磁盘使用率预测
实验基础信息
-
实验名称:磁盘使用率预测
-
实验英文名:DiskUsage
-
所属类目:智能运维
-
实验描述:根据磁盘使用率的历史数据,通过时间序列Serima预测未来几个时刻的磁盘使用率,同时利用当前数据的前4个数据作为样本、当前数据为标签,构造训练数据,通过GBDT回归模型进行训练,构建预测模型。
-
主要应用算法:Serima、GBDT回归
-
应用场景:当遇到动态变化的平台和租户软硬件故障时,面对海量监控数据和庞大复杂的分布式系统,运维人员无法在高压下人力做出迅速、准确的运维决策,希望对服务性能指标进行监控、异常预测,反哺优化应用体验。现基于监控数据,利用算法能力,实现CPU与内存的动态阈值基线预测、磁盘容量预测、告警收敛等场景。
实验搭建
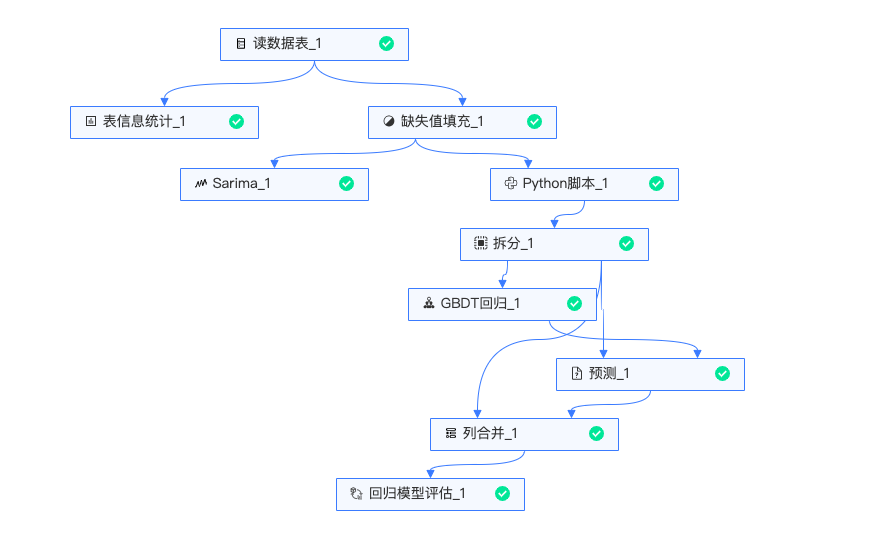
实验整体流程如下:
-
读数据:读入原始数据,及历史时间点的磁盘使用率。
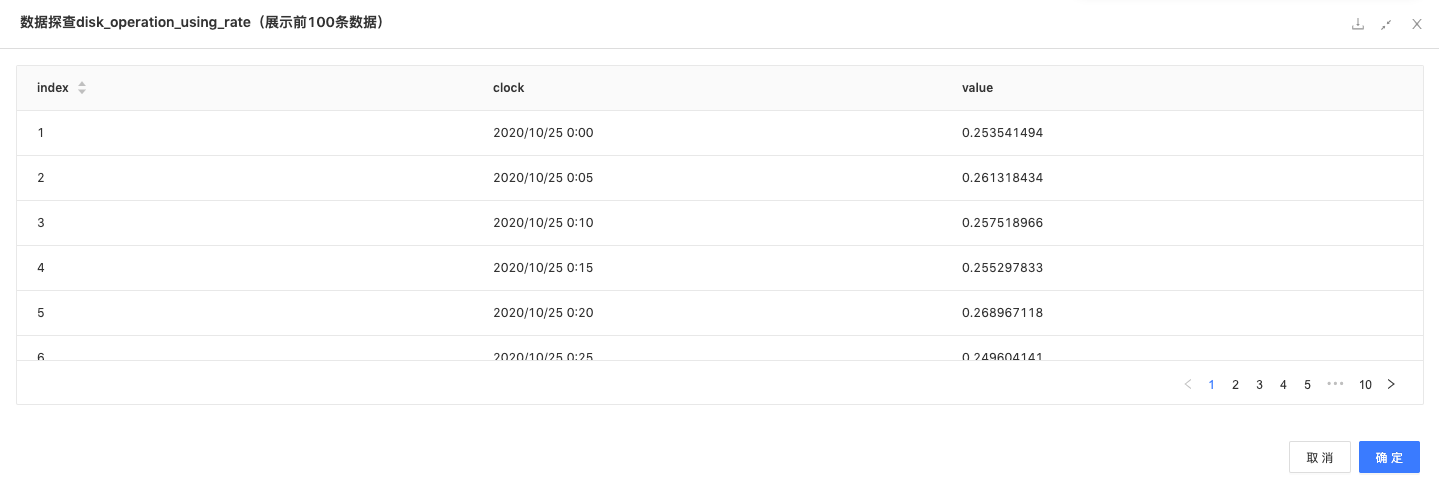
-
表信息统计:统计该表的count值、缺失值、unique数、均值、标准差、最最小值、二分位数、四分位数等指标。
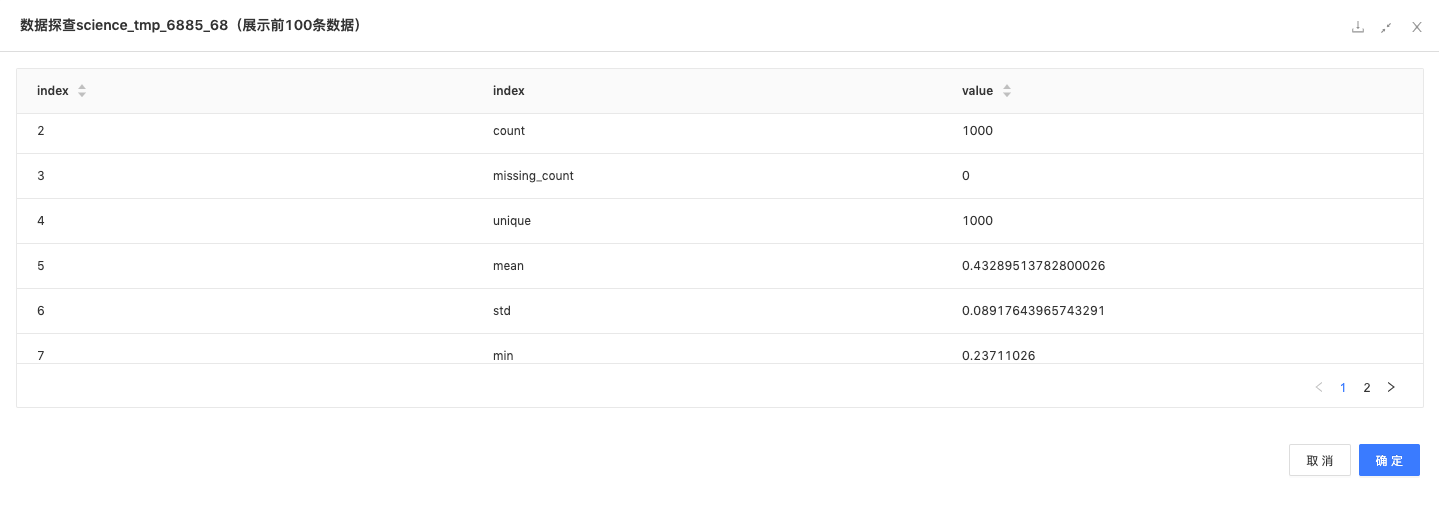
-
填充缺失值:缺失值采用中位数填充。
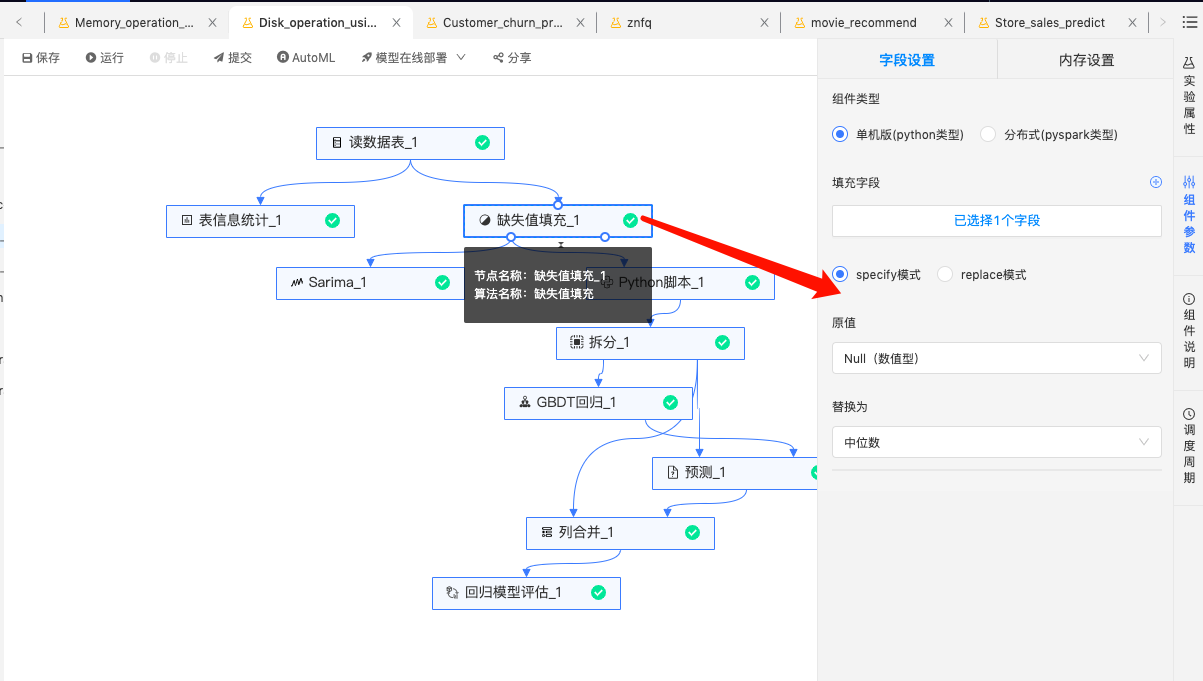
-
Sarima预测:由于人造数据,所需处理较少。通过Sarima模型预测了未来5个时刻的磁盘使用率。
数据结果为:[0.545, 0.543, 0.542, 0.541, 0.541]。
-
Python脚本:利用当前数据的前4个数据作为样本,当前数据为标签,构建训练所需的数据。
#将value列当前数据的前4个历史数据作为特征,将当前数据作为要预测的数据,构建dataframe,列名字为'history_1', 'history_2', 'history_3', 'history_4',预测值为'now_data'
data_set = []
value = table0['value'].values
time_index = table0.index[4:]
for i in range(4, table0.shape[0]):
data_set.append([value[i-4], value[i-3], value[i-2], value[i-1], value[i]])
df_res = pd.DataFrame(data=data_set, columns=['history_1', 'history_2', 'history_3', 'history_4', 'now_data'], index=time_index)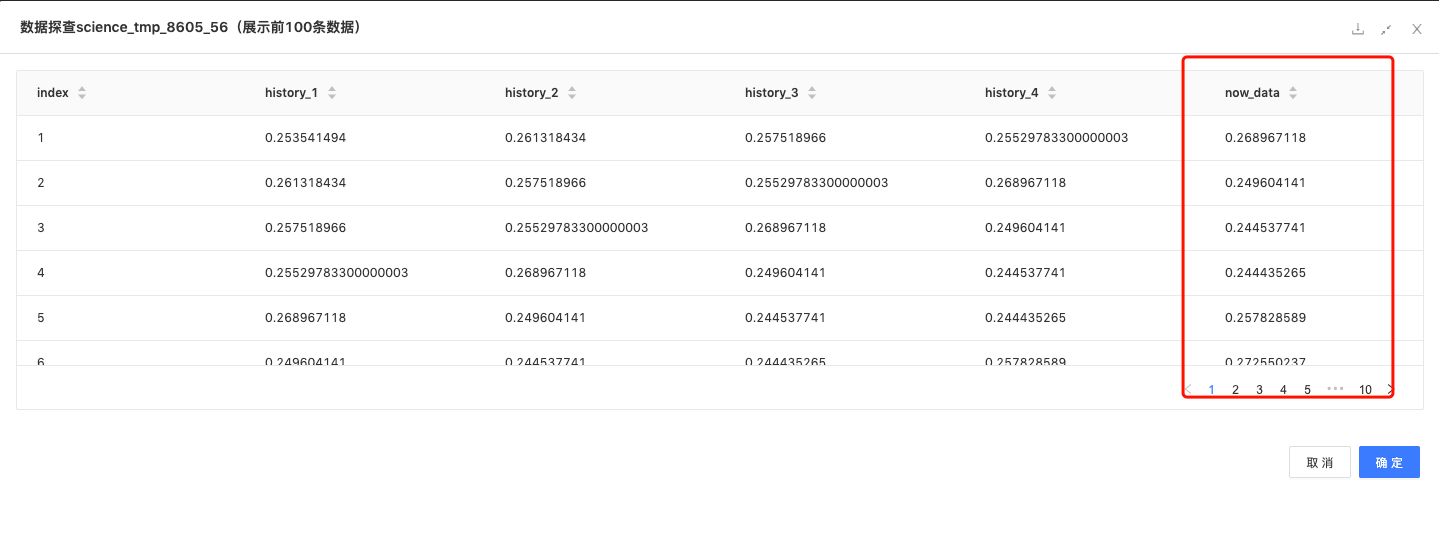
-
拆分:将训练数据和测试数据按8:2的比例进行行的拆分。
-
GBDT回归:用训练数据训练GBDT回归模型。
-
预测组件:用训练好的模型预测测试数据。
-
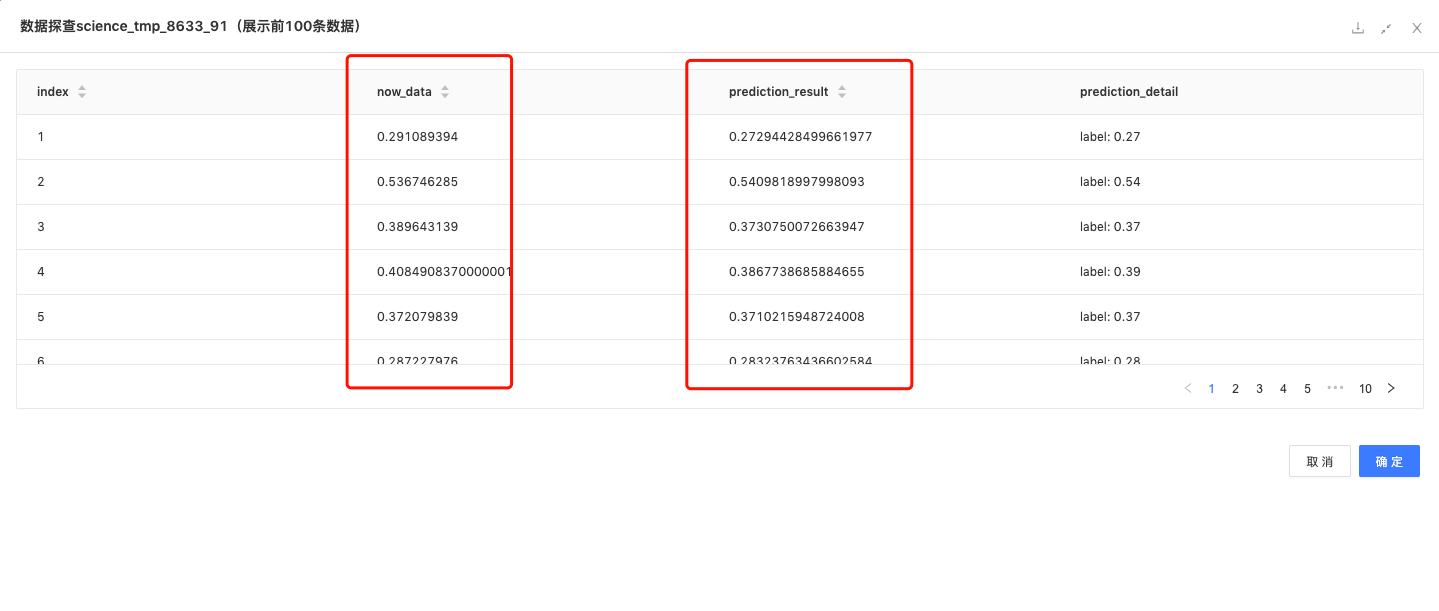
列合并组件:合并真实值与预测值。
-
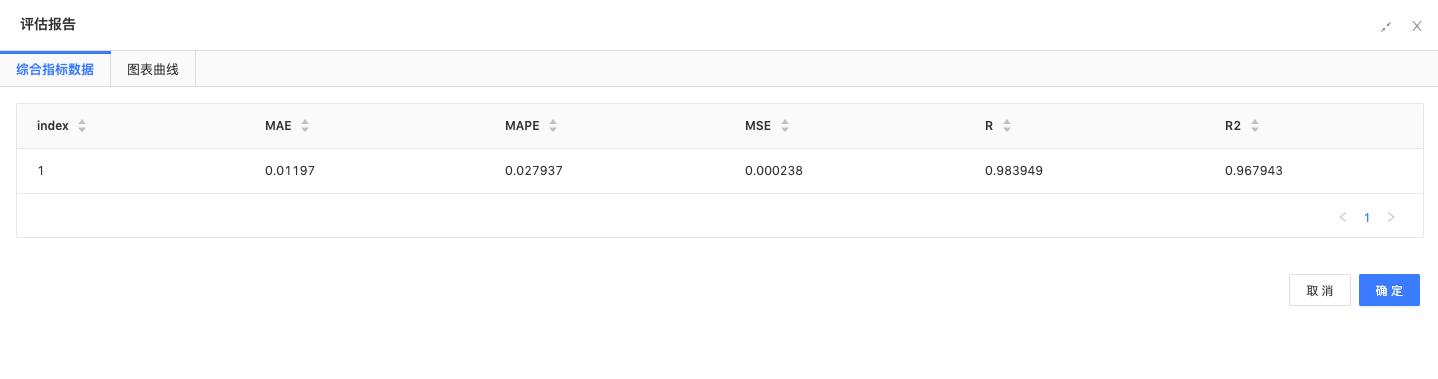
回归模型评估:得到验证集的均方误差为0.000239,R2分数为0.983867,效果较好。