拆分组件:将训练数据和测试数据按8:2的比例进行拆分。
-
XGB分类:用训练数据训练XGB二分类模型。
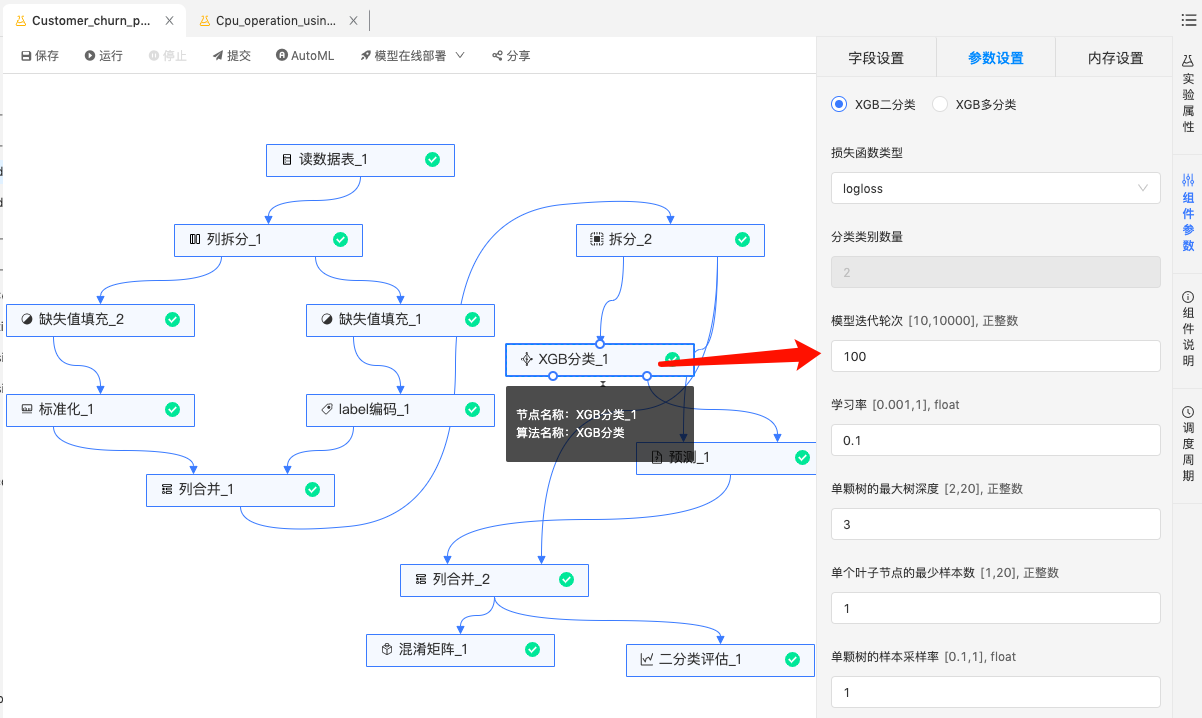
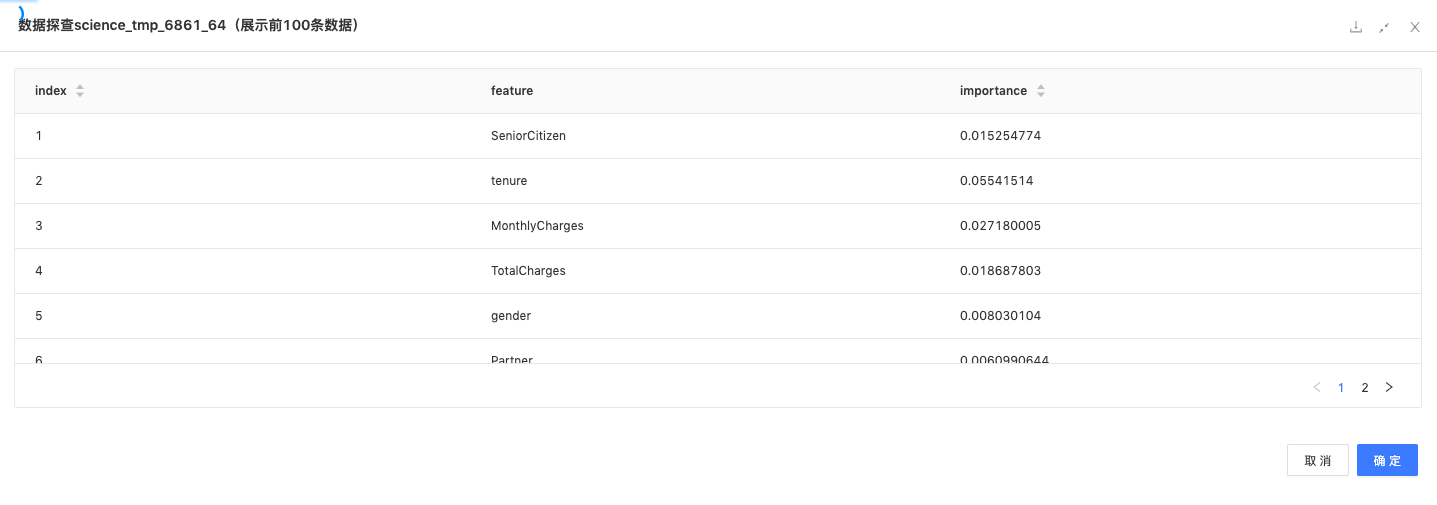
特征重要性如下:
-
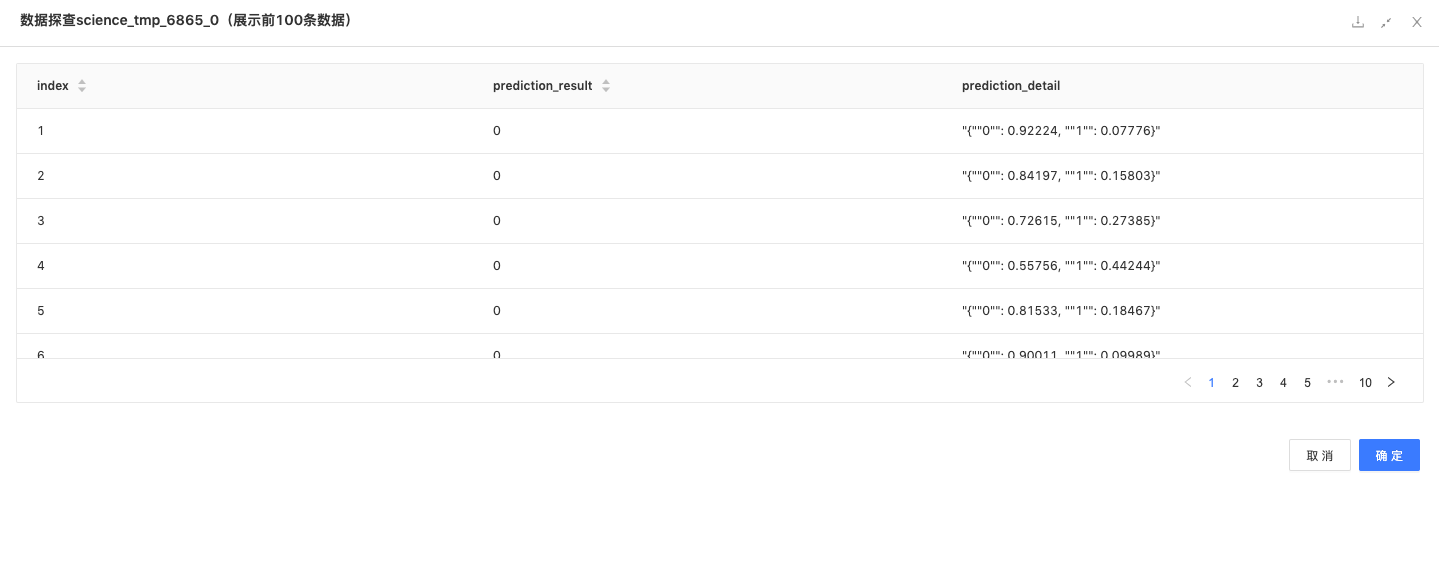
预测组件:用训练好的模型预测测试数据,预测结果如下,预测出高用户是否会流失,以及流失概率。
-
列合并:合并真实值、预测值、预测概率。
-
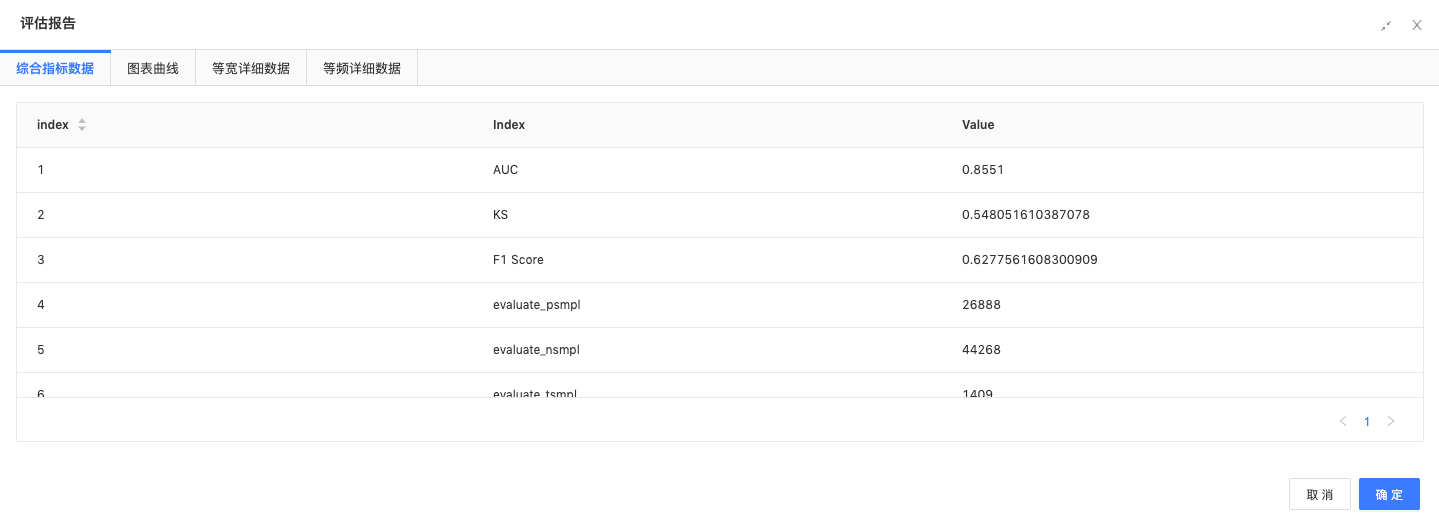
混淆矩阵:通过混淆矩阵,评估模型预测的准确性。
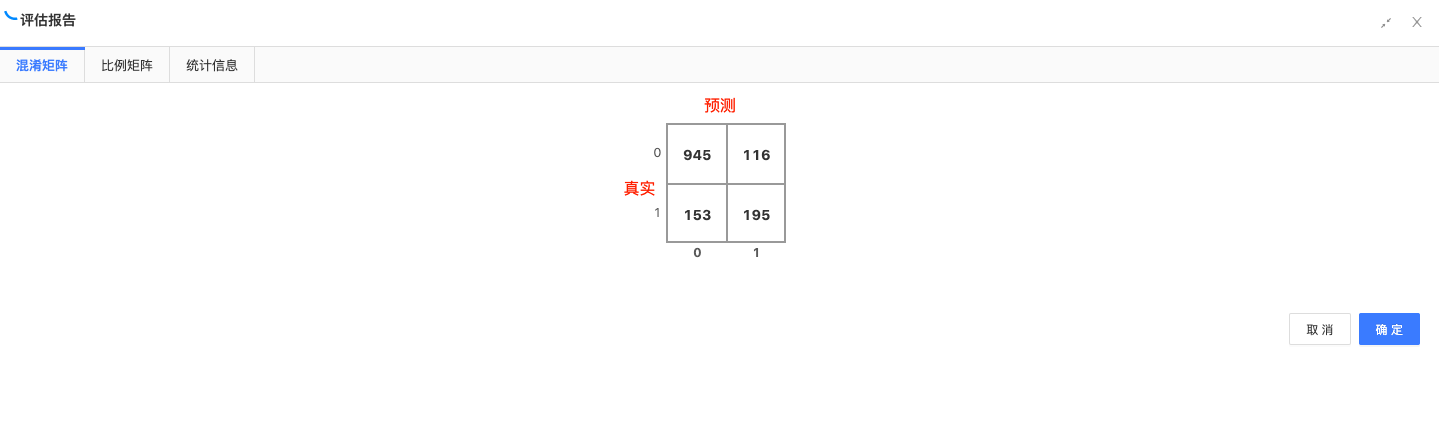
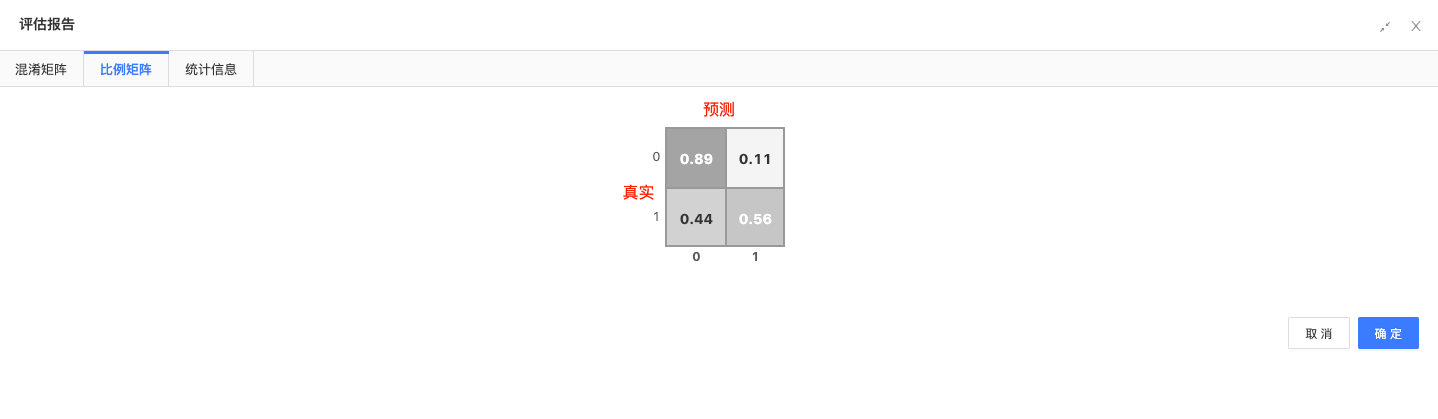
混淆矩阵为[945, 116, 153, 195]
-
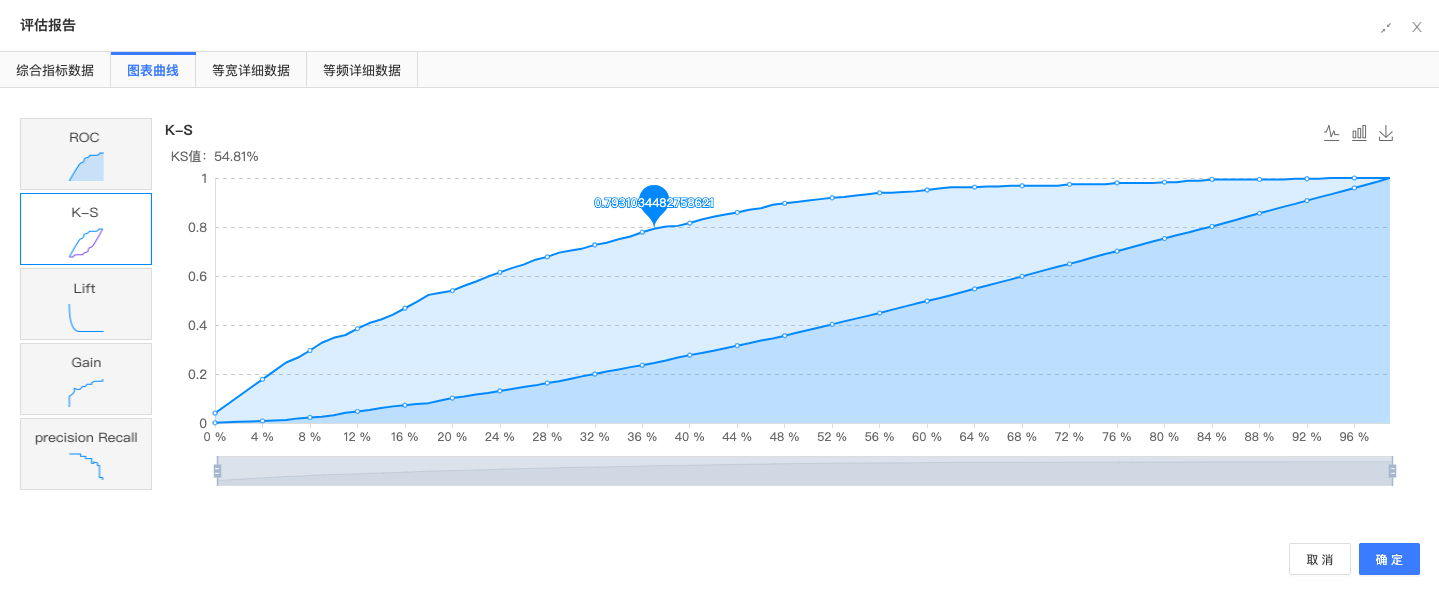
二分类评估:通过二分类评估组件,评估模型预测结果,二分类AUC为:0.8547。