数据集准备
进入某具体项目中,在数据管理页面接入数据,数据接入包含2种方式:
1. 数据库接入;
2. 本地数据接入;
数据库接入
每个项目底层对应一个Hive库,Hive库的名称、连接地址可在页面中看到,若需读入其他数据库的数据进行数据建模,如MySQL、Oracle、GreenPlum等,则需将数据库的数据同步至目标Hive库,可采用离线开发产品的数据集成模块来完成。
数据同步使用方法详见 数据集成

| 若项目创建方式为"对接已有SparkThriftServer",后续源库中若有新增表/删除表,则需点击Hive数据库中同步元数据按钮,将Hive库的元数据同步至算法开发平台,以便实验建模时读取元数据。 |
本地数据接入
若需要本地数据进行测试,点击上传数据,将数据写入Hive表中,步骤如下:
步骤一:点击上传数据按钮,选择需要上传的本地文件,目前支持CSV、TXT格式;
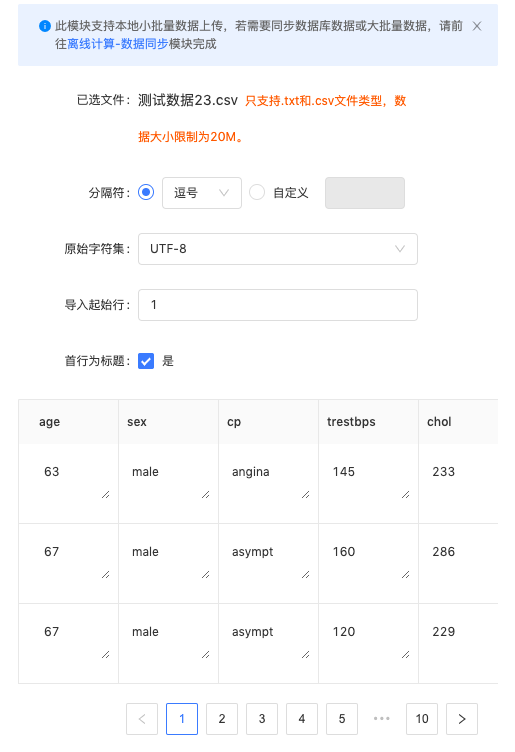
步骤二:选择数据分隔符、原始字符集格式、导入起始行等信息;
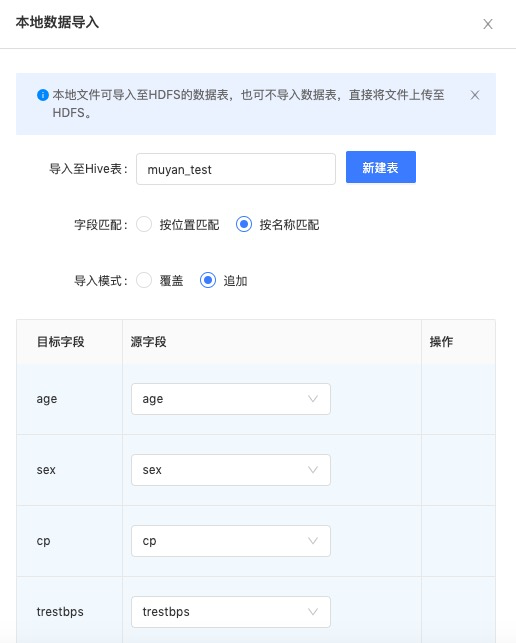
步骤三:选择导入的Hive表,并可一键建表。选择字段匹配方式、与导入模式;
-
一键建表:系统会自动读取上传数据的字段,生成建表语句,用户对建表语句中的表名称、表格式、表生命周期进行调整即可。
-
字段匹配
-
按位置匹配:将上传数据与表字段,按照顺序进行匹配,相应的数据写到相应的字段下面。
-
按名称匹配:将上传数据的表头或Key,按照与表字段名称匹配,进行数据写入。
-
-
导入模式
-
追加:新增数据追加在表后面。
-
覆盖:新增数据覆盖原表数据。
-
经过以上步骤,并已将数据导入至项目的数据库中,下一步可进入算法建模阶段。