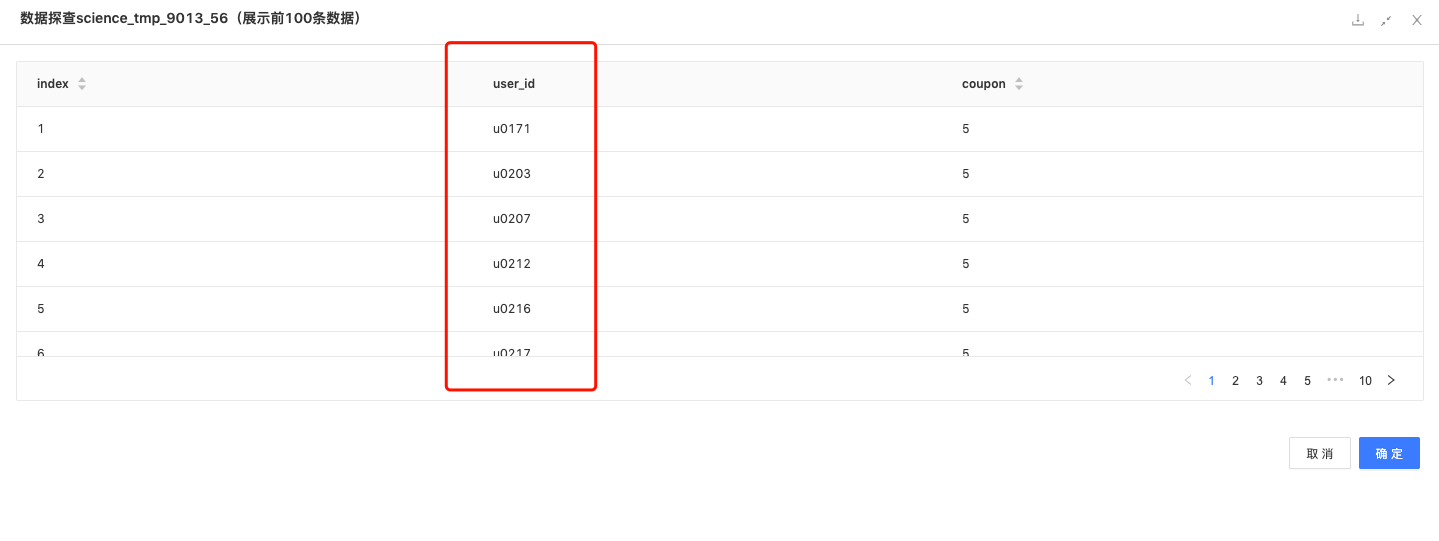
智能发券
实验基础信息
-
实验名称:智能发券
-
实验英文名:IntelligentIssuance
-
所属类目:新零售
-
实验描述:通过RFM模型对用户进行分群,并建立模型预测用户的购买概率,实现对不同用户群组下的不同购买率用户实行不同的发券策略。
-
主要应用算法:K-Means聚类、XGB分类
数据说明
-
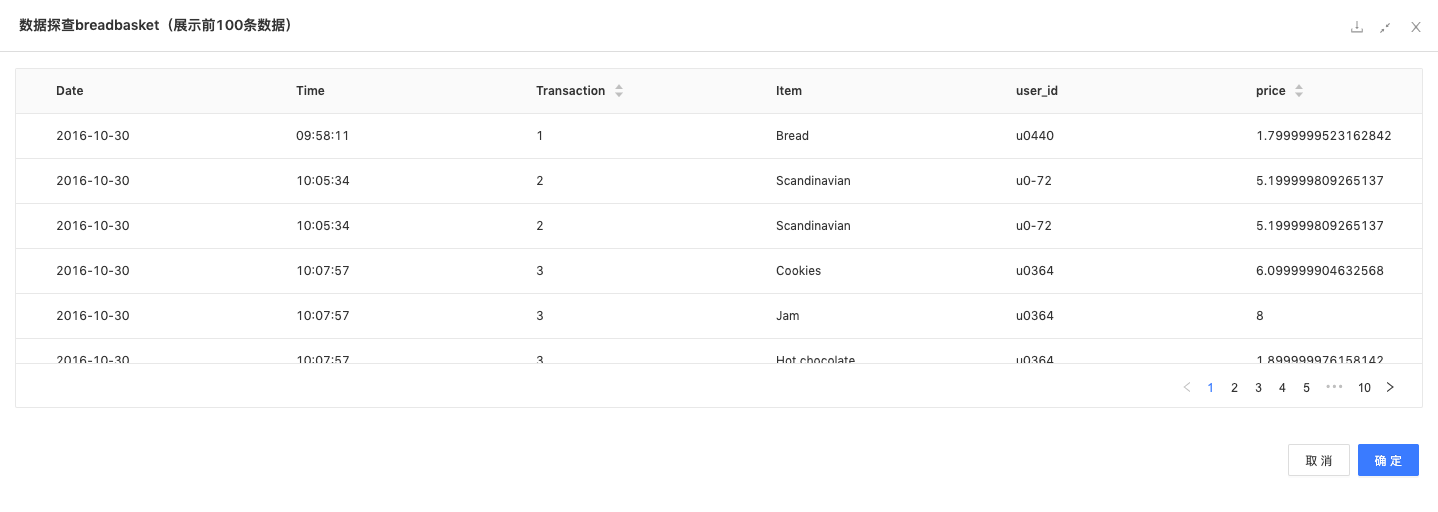
数据来源:Kaggle breadbasket比赛数据,一个面包房的交易数据,其中价格为人造数据。
-
数据属性:结构化数据,属于交易数据。
-
数据详情:数据集包含交易日期、交易具体时间、单号、产品、用户id、价格6列数据。
实验搭建
实验整体流程如下:
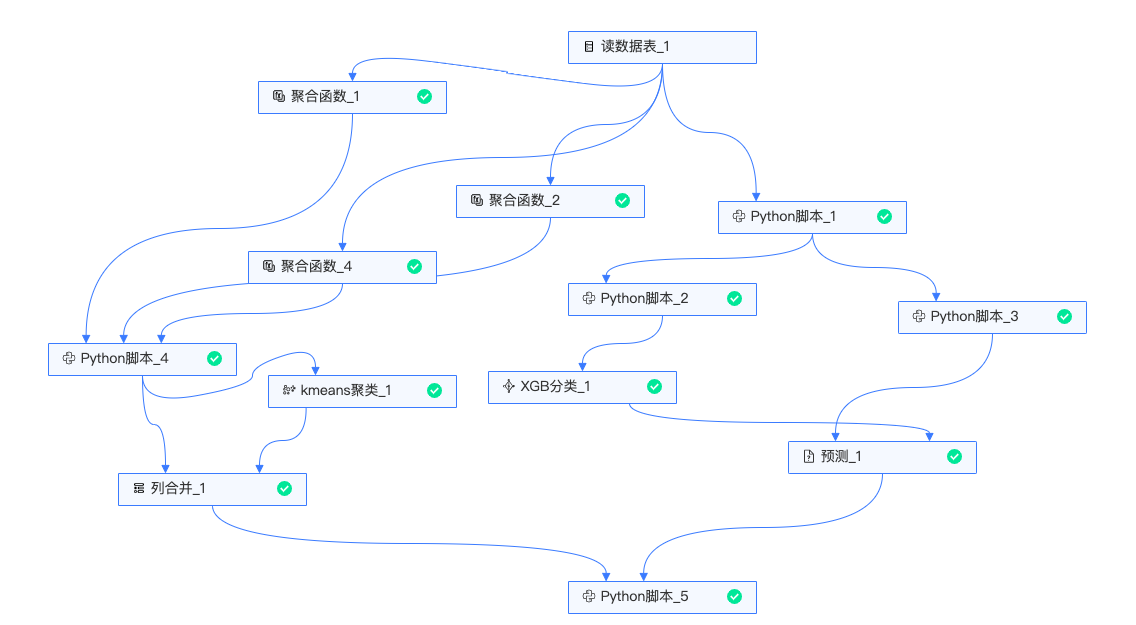
-
读入数据:读入原始数据;
左侧分支(RFM用户分层模型):
-
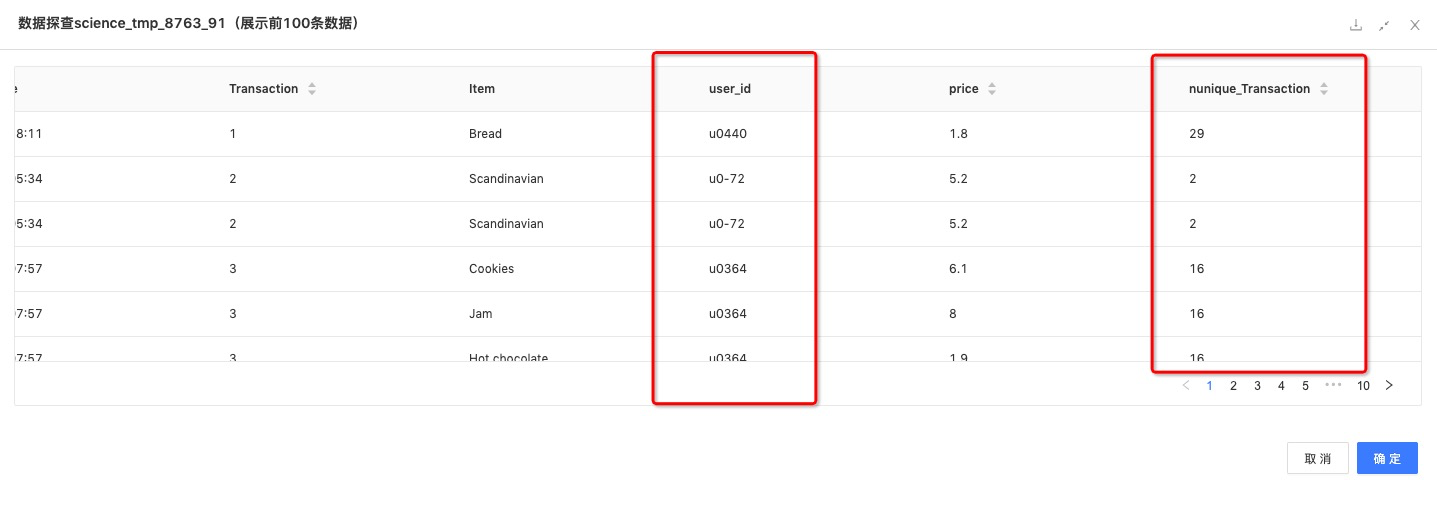
聚合函数:对user_id进行Groupby求nunique,得到每个用户的历史交易次数。

数据结果:
-
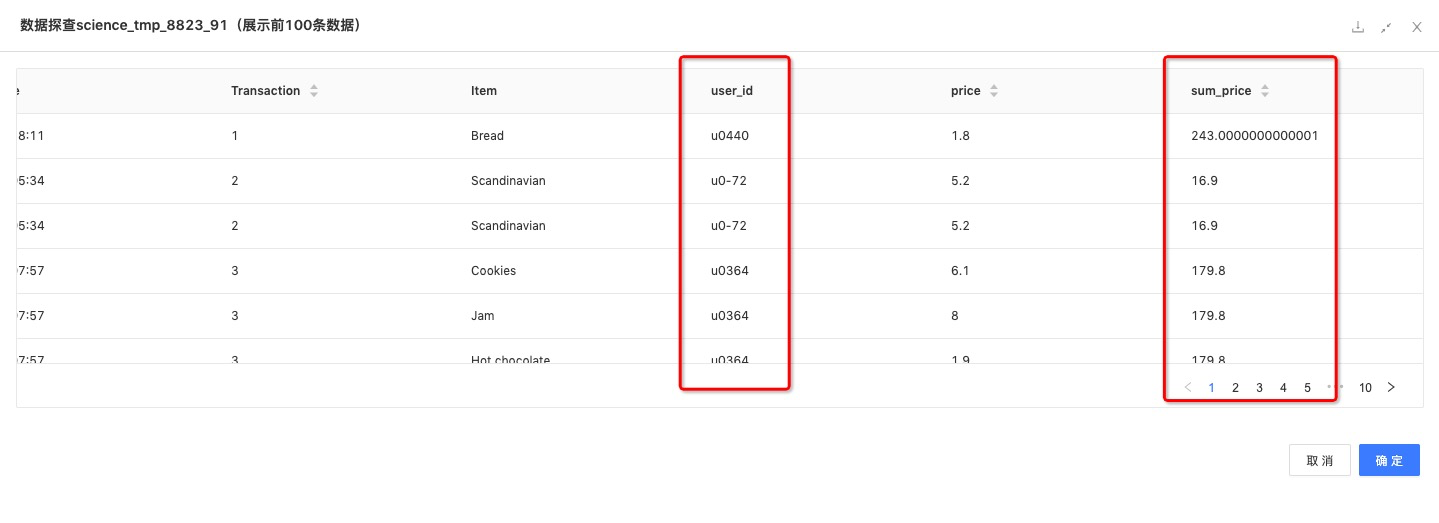
聚合函数:对user_id进行Groupby求sum,得到每个用户的历史交易总金额。

数据结果:
-
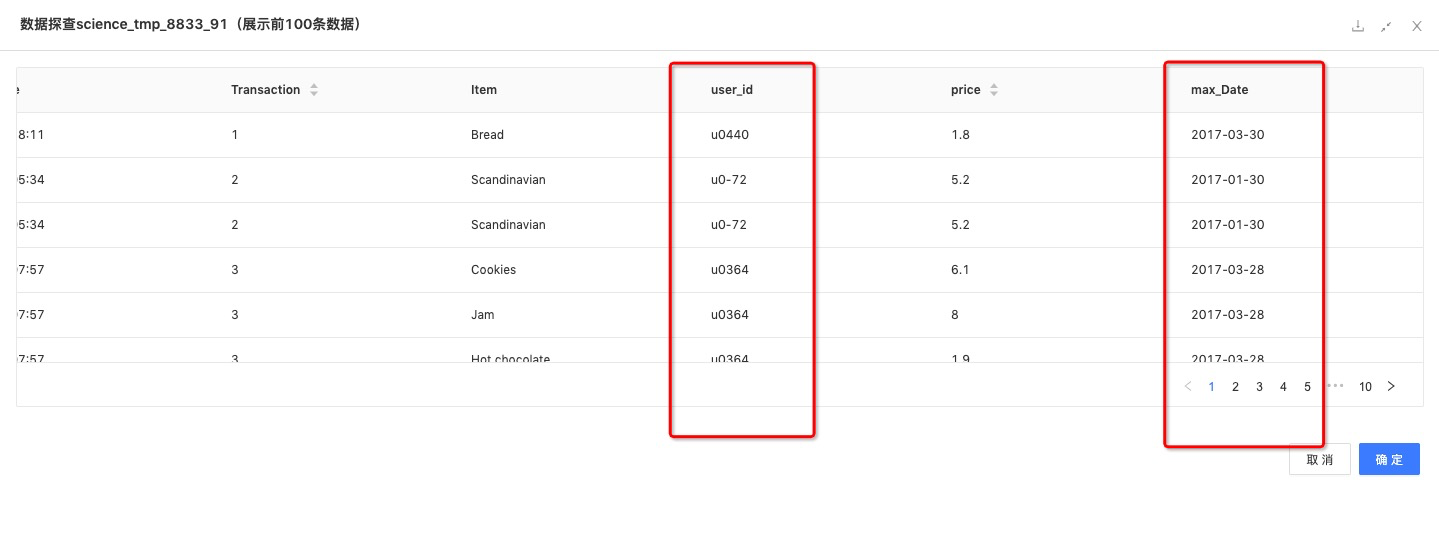
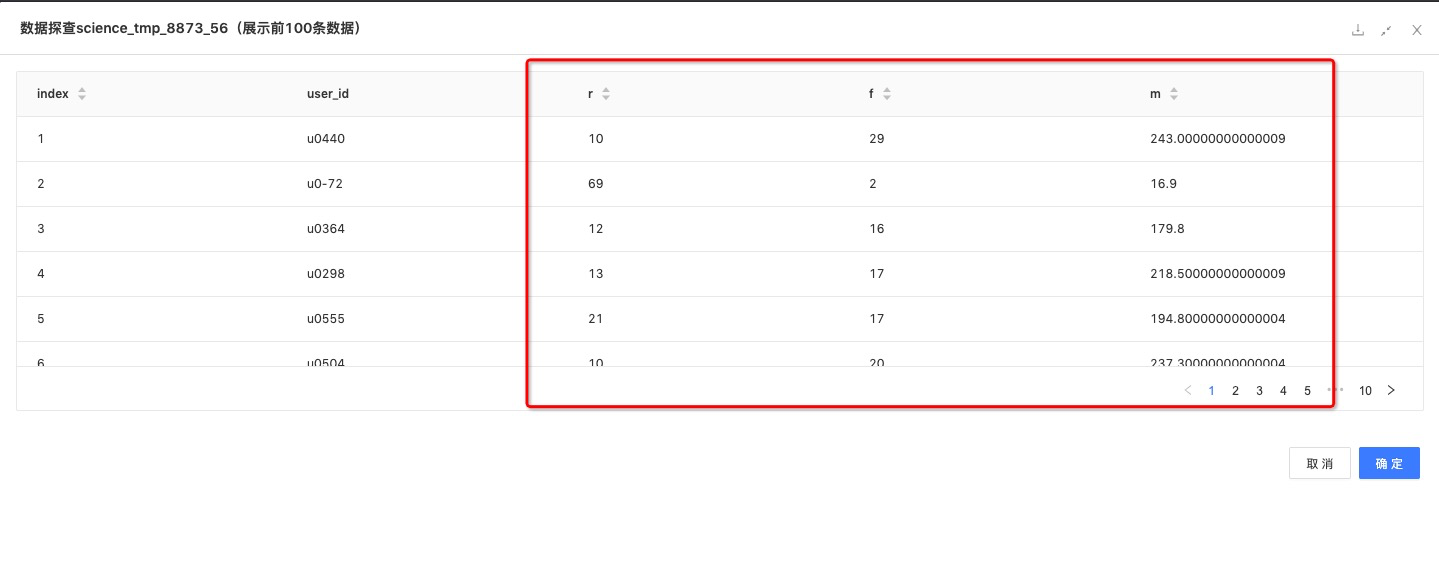
聚合函数:根据每个用户交易时间的最大值,取得每个用户最后一次交易时间。
数据结果:
-
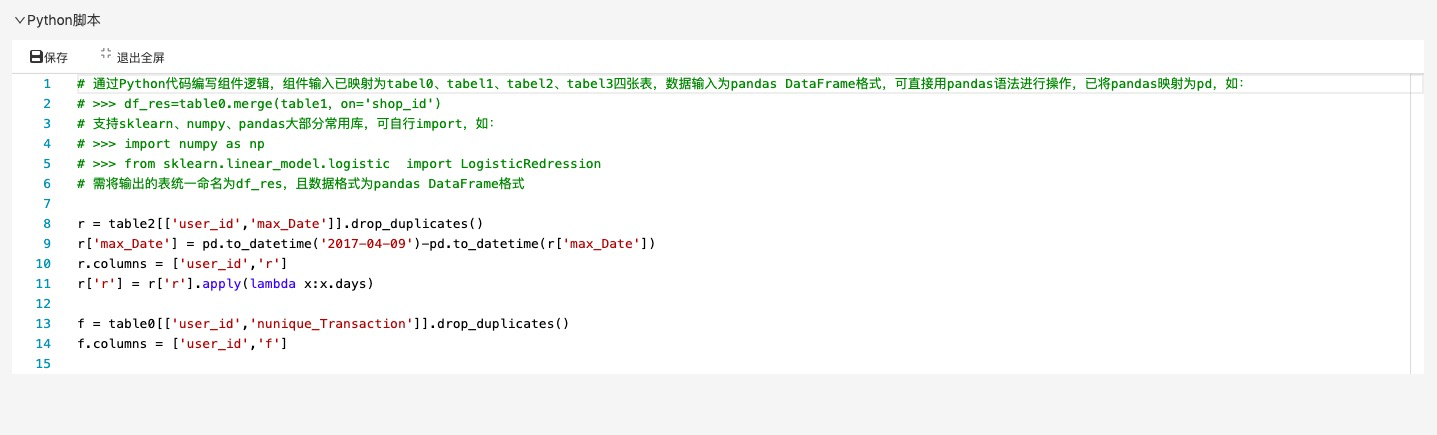
Python脚本,对第3步的结构加工,得到每个用户最后一次交易时间到现在的间隔时间,然后再将第1、2步中的数据拼接。
-
R:Recency,最近一次消费,指上一次购买的时间;
-
F:Frequency,消费频率,指顾客在限定的期间内所购买的次数;
-
M:Monetary,消费金额,指一段时间内的消费金额;
-
数据结果:
-
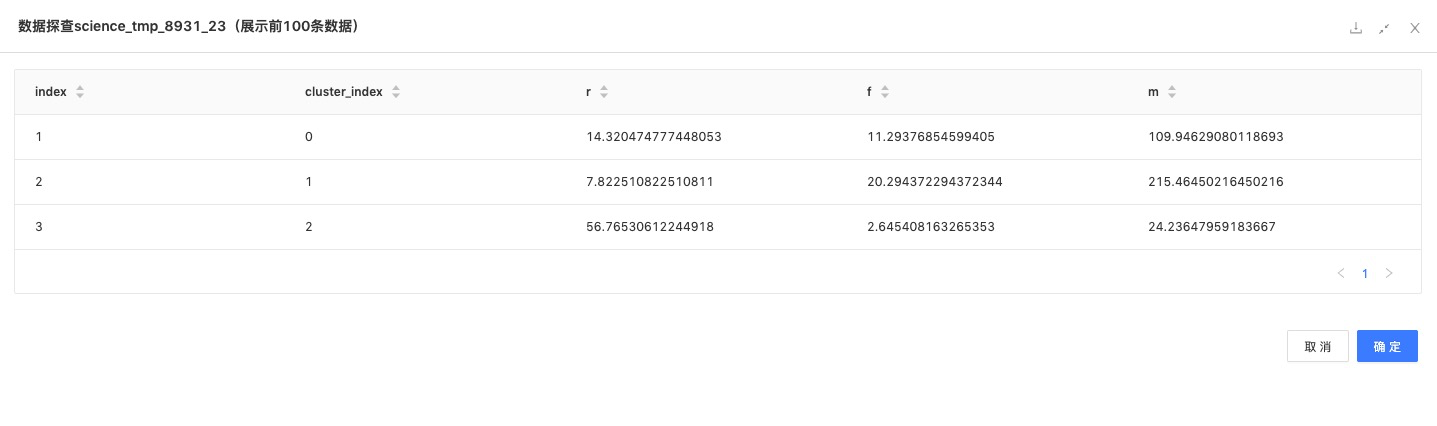
K-Means聚类:利用K-Means聚类算法,以样本间距离为基础,将n个对象分为k个簇,使群体与群体之间的距离尽量大,而簇内具有较高的相似度,此实验中得到3类用户。
右侧分支:
-
Python脚本:类似前面的步骤,直接得到“r”,“f”,“m”的特征。
df_m = table0[table0['Date']>='2017-01-08']
df_m['Date'] = pd.to_datetime(df_m['Date'])
df_m = df_m.groupby(['Date','user_id'])[['price']].sum().reset_index()
date = df_m['Date'].unique()
user = df_m['user_id'].unique()
from itertools import product
df_tmp = pd.DataFrame(product(date,user))
df_tmp.columns = ['Date','user_id']
df_m = df_m.merge(df_tmp,on=['user_id','Date'],how='right').sort_values(by=['Date','user_id'])
df_m['label'] = 0
df_m.loc[df_m['price']==df_m['price'],'label'] = 1
df_m['price'] = df_m['price'].fillna(0)
def fill_r(x):
if x is pd.NaT:
return -999
else:
return x.days
tmp = df_m[df_m.label==1]
tmp['r'] = tmp.groupby('user_id')['Date'].diff()
tmp['r'] = tmp['r'].apply(fill_r)
tmp['m'] = tmp.groupby('user_id')['price'].agg('cumsum')
tmp['f'] = tmp.groupby('user_id')['price'].agg('cumcount')
df_m = df_m.merge(tmp[['Date','user_id','r','f','m']],on=['Date','user_id'],how='left')
df_res = df_m.fillna(-999)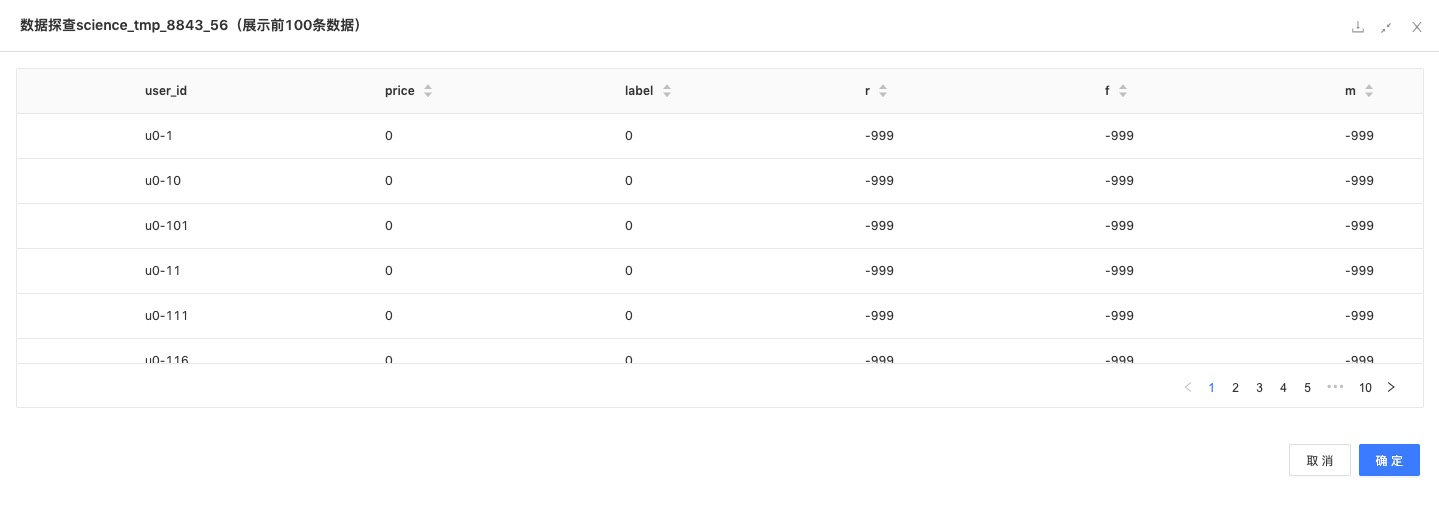
-
Python脚本:将过去30天数据作为训练集。

-
Python脚本:将今天的数据作为需要预测的数据集。

-
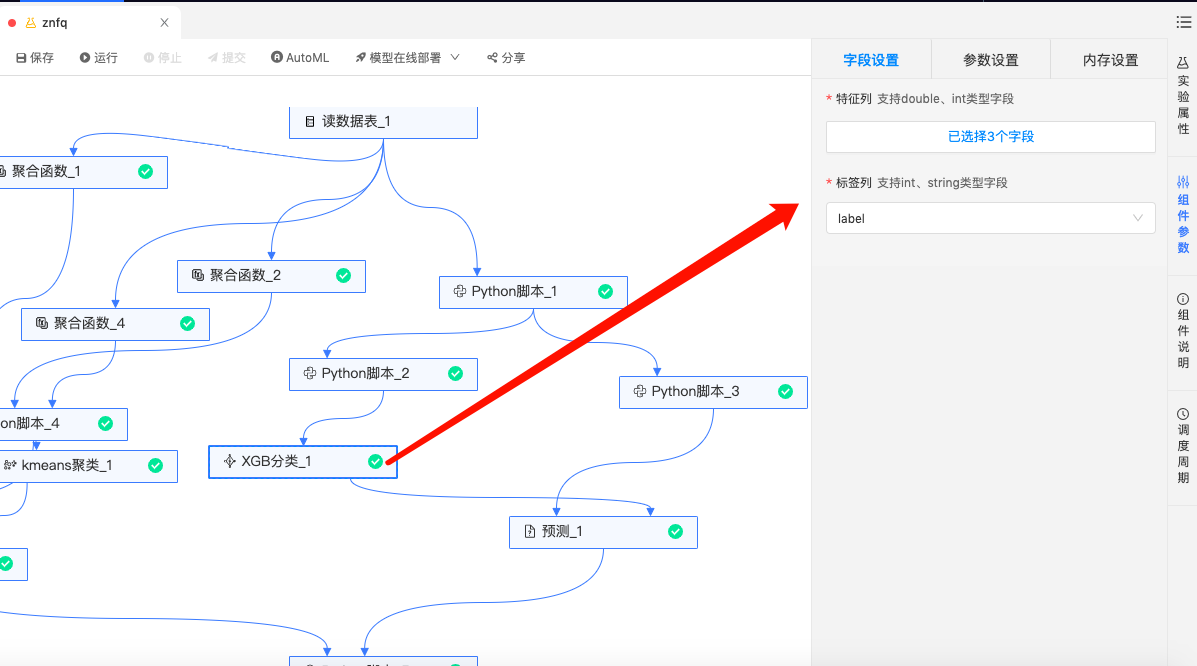
XGB分类:训练一个预测用户是否会购买的模型。
-
预测:用训练好的XGB模型去预测今天的数据,预测结果如下:
RFM+XGB:筛选目标用户
选取RFM模型中“高价值”的用户(交易次数多、交易金额高、最近一次购买时间近),且被XGB模型预测到今天不会购买的进行发券。

数据结果: