本页目录
类型转化
pipeline.preprocessing.trans_type_v2.TransTypeV2Ai
第一步:选择要转化的数据类型

第二步:在数据表中选择要转换的字段
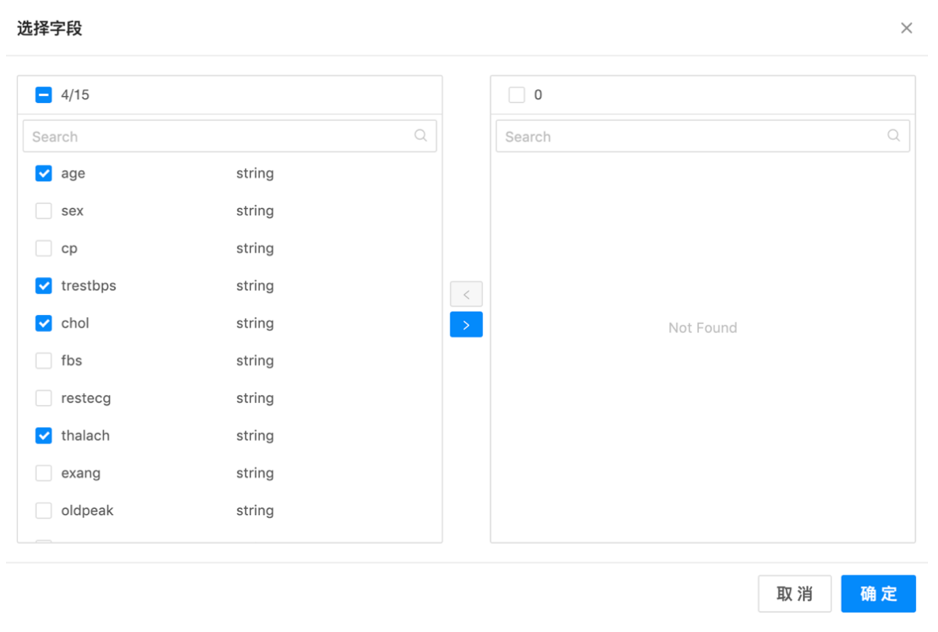
第三步:将选定的字段移动到右侧界面并确定
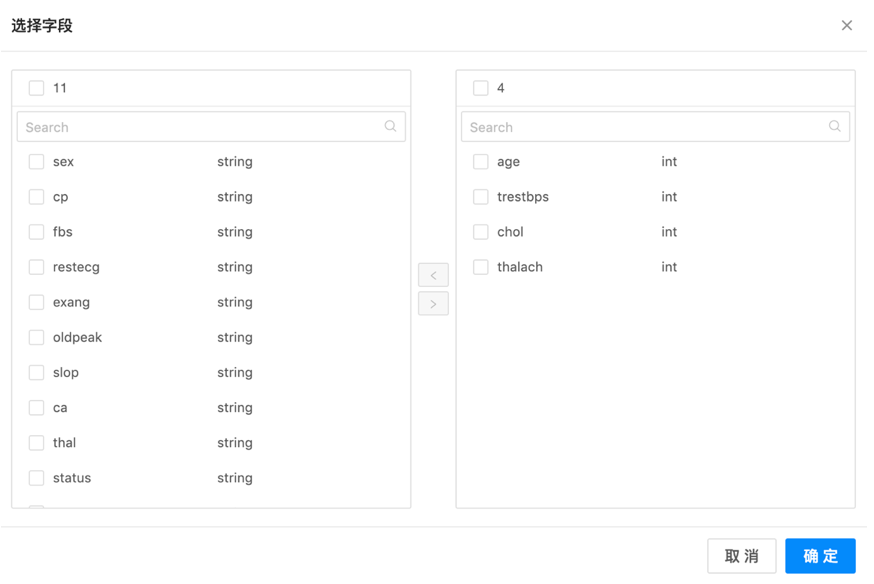
第四步:确认字段选择成功

组件说明:类型转化组件,对源表字段类型可进行转化,支持转化成double、int、string类型。且在转化值异常时,可进行默认值填充。
组件输入:上一个节点的数据表。
组件输出:完成字段类型转换后的数据表。
输入桩input
-
input:待转换的数据表。
输出桩output
-
output:转换后的数据表。
字段设置col_settings
-
double: 转换为double类型的列,多选,没有选择时传入空列表
-
double_error: 转换失败时的填充值,默认值0.0
-
int: 转换为int类型的列,多选,没有选择时传入空列表
-
int_error: 转换失败时的填充值,默认值0
-
str: 转换为str类型的列,多选,没有选择时传入空列表
-
str_error: 转换失败时的填充值,默认值空字符串
-
keep_original:是否保存原始列,如果是true,处理后的列加上前缀"typed_",拼接在原数据后面,如果是false,对应位置的列替换成处理后的列。
归一化
pipeline.preprocessing.normalize_v2.NormalizationV2Ai
第一步:点击选择字段按键
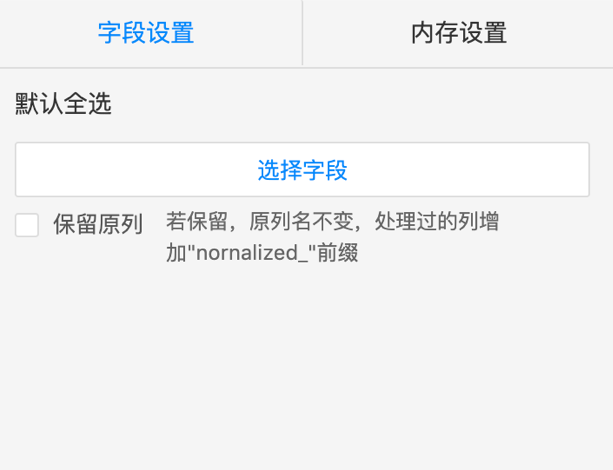
第二步:查看数据表中的字段,选择需要归一化的字段
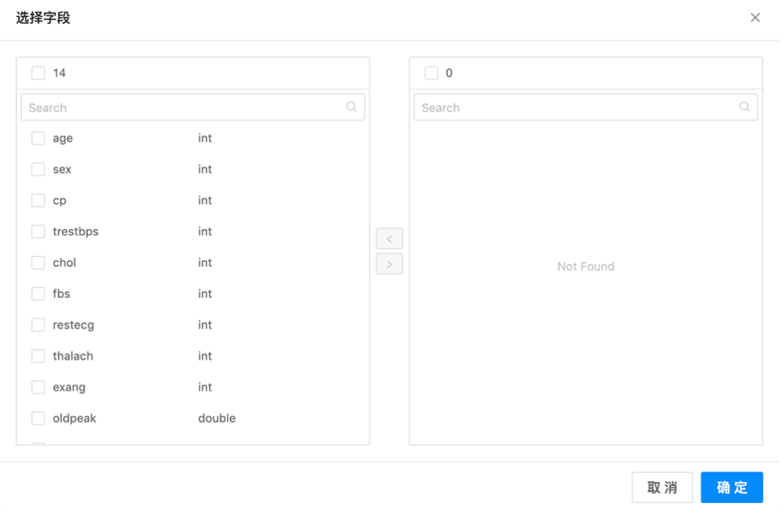
第三步:将选定的字段移动到右侧界面并确定。
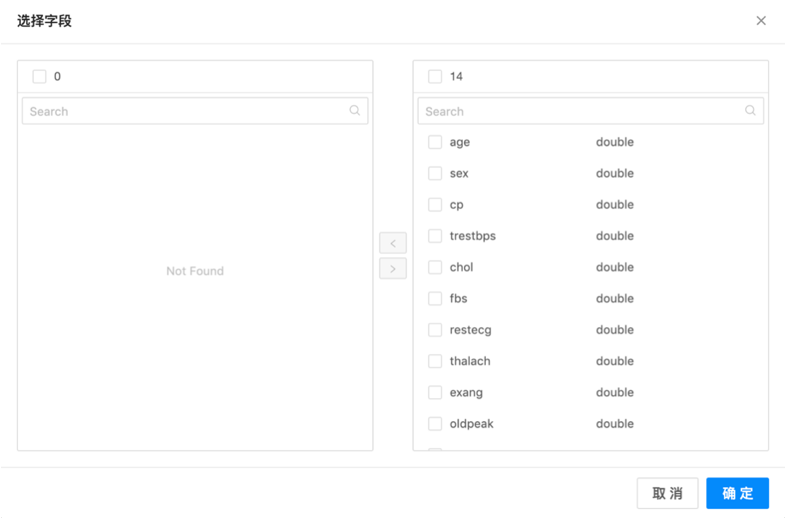
第四步:确认字段选择成功
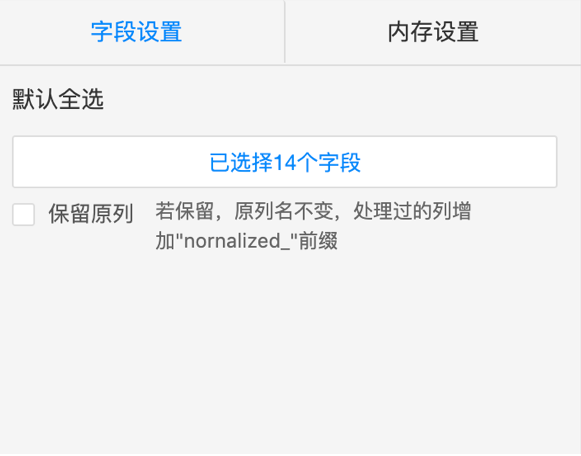
组件说明:归一化组件,对表的某列或多列进行归一化处理,产生的线数据存入新表中。目前支持线性函数转化,计算表达式为y=(x-min)/(max-min),在选取待处理字段的时候,可以选择是否保留待处理的字段列。
组件输入:两个输入桩,分别为待处理数据表的输入以及模型参数表的输入。
组件输出:两个输出桩,分别为处理后的数据表的输出以及归一化参数表的输出。
输入桩input
-
input1:输入待处理数据表。
-
input2:模型的输入。
输出桩output
-
output1:输出处理后的结果表。
-
output2:输出归一化模型。
字段设置col_settings
-
col: 特征列,必选,多选
-
keep_original: 是否保存原始列,如果是true,处理后的列加上前缀"norm_",拼接在原数据后面,如果是false,对应位置的列替换成处理后的列。
内存设置
-
占用内存大小:可设置组件占用的内存大小,范围[256,64*1024]MB,默认512MB。
-
并发数:可设置组件的并发数,范围[1,9999],默认为1,单线程运行。
缺失值填充
pipeline.preprocessing.fill_missing_value_v2.FillMissingValueV2Ai
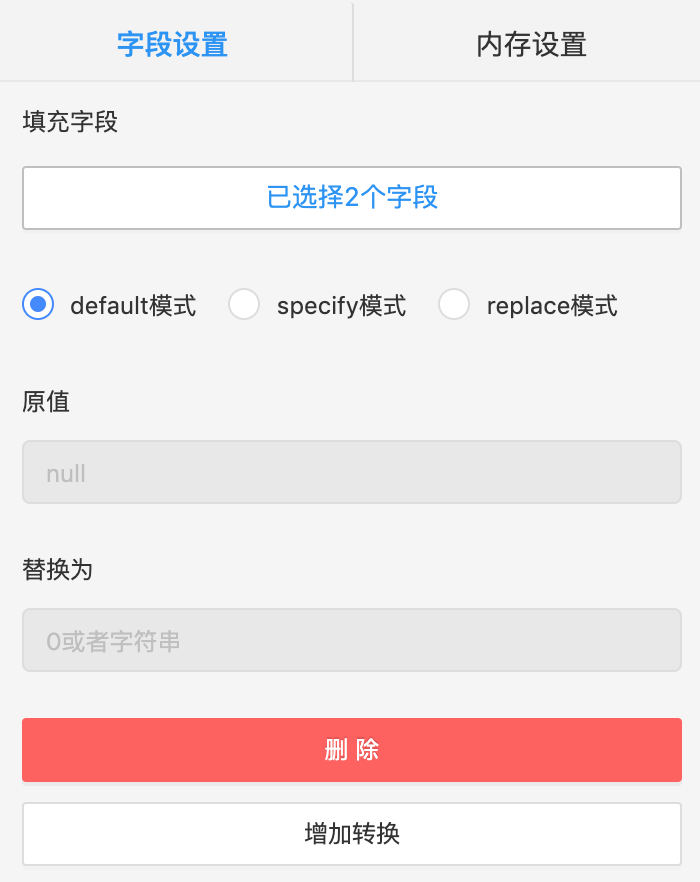
组件说明:缺失值填充组件,是数据预处理的一环,当数据缺失时,可可采用填充方法补充数据,保障数据分析的准确性与效率。 常见的是对Null和空字符进行填充,可用最小值、最大值、平均值、0值、空字符串填充等,也支持自定义原值与替换值。
组件输入:两个输入桩,分别为待处理数据表的输入以及模型参数表的输入。
组件输出:两个输出桩,分别为处理后的数据表的输出以及缺失值填充参数表的输出。
输入桩input
-
input1:待处理数据表。
-
input2:模型输入。
输出桩output
-
output1:输出结果表。
-
output2:输出缺失值填充模型参数表。
字段设置col_settings
-
col: 特征列,必选,多选
-
method: 填充方法选择 'default','specify','replace'
-
value:当method='specify’时,需要输入此参数,表示要填充的值
-
raw_value/new_value: 这两个参数绑定使用,当method='replace’时,将raw_value替换成new_value
内存设置
-
占用内存大小:可设置组件占用的内存大小,范围[256,64*1024]MB,默认512MB。
-
并发数:可设置组件的并发数,范围[1,9999],默认为1,单线程运行。
标准化
pipeline.preprocessing.standardize_v2.StandardScalerV2Ai
第一步选择字段
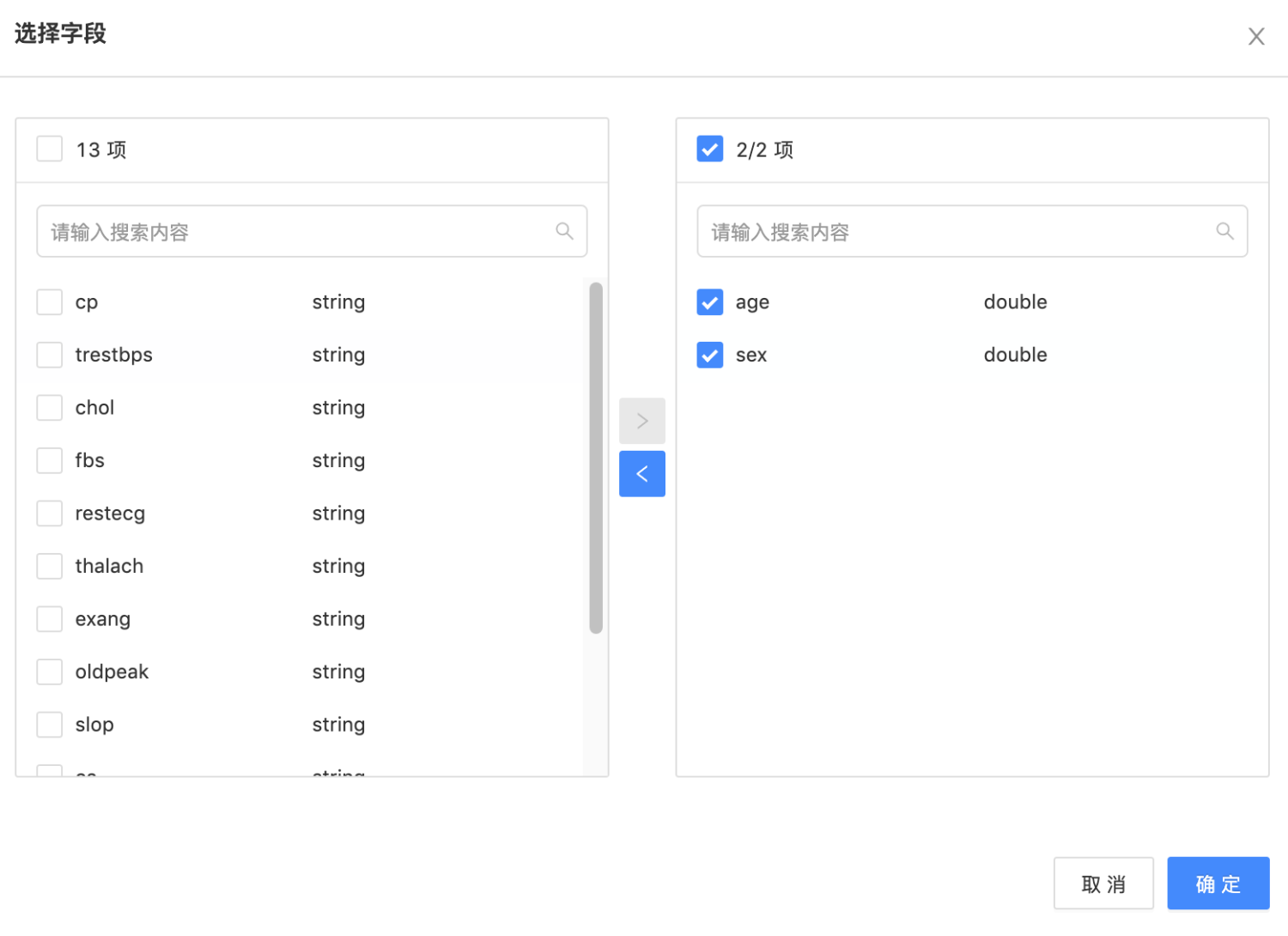
第二步选择好字段后,选择是否保留原列

组件说明:标准化组件,通过对原始数据进行变换把数据变换到均值为0,方差为1范围内。若保留原列,新的特征列名添加前缀std_,对源表的某列或多列进行标准化处理,处理后的数据存入新表。标准化采用的公式为(X-Mean)/(standard deviation)。 Mean表示样本平均值,standard deviation表示样本标准差。标准差=方差的算术平方根=s=sqrt(((x1-x)^2 +(x2-x)^2 +……(xn-x)^2)/n)。
组件输入:两个输入桩,分别为待处理数据表的输入以及模型参数的输入。
组件输出:两个输出桩,分别为标准化处理后的数据表的输出以及标准化模型的输出。
输入桩input
-
input1:待处理数据表的输入。
-
input2:模型的输入。
输出桩output
-
output1:输出标准化处理后结果表。
-
output2:输出标准化模型的参数表。
字段设置col_settings
-
col: 特征列,必选,多选
-
keep_original: 是否保存原始列,如果是true,则原列名不变,处理过的列增加"stdized_"前缀
内存设置
-
占用内存大小:可设置组件占用的内存大小,范围[256,64*1024]MB,默认512MB。
-
并发数:可设置组件的并发数,范围[1,9999],默认为1,单线程运行。
onehot编码
pipeline.feature.feature_generate.onehot_encoder_v2.OneHotEncoderV2Ai

组件说明:One-Hot编码,又称为一位有效编码,主要是采用N位状态寄存器来对N个状态进行编码,每个状态都由他独立的寄存器位,并且在任意时候只有一位有效。Example: 性别特征:["男","女"],按照N位状态寄存器来对N个状态进行编码的原理,这里只有两个特征,所以N=2,处理之后如下: 男 => 10 女 => 01 运动特征:["足球","篮球","羽毛球","乒乓球"](N=4): 足球 => 1000 篮球 => 0100 羽毛球 => 0010 乒乓球 => 0001 离散特征进行one-hot编码,编码后的特征,每一维度的特征都可看做是连续的特征,可对每一维度特征进行归一化。
组件输入:两个输入桩,分别为待编码的数据表以及模型参数的输入。
组件输出:两个输出桩,分别为编码后的结果表以及one-hot模型的输出。
输入桩input
-
input1:待编码的数据表。
-
input2:模型输入。
输出桩output
-
output1:输出one-hot编码后结果表。
-
output2:输出one-hot编码的模型参数表。
字段设置col_settings
-
选择二值化列: 特征列,必选,多选
-
附加列:附加列指可将输入表的哪些列输出至输出聚类结果表,列名以逗号分隔。
内存设置
-
占用内存大小:可设置组件占用的内存大小,范围[256,64*1024]MB,默认512MB。
-
并发数:可设置组件的并发数,范围[1,9999],默认为1,单线程运行
模型参数setting
| 参数名称 | 参数描述 | 参数可选项 | 参数类型 | 默认值 |
|---|---|---|---|---|
缺失率阈值 |
可设置缺失率阈值,若大于这个阈值则报错 |
范围[0,1] |
float |
0 |
drop |
是否删除第一个枚举量的编码。如果为True,可以保证编码后的数据线性无关 |
true,false |
bool |
false |
ignore |
是否忽略特征中的空元素。如果是True,则不对空元素编码 |
true,false |
bool |
false |
PCA主成分分析
pipeline.feature.feature_transform.pca_v2.PCAV2Ai

组件说明:主成分分析是通过正交变换将一组可能存在相关性的变量转换为一组线性不相关的变量,通过较少的综合变量尽可能反映原来变量的信息统计,是数学上用来降维的一种方法,即利用降维的思想,把多指标转化为少数几个综合指标,新的特征列名为pca_n (n为0,1,2,…)。
组件输入:两个输入桩,分别为预处理后的数据表以及模型的输入。
组件输出:三个输出桩,分别为处理后的结果表、主成分表以及模型的输出。
输入桩input
-
input1:待编码的数据表。
-
input2:模型输入。
输出桩output
-
output1:输出主成分分析后的结果表。
-
output2:输出主成分表。
-
output3:输出主成分模型。
字段设置col_settings
-
选择特征列: 特征列,必选,多选
-
附加列:附加列指可将输入表的哪些列输出至输出聚类结果表,列名以逗号分隔。
内存设置
-
占用内存大小:可设置组件占用的内存大小,范围[256,64*1024]MB,默认512MB。
-
并发数:可设置组件的并发数,范围[1,9999],默认为1,单线程运行
模型参数setting
| 参数名称 | 参数描述 | 参数可选项 | 参数类型 | 默认值 |
|---|---|---|---|---|
主成分选择 |
按比例还是按个数 |
主成分比例、主成分个数 |
float,int |
主成分比例 |
n_components |
必选,保留的成分数 |
0到1的浮点型或者大于1的整形 |
int, float |
0.9 |
method |
必选,特征分解方式 |
"corr", "covar" |
string |
"corr" |
特征尺度变换
pipeline.feature.feature_transform.scaler_v2.FeatureScalerV2Ai

组件说明:特征尺度变换组件,支持对特征列进行常见的尺度变换,如log2、log10、in、abs、sqrt等,新的特征列名添加前缀scaler_。
组件输入:输入待变换的数据表
组件输出:输出处理后的结果数据表
输入桩input
-
input1:待变换的数据表。
输出桩output
-
output1:输出变换后的数据表。
字段设置col_settings
-
选择特征列: 特征列,必选,多选
-
keep_original: 保留原列,若保留,原列名不变,处理过的列增加"scale_"前缀
-
缩放方法:变换方法的选择
内存设置
-
占用内存大小:可设置组件占用的内存大小,范围[256,64*1024]MB,默认512MB。
-
并发数:可设置组件的并发数,范围[1,9999],默认为1。
模型参数setting
| 参数名称 | 参数描述 | 参数可选项 | 参数类型 | 默认值 |
|---|---|---|---|---|
scale_method |
必填,尺度变换函数 |
'log2', 'log10', 'ln', 'abs', 'sqrt' |
string |
log2 |
label编码
pipeline.feature.feature_generate.label_encoder_v2.LabelEncoderV2Ai

组件说明:将离散型的数据转换成 0到 n-1之间的数,这里n是一个列表的不同取值的个数,可以认为是某个特征的所有不同取值的个数,将非线性特征转换为连续的线性数值特征。
组件输入:两个输入桩,分别为待编码的数据表以及模型的输入。
组件输出:两个输出桩,分别为编码后的结果表、编码模型的输出。
输入桩input
-
input1:待编码的数据表。
-
input2:模型输入。
输出桩output
-
output1:输出编码后的结果表。
-
output2:输出编码模型。
字段设置col_settings
-
选择特征列: 特征列,必选,多选
-
附加列:附加列指可将输入表的哪些列输出至输出聚类结果表,列名以逗号分隔。
内存设置
-
占用内存大小:可设置组件占用的内存大小,范围[256,64*1024]MB,默认512MB。
-
并发数:可设置组件的并发数,范围[1,9999],默认为1。