自定义Python组件
AIWorks目前已封装了近百余种组件,但客户的使用场景多样,可能会没有封装到有些客户需要用的组件,故封装自定义组件的框架,可让用户自行实现组件封装。
新增组件
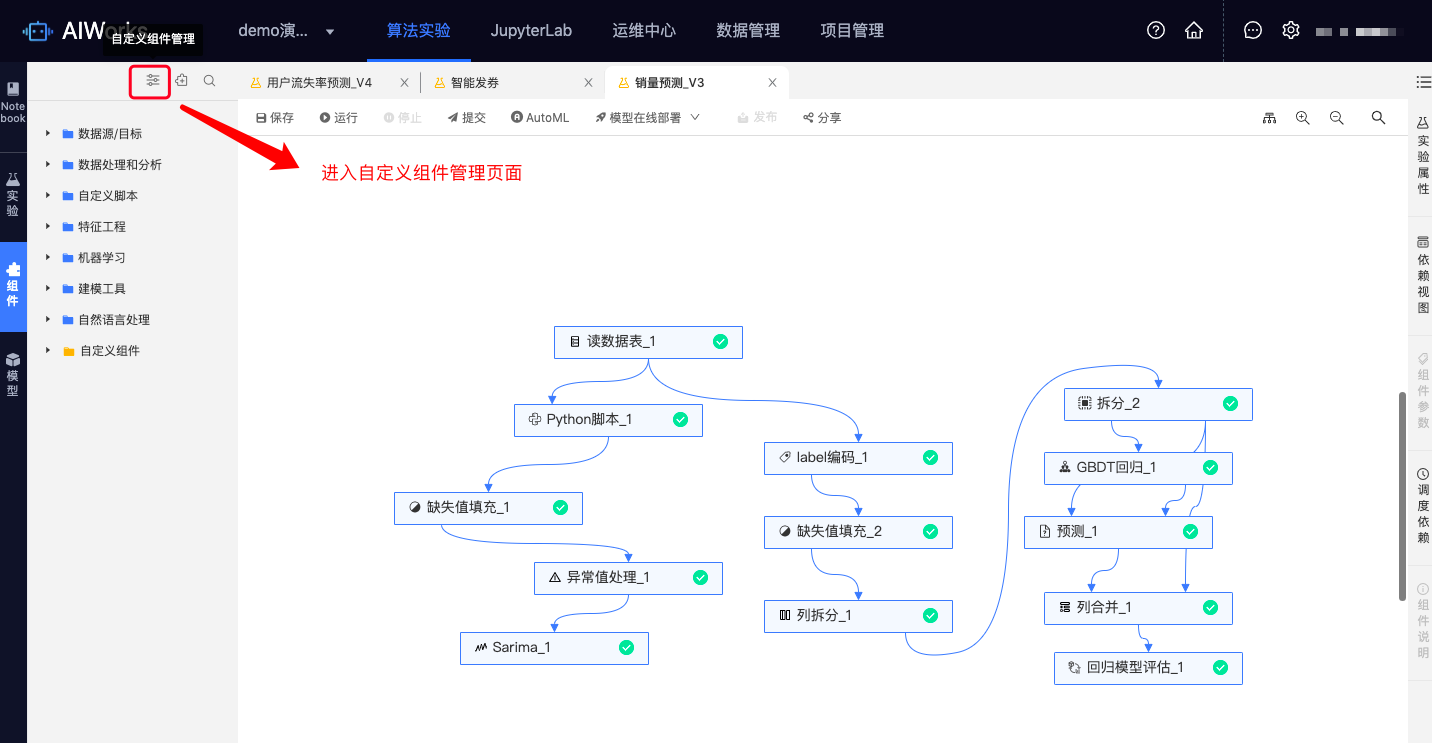
步骤一:在算法开发导航下的实验的左侧列表上方,点击自定义组件管理页面进入相应页面。或者直接通过自定义组件按钮直接进入新增页面;
步骤二:填写组件相关信息;

-
组件名称:除空格外其余字符均支持,不超过64个字符;
-
所属分类:选中一个自定义的类目,该类目可自定义,单选;
-
组件类型:目前只支持单机版(Python);+
-
组件特征:分为数据处理类、特征工程类(带模型训练)、特征工程类(不带模型训练)、机器学习类;
-
组件说明:填写组件说明信息,除空格外其余字符均支持,不超过200个字符;
封装方法:
1.数据处理类
# 自定义组件输入桩最多包含4个,table0、tabel1、table2、table3,可通过import get_data方法灵活引用。需注意,届时自定义组件在实验中的真实输入个数需与代码中一致,需要几个输入代码中引用几个即可。
"""
from aiworks_plugins.hdfs_plugins.utils import get_data
df0 = get_data(0)
df1 = get_data(1)
df2 = get_data(2)
df3 = get_data(3)
"""
# 自定义组件输出桩最多包含4个,3个输出数据,1个输出模型。保存数据和模型的方法详见帮助文档示例。
# 数据处理类组件模板如下,需符合平台的接口规范,需实现transform和run的方法,在下方模板中补充自己需要实现的代码即可。
import pandas as pd
from aiworks_plugins.hdfs_plugins.utils import get_data
from aiworks_plugins.hdfs_plugins.utils import save_model, save_data
class CustomModel:
def __init__(self):
### START CODE HERE ###
### END CODE HERE ###
pass
def transform(self, data: pd.DataFrame) -> pd.DataFrame:
### START CODE HERE ###
### END CODE HERE ###
pass
def run(self):
df0 = get_data(0)
res = self.transform(df0)
save_data(res, 0)
save_model(self)
if __name__ == '__main__':
model = CustomModel()
model.run()2.特征工程类(不带训练)模板
# 自定义组件输入桩最多包含4个,table0、tabel1、table2、table3,可通过import get_data方法灵活引用。需注意,届时自定义组件在实验中的真实输入个数需与代码中一致,需要几个输入代码中引用几个即可。
"""
from aiworks_plugins.hdfs_plugins.utils import get_data
df0 = get_data(0)
df1 = get_data(1)
df2 = get_data(2)
df3 = get_data(3)
"""
# 自定义组件输出桩最多包含4个,3个输出数据,1个输出模型。保存数据和模型的方法详见帮助文档示例。
# 特征工程类(不带训练)组件模板如下,需要符合平台的接口规范,需实现transform、run的方法,在下方模板中补充自己需要实现的代码即可。
import pandas as pd
from aiworks_plugins.hdfs_plugins.utils import get_data
from aiworks_plugins.hdfs_plugins.utils import save_model, save_data
class CustomModel:
def __init__(self):
### START CODE HERE ###
### END CODE HERE ###
pass
def transform(self, data: pd.DataFrame) -> pd.DataFrame:
### START CODE HERE ###
### END CODE HERE ###
pass
def run(self):
df0 = get_data(0)
res = self.transform(df0)
save_data(res, 0)
save_model(self)
if __name__ == '__main__':
model = CustomModel()
model.run()3.特征工程类(带训练)模板
# 自定义组件输入桩最多包含4个,table0、tabel1、table2、table3,可通过import get_data方法灵活引用。需注意,届时自定义组件在实验中的真实输入个数需与代码中一致,需要几个输入代码中引用几个即可。
'''
from aiworks_plugins.hdfs_plugins.utils import get_data
df0 = get_data(0)
df1 = get_data(1)
df2 = get_data(2)
df3 = get_data(3)
'''
# 自定义组件输出桩最多包含4个,3个输出数据,1个输出模型。保存数据和模型的方法详见帮助文档示例。
# 特征工程类组件(带训练)模板如下,需符合平台的接口规范,需实现fit、transform、run的方法,在下方模板中补充自己需要实现的代码即可。
import pandas as pd
from aiworks_plugins.hdfs_plugins.utils import get_data
from aiworks_plugins.hdfs_plugins.utils import save_model, save_data
class CustomModel:
def __init__(self):
### START CODE HERE ###
### END CODE HERE ###
pass
def fit(self, data: pd.DataFrame) -> None:
### START CODE HERE ###
### END CODE HERE ###
pass
def transform(self, data: pd.DataFrame) -> pd.DataFrame:
### START CODE HERE ###
### END CODE HERE ###
pass
def run(self):
df0 = get_data(0)
self.fit(df0)
res = self.transform(df0)
save_data(res, 0)
save_model(self)
if __name__ == '__main__':
model = CustomModel()
model.run()4.机器学习(分类)模板
# 自定义组件输入桩最多包含4个,table0、tabel1、table2、table3,可通过import get_data方法灵活引用。需注意,届时自定义组件在实验中的真实输入个数需与代码中一致,需要几个输入代码中引用几个即可。
"""
from aiworks_plugins.hdfs_plugins.utils import get_data
df0 = get_data(0)
df1 = get_data(1)
df2 = get_data(2)
df3 = get_data(3)
"""
# 自定义组件输出桩最多包含4个,3个输出数据,1个输出模型。保存数据和模型的方法详见帮助文档示例。
# 机器学习分类组件需实现
# 机器学习类(分类)组件模板如下,需在类属性中定义模型类别"classifier",且实现fit、predict、predict_proba、run的方法,在下方模板中补充自己需要实现的代码即可。
import pandas as pd
from aiworks_plugins.hdfs_plugins.utils import get_data
from aiworks_plugins.hdfs_plugins.utils import save_model, save_data
class CustomModel:
def __init__(self):
self._estimator_type = "classifier"
def fit(self, data: pd.DataFrame) -> None:
### START CODE HERE ###
### END CODE HERE ###
pass
def predict(self, data: pd.DataFrame) -> pd.DataFrame:
### START CODE HERE ###
### END CODE HERE ###
pass
def predict_proba(self, data: pd.DataFrame) -> pd.DataFrame:
### START CODE HERE ###
### END CODE HERE ###
pass
def run(self):
df0 = get_data(0)
self.fit(df0)
res = self.predict(df0)
save_data(res, 0)
save_model(self)
if __name__ == '__main__':
model = CustomModel()
model.run()5.机器学习(聚类)模板
# 自定义组件输入桩最多包含4个,table0、tabel1、table2、table3,可通过import get_data方法灵活引用。需注意,届时自定义组件在实验中的真实输入个数需与代码中一致,需要几个输入代码中引用几个即可。
"""
from aiworks_plugins.hdfs_plugins.utils import get_data
df0 = get_data(0)
df1 = get_data(1)
df2 = get_data(2)
df3 = get_data(3)
"""
# 自定义组件输出桩最多包含4个,3个输出数据,1个输出模型。保存数据和模型的方法详见帮助文档示例。
# 机器学习分类组件需实现
# 机器学习类(聚类)组件模板如下,需在类属性中定义模型类别"clusterer",且实现fit、predict、run的方法,在下方模板中补充自己需要实现的代码即可。
import pandas as pd
from aiworks_plugins.hdfs_plugins.utils import get_data
from aiworks_plugins.hdfs_plugins.utils import save_model, save_data
class CustomModel:
def __init__(self):
self._estimator_type = "clusterer"
def fit(self, data: pd.DataFrame) -> None:
### START CODE HERE ###
### END CODE HERE ###
pass
def predict(self, data: pd.DataFrame) -> pd.DataFrame:
### START CODE HERE ###
### END CODE HERE ###
pass
def run(self):
df0 = get_data(0)
self.fit(df0)
res = self.predict(df0)
save_data(res, 0)
save_model(self)
if __name__ == '__main__':
model = CustomModel()
model.run()6.机器学习(回归)模板
# 自定义组件输入桩最多包含4个,table0、tabel1、table2、table3,可通过import get_data方法灵活引用。需注意,届时自定义组件在实验中的真实输入个数需与代码中一致,需要几个输入代码中引用几个即可。
"""
from aiworks_plugins.hdfs_plugins.utils import get_data
df0 = get_data(0)
df1 = get_data(1)
df2 = get_data(2)
df3 = get_data(3)
"""
# 自定义组件输出桩最多包含4个,3个输出数据,1个输出模型。保存数据和模型的方法详见帮助文档示例。
# 机器学习分类组件需实现
# 机器学习类(回归)组件模板如下,需在类属性中定义模型类别"regressor",且实现fit、predict、run的方法,在下方模板中补充自己需要实现的代码即可。
import pandas as pd
from aiworks_plugins.hdfs_plugins.utils import get_data
from aiworks_plugins.hdfs_plugins.utils import save_model, save_data
class CustomModel:
def __init__(self):
self._estimator_type = "regressor"
def fit(self, data: pd.DataFrame) -> None:
### START CODE HERE ###
### END CODE HERE ###
pass
def predict(self, data: pd.DataFrame) -> pd.DataFrame:
### START CODE HERE ###
### END CODE HERE ###
pass
def run(self):
df0 = get_data(0)
self.fit(df0)
res = self.predict(df0)
save_data(res, 0)
save_model(self)
if __name__ == '__main__':
model = CustomModel()
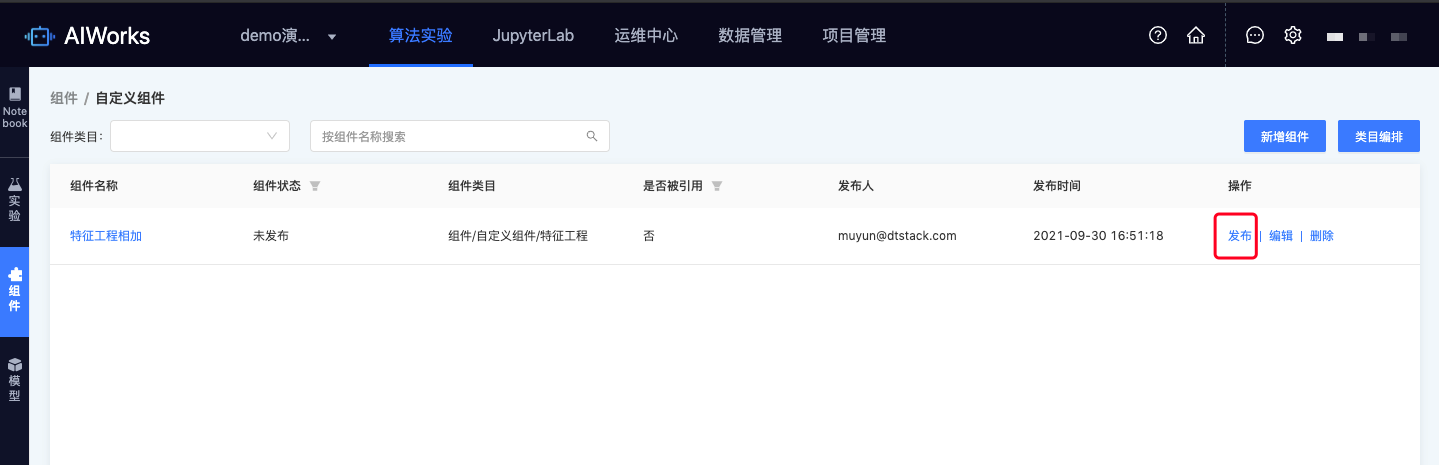
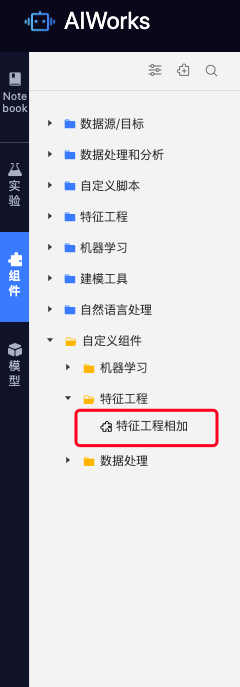
model.run()根据以上模板封装自定义组件的逻辑,进行保存。
代码样例
以下是几个自定义组件的示例:
1.特征工程类(带训练)组件
最大最小归一化组件:
import pandas as pd
from aiworks_plugins.hdfs_plugins.utils import get_data
from aiworks_plugins.hdfs_plugins.utils import save_model, save_data
from sklearn.preprocessing import MinMaxScaler
"""
这里调用了sklearn的MinMaxScaler作为展示,你也可以自己灵活实现模型。
"""
class CustomModel:
def __init__(self):
self.col = ['sepal length (cm)']
self.model = MinMaxScaler()
def fit(self, data: pd.DataFrame) -> None:
self.model.fit(data[self.col])
def transform(self, data: pd.DataFrame) -> pd.DataFrame:
data['new_col'] = self.model.transform(data[self.col])
return data
def run(self):
df0 = get_data(0)
self.fit(df0)
res = self.transform(df0)
save_data(res, 0)
save_model(self)
if __name__ == '__main__':
model = CustomModel()
model.run()2.机器学习类(分类)组件
自定义组件实现的FM分类算法组件:
from aiworks_plugins.hdfs_plugins.utils import get_data
from aiworks_plugins.hdfs_plugins.utils import save_model, save_data
import numpy as np
import pandas as pd
def compute_mse(y1, y2):
if len(y1) != len(y2):
raise ValueError("y1.length != y2.length")
y1 = list(y1)
y2 = list(y2)
return sum([(y1[i] - y2[i]) ** 2 for i in range(len(y1))]) / len(y1)
def sigmoid(x):
return 1.0 / (1.0 + np.exp(-x))
class FM:
def __init__(self, k=3, task_object='regression', max_iter=100, learning_rate=0.01, bias=0.01, verbose=True):
self.k = k
self.task_object = task_object
self.max_iter = max_iter
self.learning_rate = learning_rate
self.v = None
self.w = None
self.b = bias
self.verbose = verbose
def fit(self, x: np.ndarray, y: np.ndarray) -> None:
M, N = x.shape
self.v = np.random.normal(0, 0.1, [self.k, N])
self.w = np.random.normal(0, 0.1, N)
for _iter in range(self.max_iter):
dv = np.zeros([self.k, N])
dw = np.zeros(N)
db = 0
y_hat = self.predict(x)
if self.verbose:
print("################################")
print("iter{}, 训练误差:".format(_iter), compute_mse(y, y_hat))
for m in range(M):
diff = y[m] - y_hat[m]
dw += -0.5 * diff * x[m]
db += -0.5 * diff
dv += -0.5 * diff * (
np.matmul(np.matmul(self.v, x[m]).reshape(-1, 1), x[m].reshape(1, -1)) - x[m] ** 2 * self.v)
self.w -= self.learning_rate * dw / m
self.b -= self.learning_rate * db / m
self.v -= self.learning_rate * dv / m
def _product(self, x: np.ndarray):
"""
:param x: shape [1,n]
"""
res = 0
for k in range(self.v.shape[0]):
tmp = np.array([self.v[k][i] * x[i] for i in range(len(x))])
res += np.sum(tmp) ** 2 - np.sum(tmp ** 2)
return 0.5 * res
def _predict(self, x: np.ndarray):
"""
:param x: shape [1,n]
"""
return self.b + np.dot(x, self.w) + self._product(x)
def predict_proba(self, x: np.ndarray) -> np.ndarray:
if self.task_object == "regression":
raise KeyError("no probability in regression task")
return np.array([sigmoid(self._predict(x[i])) for i in range(len(x))])
def predict(self, x: np.ndarray) -> np.ndarray:
"""
:param x: shape [m,n]
"""
if self.task_object == "regression":
res = [self._predict(x[i]) for i in range(len(x))]
elif self.task_object == "classification":
temp = self.predict_proba(x)
res = (temp > 0.5) * 1
else:
raise KeyError("task_object should be regression or classification")
return np.array(res)
class CustomModel:
"""
这里选择的数据是sklearn内置的乳腺癌数据
"""
def __init__(self):
self._estimator_type = "classifier"
self.model = FM(k=15, learning_rate=0.03, task_object='classification')
self.col = ['mean_radius', 'mean_texture', 'mean_perimeter', 'mean_area',
'mean_smoothness', 'mean_compactness', 'mean_concavity',
'mean_concave_points', 'mean_symmetry', 'mean_fractal_dimension',
'radius_error', 'texture_error', 'perimeter_error', 'area_error',
'smoothness_error', 'compactness_error', 'concavity_error',
'concave_points_error', 'symmetry_error', 'fractal_dimension_error',
'worst_radius', 'worst_texture', 'worst_perimeter', 'worst_area',
'worst_smoothness', 'worst_compactness', 'worst_concavity',
'worst_concave_points', 'worst_symmetry', 'worst_fractal_dimension']
self.target = ['malignant']
self._max = None
self._min = None
def fit(self, data: pd.DataFrame) -> None:
x = data[self.col].as_matrix()
x_new = []
self._max = []
self._min = []
for col in range(x.shape[1]):
tmp = np.zeros([len(x), 16])
_max = max(x[:, col])
self._max.append(_max)
_min = min(x[:, col])
self._min.append(_min)
for row in range(x.shape[0]):
_ = int(round((x[row][col] - _min) / ((_max - _min) / 15), 0))
tmp[row, _] = 1
x_new.append(tmp)
x = np.concatenate(x_new, axis=1)
self.model.fit(x, data[self.target].as_matrix())
def predict(self, data: pd.DataFrame) -> pd.DataFrame:
x = data[self.col].as_matrix()
x_new = []
for col in range(x.shape[1]):
tmp = np.zeros([len(x), 16])
for row in range(x.shape[0]):
_ = int(round((x[row][col] - self._min[col]) / ((self._max[col] - self._min[col]) / 15), 0))
tmp[row, _] = 1
x_new.append(tmp)
x = np.concatenate(x_new, axis=1)
res = self.model.predict(x)
return pd.DataFrame(res, columns=['pre'])
def predict_proba(self, data: pd.DataFrame) -> pd.DataFrame:
x = data[self.col].as_matrix()
x_new = []
for col in range(x.shape[1]):
tmp = np.zeros([len(x), 16])
for row in range(x.shape[0]):
_ = int(round((x[row][col] - self._min[col]) / ((self._max[col] - self._min[col]) / 15), 0))
tmp[row, _] = 1
x_new.append(tmp)
x = np.concatenate(x_new, axis=1)
res = self.model.predict_proba(x)
return pd.DataFrame(res, columns=['proba'])
def run(self):
df0 = get_data(0)
self.fit(df0)
proba = self.predict_proba(df0)
pre = self.predict(df0)
save_data(proba, 0)
save_data(pre, 1)
save_model(self)
if __name__ == '__main__':
model = CustomModel()
model.run()3.机器学习类(回归)组件
自定义组件实现的FM回归算法组件:
import numpy as np
import pandas as pd
from aiworks_plugins.hdfs_plugins.utils import get_data
from aiworks_plugins.hdfs_plugins.utils import save_model, save_data
def compute_mse(y1, y2):
if len(y1) != len(y2):
raise ValueError("y1.length != y2.length")
y1 = list(y1)
y2 = list(y2)
return sum([(y1[i] - y2[i]) ** 2 for i in range(len(y1))]) / len(y1)
def sigmoid(x):
return 1.0 / (1.0 + np.exp(-x))
class FM:
def __init__(self, k=3, task_object='regression', max_iter=100, learning_rate=0.01, bias=0.01, verbose=True):
self.k = k
self.task_object = task_object
self.max_iter = max_iter
self.learning_rate = learning_rate
self.v = None
self.w = None
self.b = bias
self.verbose = verbose
def fit(self, x: np.ndarray, y: np.ndarray) -> None:
M, N = x.shape
self.v = np.random.normal(0, 0.1, [self.k, N])
self.w = np.random.normal(0, 0.1, N)
for _iter in range(self.max_iter):
dv = np.zeros([self.k, N])
dw = np.zeros(N)
db = 0
y_hat = self.predict(x)
if self.verbose:
print("################################")
print("iter{}, 训练误差:".format(_iter), compute_mse(y, y_hat))
for m in range(M):
diff = y[m] - y_hat[m]
dw += -0.5 * diff * x[m]
db += -0.5 * diff
dv += -0.5 * diff * (
np.matmul(np.matmul(self.v, x[m]).reshape(-1, 1), x[m].reshape(1, -1)) - x[m] ** 2 * self.v)
self.w -= self.learning_rate * dw / m
self.b -= self.learning_rate * db / m
self.v -= self.learning_rate * dv / m
def _product(self, x: np.ndarray):
"""
:param x: shape [1,n]
"""
res = 0
for k in range(self.v.shape[0]):
tmp = np.array([self.v[k][i] * x[i] for i in range(len(x))])
res += np.sum(tmp) ** 2 - np.sum(tmp ** 2)
return 0.5 * res
def _predict(self, x: np.ndarray):
"""
:param x: shape [1,n]
"""
return self.b + np.dot(x, self.w) + self._product(x)
def predict_proba(self, x: np.ndarray) -> np.ndarray:
if self.task_object == "regression":
raise KeyError("no probability in regression task")
return [sigmoid(self._predict(x[i])) for i in range(len(x))]
def predict(self, x: np.ndarray) -> np.ndarray:
"""
:param x: shape [m,n]
"""
if self.task_object == "regression":
res = [self._predict(x[i]) for i in range(len(x))]
elif self.task_object == "classification":
temp = self.predict_proba(x)
res = (temp > 0.5) * 1
else:
raise KeyError("task_object should be regression or classification")
return np.array(res)
class CustomModel:
"""
这里选择的数据是sklearn内置的高血压数据数据
"""
def __init__(self):
self._estimator_type = "regressor"
self.model = FM(k=15, learning_rate=0.03, task_object='regression')
self.col = ['age', 'sex', 'bmi', 'bp', 's1', 's2', 's3', 's4', 's5', 's6']
self.target = ['label']
def fit(self, data: pd.DataFrame) -> None:
x = data[self.col].as_matrix()
x_new = []
self._max = []
self._min = []
for col in range(x.shape[1]):
tmp = np.zeros([len(x), 16])
_max = max(x[:, col])
self._max.append(_max)
_min = min(x[:, col])
self._min.append(_min)
for row in range(x.shape[0]):
_ = int(round((x[row][col] - _min) / ((_max - _min) / 15), 0))
tmp[row, _] = 1
x_new.append(tmp)
x = np.concatenate(x_new, axis=1)
self.model.fit(x, data[self.target].as_matrix())
def predict(self, data: pd.DataFrame) -> pd.DataFrame:
x = data[self.col].as_matrix()
x_new = []
for col in range(x.shape[1]):
tmp = np.zeros([len(x), 16])
for row in range(x.shape[0]):
_ = int(round((x[row][col] - self._min[col]) / ((self._max[col] - self._min[col]) / 15), 0))
tmp[row, _] = 1
x_new.append(tmp)
x = np.concatenate(x_new, axis=1)
res = self.model.predict(x)
return pd.DataFrame(res, columns=['pre'])
def run(self):
df0 = get_data(0)
self.fit(df0)
pre = self.predict(df0)
save_data(pre, 0)
save_model(self)
if __name__ == '__main__':
model = CustomModel()
model.run()4.机器学习类(聚类)组件
自定义组件实现的混合高斯算法组件:
import numpy as np
import pandas as pd
from functools import reduce
from aiworks_plugins.hdfs_plugins.utils import get_data
from aiworks_plugins.hdfs_plugins.utils import save_model, save_data
class Gmm:
def __init__(self, max_iter=100, n_components=3):
self.max_iter = max_iter
self.n_components = n_components
self.mu = None
self.covariances = None
self.gamma = None
self.alpha = None
def init(self, x):
self.mu = x[np.random.choice(range(x.shape[0]), self.n_components)]
self.covariances = [np.diag([1] * x.shape[1])] * self.n_components
self.gamma = np.ones([x.shape[0], self.n_components])
self.alpha = np.ones(self.n_components) / self.n_components
@staticmethod
def compute_pdf(x, mu, det_covariances, pinv_covariances):
_, shape = pinv_covariances.shape
part1 = 1 / ((2 * np.pi) ** (shape / 2) * det_covariances ** 0.5)
tmp = (x - mu).reshape(-1, 1)
part2 = np.exp(-0.5 * reduce(np.matmul, (tmp.T, pinv_covariances, tmp)).flat[0])
return part1 * part2
def e_step(self, x):
probability = [[] for j in range(x.shape[0])]
for k in range(self.n_components):
det_covariances = np.linalg.det(self.covariances[k])
pinv_covariances = np.linalg.pinv(self.covariances[k])
for j in range(x.shape[0]):
probability[j].append(
self.alpha[k] * self.compute_pdf(x[j], self.mu[k], det_covariances, pinv_covariances))
for k in range(self.n_components):
for j in range(x.shape[0]):
self.gamma[j][k] = probability[j][k] / sum(probability[j])
def m_setp(self, x):
for k in range(self.n_components):
self.mu[k] = np.sum([self.gamma[i][k] * x[i] for i in range(x.shape[0])], axis=0) / np.sum(self.gamma[:, k])
tmp = np.sum([[self.gamma[i][k] * np.matmul((x[i] - self.mu[k]).reshape(-1, 1),
(x[i] - self.mu[k]).reshape(-1, 1).T)]
for i in range(x.shape[0])], axis=0)
self.covariances[k] = tmp[0] / np.sum(self.gamma[:, k])
self.covariances[k].flat[::self.n_components + 1] += 1e-04
self.alpha[k] = np.mean(self.gamma[:, k])
def fit(self, x: np.ndarray) -> None:
self.init(x)
for i in range(self.max_iter):
self.e_step(x)
self.m_setp(x)
def fit_transform(self, x: np.ndarray) -> np.ndarray:
self.fit(x)
return self.predict(x)
def predict(self, x: np.ndarray) -> np.ndarray:
res = self.predict_proba(x)
res = np.argmax(res, axis=1)
return np.array(res)
def predict_proba(self, x: np.ndarray) -> np.ndarray:
probability = [[] for j in range(x.shape[0])]
alpha_probability = [[] for j in range(x.shape[0])]
for k in range(self.n_components):
det_covariances = np.linalg.det(self.covariances[k])
pinv_covariances = np.linalg.pinv(self.covariances[k])
for j in range(x.shape[0]):
probability[j].append(
self.alpha[k] * self.compute_pdf(x[j], self.mu[k], det_covariances, pinv_covariances))
for k in range(self.n_components):
for j in range(x.shape[0]):
alpha_probability[j].append(probability[j][k] / sum(probability[j]))
return np.array(alpha_probability)
class CustomModel:
"""
这里选择的数据是sklearn内置的鸢尾花数据数据
"""
def __init__(self):
self._estimator_type = "clusterer"
self.model = Gmm(max_iter=50, n_components=3)
self.col = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width']
def fit(self, data: pd.DataFrame) -> None:
self.model.fit(data[self.col].as_matrix())
def predict(self, data: pd.DataFrame) -> pd.DataFrame:
pre = self.model.predict(data[self.col].as_matrix())
return pd.DataFrame(pre, columns=['pre'])
def run(self):
df0 = get_data(0)
self.fit(df0)
pre = self.predict(df0)
save_data(pre, 0)
save_model(self)
if __name__ == '__main__':
model = CustomModel()
model.run()