资源管理
资源管理用于管理从本地上传的Python文件、工程,以便业务侧的任务在AIWorks上统一运行和管理。可应用于以下场景:
(1) 本地开发的python文件与工程,利用统一的算法环境运行、管理;
(2) 将算法包在此处上传,在其他任务中引用。
上传资源
可上传.py和.zip文件作为资源,在平台中统一管理、运行。或者是让其他任务引用。
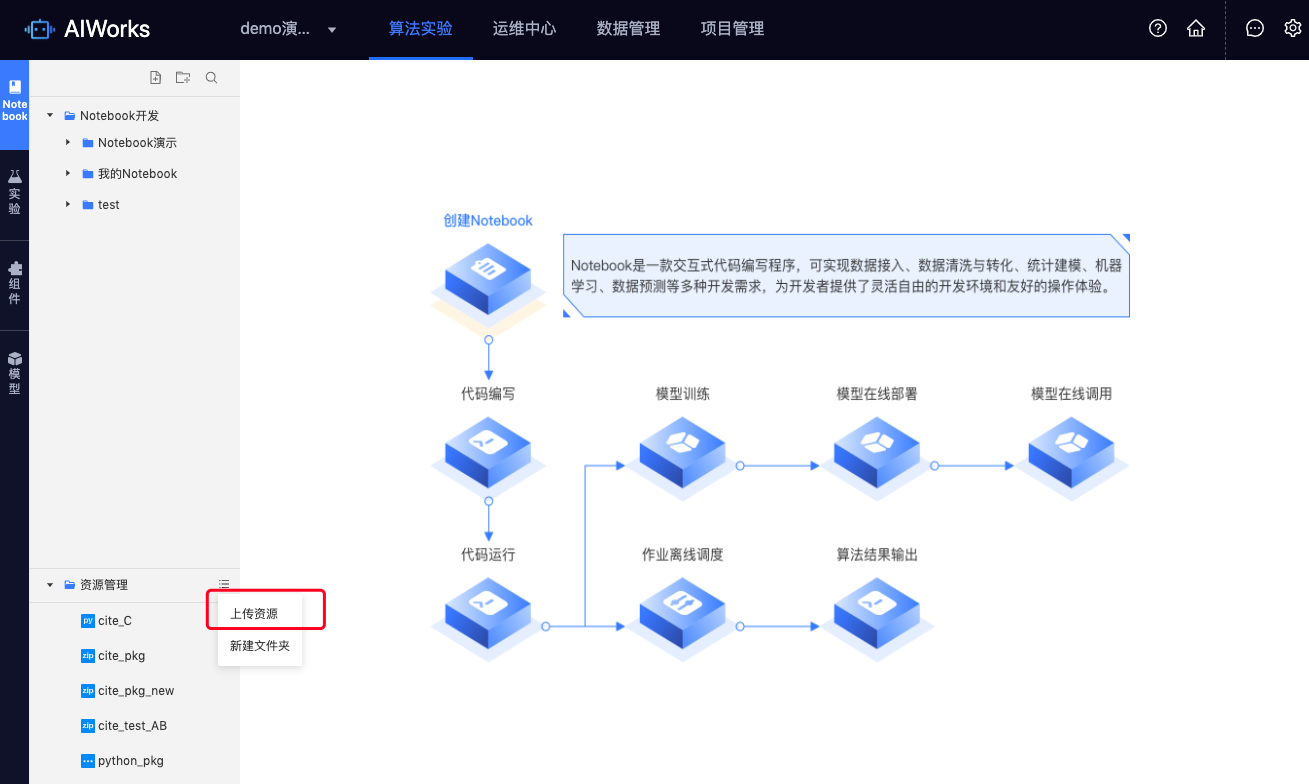
-
资源名称:由字母、数字、下划线组成,不超过64个字符;
-
资源类型:可选.py、.zip文件,单选;
-
选择文件:可从本地文件中选择对应类型的文件;
-
选择存储位置:选择需要存的文件夹;
-
描述:除空格外,其余字符格式均支持,不超过200个字符;
| 已上传的资源暂时不支持修改,可删除。 |
使用资源
资源使用有2种:
1. 本地开发的python文件与工程,利用统一的算法环境运行、管理。+
步骤一:在算法开发-Notebook-资源管理目录下上传本地文件;+
步骤二:创建Notebook任务,创建时,操作模式选择资源上传方式,选择对应的资源;
* 参数:该参数是传在资源的main文件中的函数,支持系统封装的内置参数或自定义参数,如${bdp.system.bizdate}。
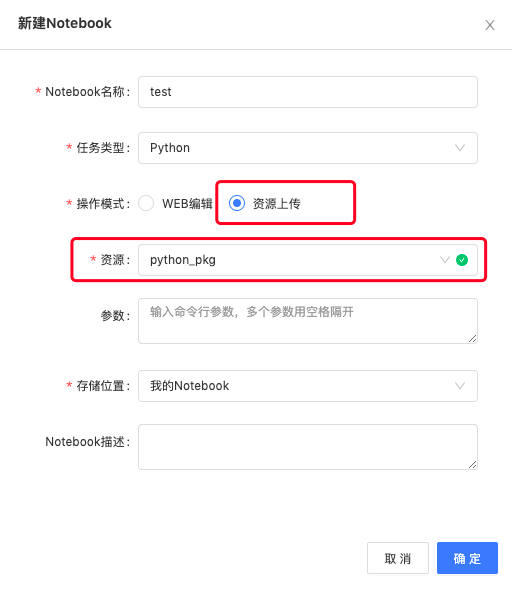
步骤三:创建好任务后,可点击运行,查看运行日志与结果。
步骤四:右侧面板配置任务调度参数、环境参数,可提交至调度系统周期性运行。
| 资源上传的任务暂不支持模型在线部署。 |
-
算法包的上传也可以使用该功能,并依据上述第1种情况。下文讲解如何进行算法包的引用:
步骤一:按照第一种情况的步骤将算法包上传至资源管理中,并通过一个任务引用该算法包,将算法包与任务关联起来;
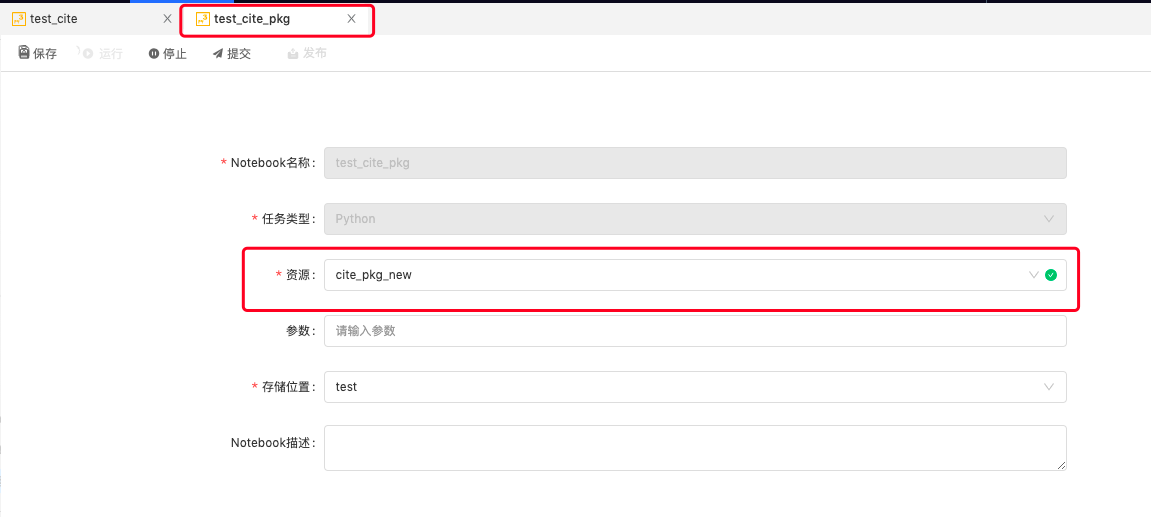
步骤二:在某个代码中,在右侧面板任务参数-模块间引用中配置该任务的引用任务,添加步骤一创建的算法任务,以达到引用算法包的目的;
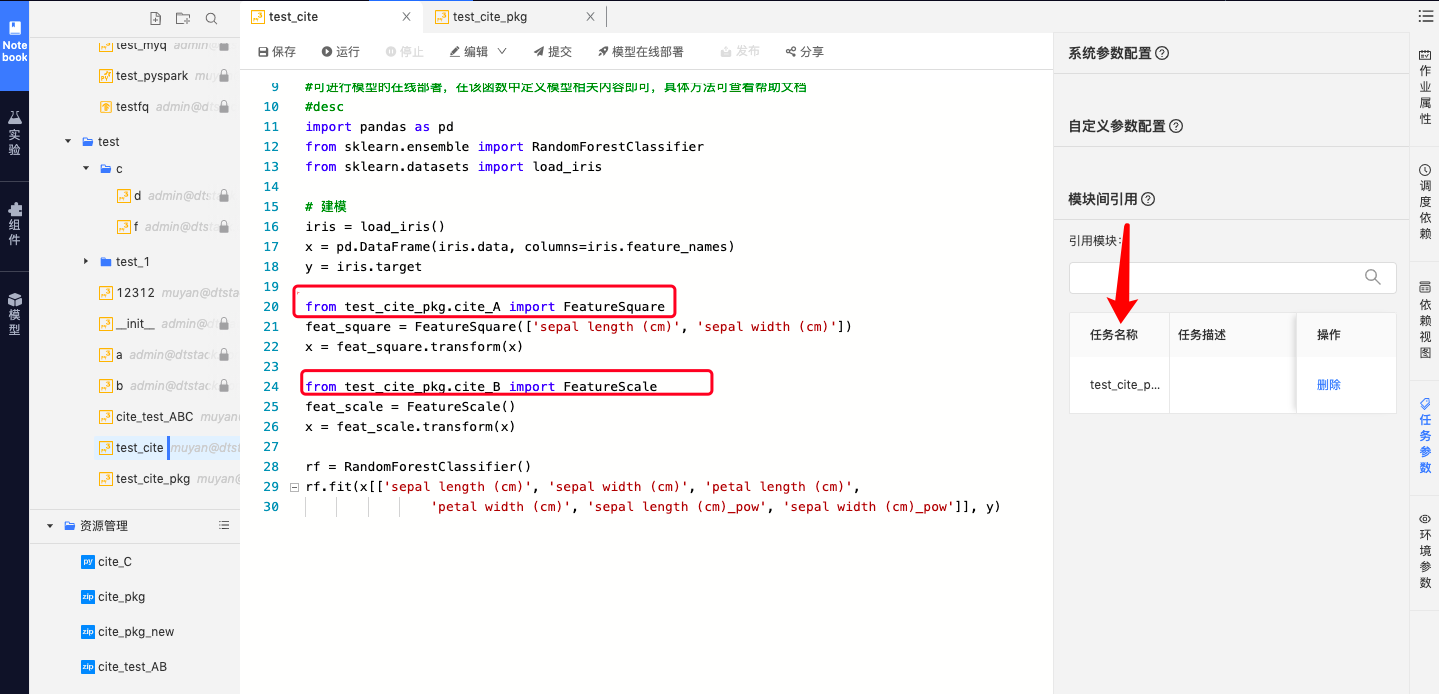
| 若引用某个算法包的子文件,进行from…import…时,需要输入子文件的文件路径,拼接路径为”${任务名称}.${算法包的子文件名称}}“,如此拼接的原因是算法平台会将上传的算法包名称替换成器关联的任务名称,进行引用,故需按照此路径拼接。 |
步骤四:代码编写完成后,可点击运行,试运行效果。该任务可提交调度进行周期性运行,但不能在线部署产出的模型。
测试案例
1、创建算法包内容;

(1)main.py
# encoding: utf-8
if __name__ == '__main__':
print("This is cite package")(2)cite_A.py
import pandas as pd
class FeatureSquare:
def __init__(self, col):
self.col = col
def transform(self, data):
for col in self.col:
data[f'{col}_pow'] = data[col].apply(lambda x: x ** 2)
return data(3)cite_B.py
import pandas as pd
class FeatureScale:
def __init__(self):
pass
def transform(self, data: pd.DataFrame):
data = (data - data.min()) / (data.max() - data.min())
return data2、将以上内容打成一个压缩包上传至算法平台的资源管理处;
3、创建一个任务引用该资源,使任务与该资源关联;
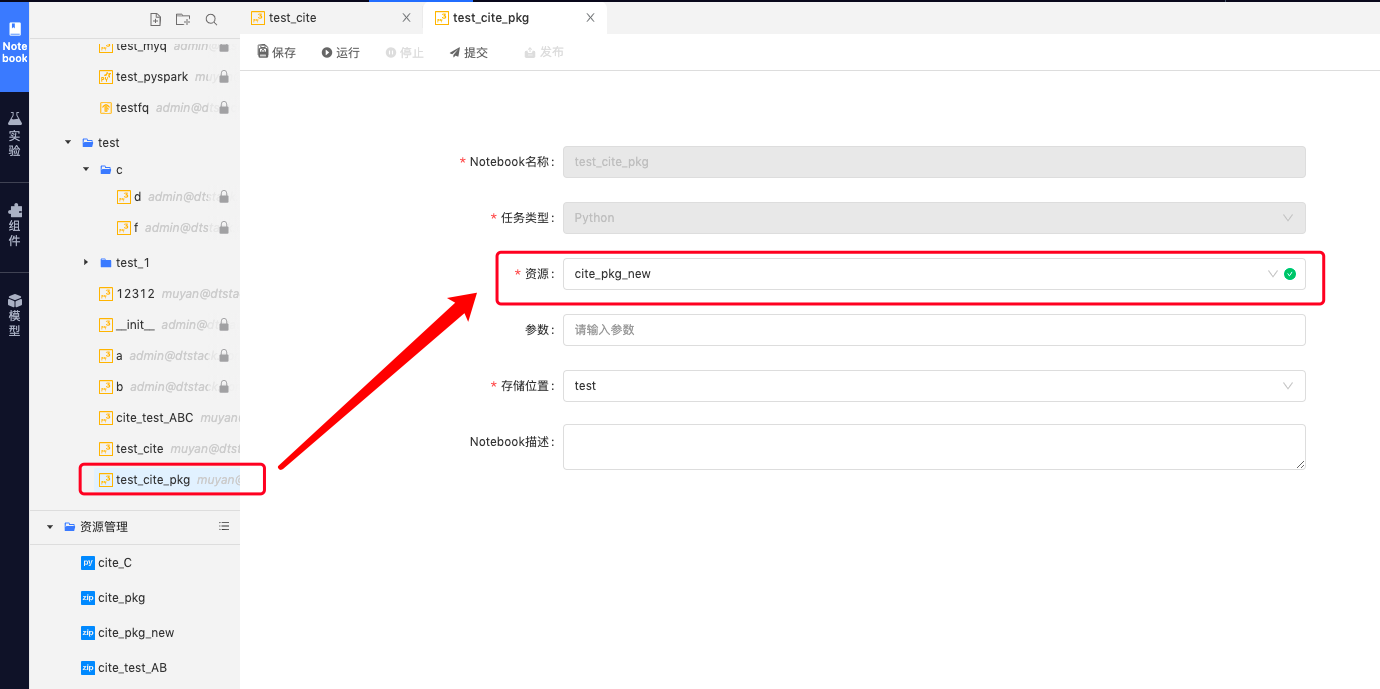
4、创建另一个任务引用上述任务(在该任务在),从而达到引用算法包的目的;
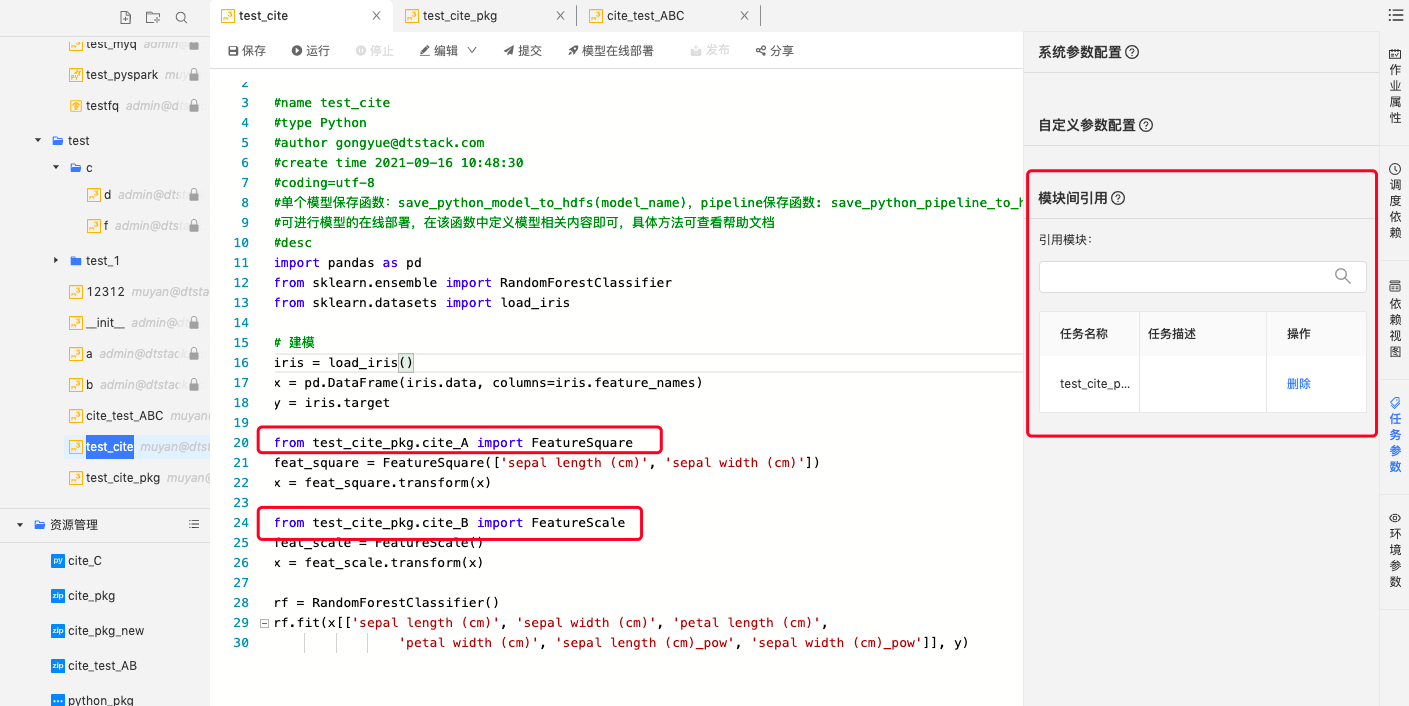
代码示例:
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_iris
iris = load_iris()
x = pd.DataFrame(iris.data, columns=iris.feature_names)
y = iris.target
from test_cite_pkg.cite_A import FeatureSquare
feat_square = FeatureSquare(['sepal length (cm)', 'sepal width (cm)'])
x = feat_square.transform(x)
from test_cite_pkg.cite_B import FeatureScale
feat_scale = FeatureScale()
x = feat_scale.transform(x)
rf = RandomForestClassifier()
rf.fit(x[['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)',
'petal width (cm)', 'sepal length (cm)_pow', 'sepal width (cm)_pow']], y)5、 运行以上代码,查看效果。