数据管理
概述
AIWorks的数据存储统一在HDFS中,以Hive表的形式存储,算法建模时,Notebook与可视化实验都可引用。
-
数据源:项目的默认数据源,作为该项目的读写库,是项目创建时创建/接入的Hive库;

-
数据集:AIWorks的数据管理中心,数据来源包含从Hive库加载、本地上传,数据集的数据可直接应用在可视化实验建模上;

| 可视化实验的读数据组件的数据来源为数据集。Notebook可通过JDBC直接连接数据库,进行数据读取,不只是数据集中的数据。 |
小批量数据上传
支持上传不超过50M的TXT、CSV文件,数据分析师可直接上传此类型数据进行数据探索。
上传后,有2种方式进行数据应用:
-
直接上传文件至HDFS,系统会给出文件存储的HDFS路径,在编写Python代码时,可直接调用HDFS路径下的文件。
-
文件上传时可创建数据表,将TXT、CSV数据映射至Hive表中。
| 可视化实验中的"读数据表"组件,只支持读取数据表,不支持读取文件。故若使用读数据表组件且源数据是TXT、CSV文件,需将文件数据同步至数据表中。 |
-
上传数据
步骤一:进入"数据管理"页面,点击"上传文件"按钮;
步骤二:选择本地文件上传,只支持TXT、CSV文件类型,且文件大小不超过20M;
步骤三:选择文本的分隔符、字符编码格式、导入起始行、首行是否为标题等配置,并支持数据预览;
步骤四:选择将数据导入的目标表名称,也支持新建表。填写完表名称后,支持数据预览,可看见目标字段与源字段,帮助用户判断数据导入是否正确。并支持选择字段的匹配方式与数据导入模式。
新建表时,系统将根据上传的文件字段自动给出建表模板,用户只需修改表名称及字段类型即可。
-
字段匹配方式:2种,按位置匹配和按名称匹配。按位置匹配,指按照源文件的排列顺序进行与目标表的字段进行匹配。按名称匹配,指按照源文件的字段名称与目标表进行匹配。
-
导入方式:2种,追加和覆盖。追加,指在目标表原有数据后添加新数据。覆盖,指删掉目标表中的原有数据,同步新的数据。
步骤五:若数据预览无误,则可点击确认,进行数据上传。
数据上传成功后,便可在"数据管理"页面看见上传的数据,以及HDFS地址和HDFS路径。
大批量数据上传
若源数据为MySQL、Orancle、SQLServer、MongDB等数据库数据,需通过离线计算-数据同步模块,将源数据库数据同步至Hive数据源中。
数据同步使用方法详见 数据集成
| 可采用离线开发(离线计算)的数据同步模块进行数据同步,同步的目标库即为AIWorks项目的默认数据源。数据同步至AIWorks之后,便可在可视化实验与Notebook任务中可引用同步后的Hive目标表。 |
| 数据源不支持删除,编辑时只允许修改表的生命周期。 |
-
加载至数据集
Hive库中的已存在的数据表可加载至数据集中,供可视化实验使用。
步骤一:进入"数据管理"页面,点击项目默认数据源的"加载至数据集"按钮。系统将显示Hive库中未加载进数据集的表;
步骤二:选择需要加载的数据,加载进数据集;
数据可视化分析
数据集中的数据包含Hive表加载数据、本地上传数据、临时表、写数据表。
-
Hive表加载数据:从Hive库加载进数据集的数据;
-
本地上传数据: 本地CSV、TXT数据导入进Hive表的数据;
-
临时表:可视化组件运行时产生的临时表;
-
写数据表:通过AIWorks创建的数据表;
数据集可进行数据特征分析、数据分布分析、数据相关性分析,并进行数据预览、查看数据详情。
-
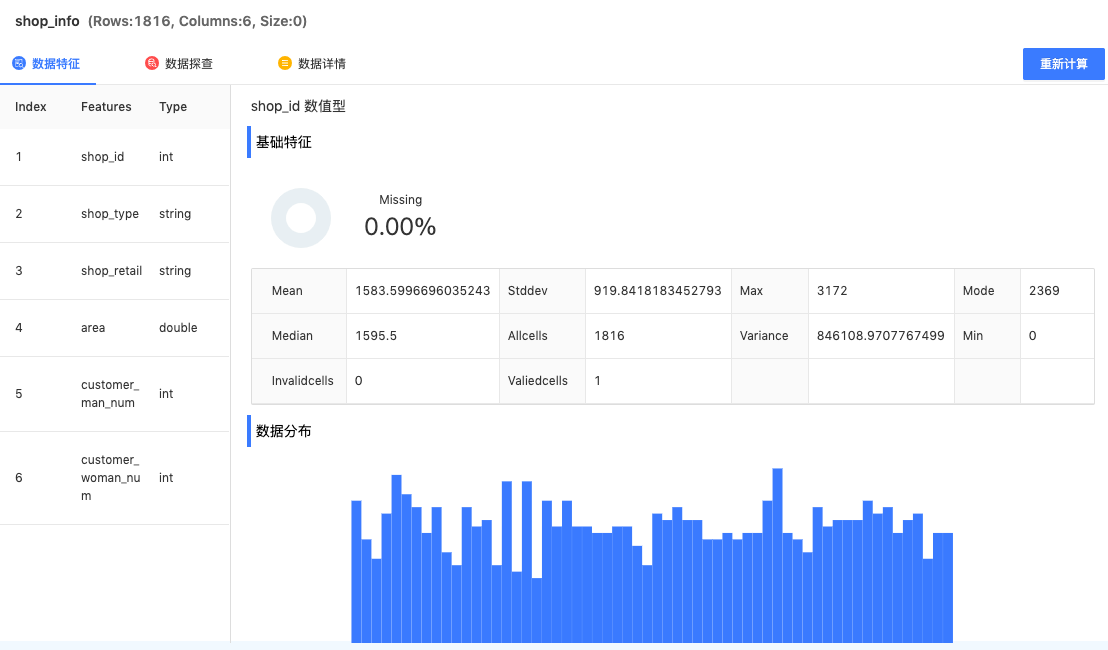
基础特征统计:可分析数据表每个特征(即字段)的最大值、最小值、众数、均值、方差、标准差、总单元格数、有值单元格数、无单元格数;
-
Missing:数据缺失率,该字段中缺失的单元格数/总行数;
-
Stability:数据稳定性,该字段中出现频率最高且非空值的单元格数/总行数;
-
ID-ness:数据差异性,该字段中不同取值的数量/总行数;
-
Max:最大值;
-
Min:最小值;
-
Mean: 均值;
-
Media:中位数;
-
Mode:众数;
-
Variance:方差;
-
Stddev:标准差;
-
Allcells:总行数;
-
Valied cells:有值的行数;
-
Invalid cells :无值的行数
-
-
分布分析:根据数据类型为连续型或离散型,采用纵向、横向条条形图划分数据区间,可查看各区间数据分布,掌握数据分布情况;

-
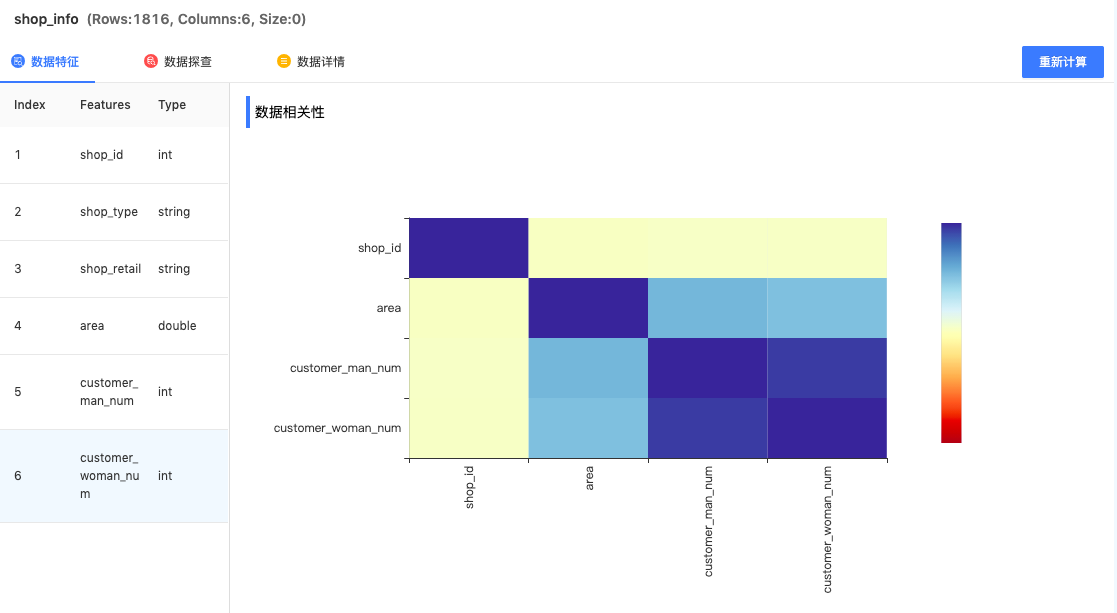
数据相关性分析:查看数据表与列之间的相关性;
-
数据预览
-
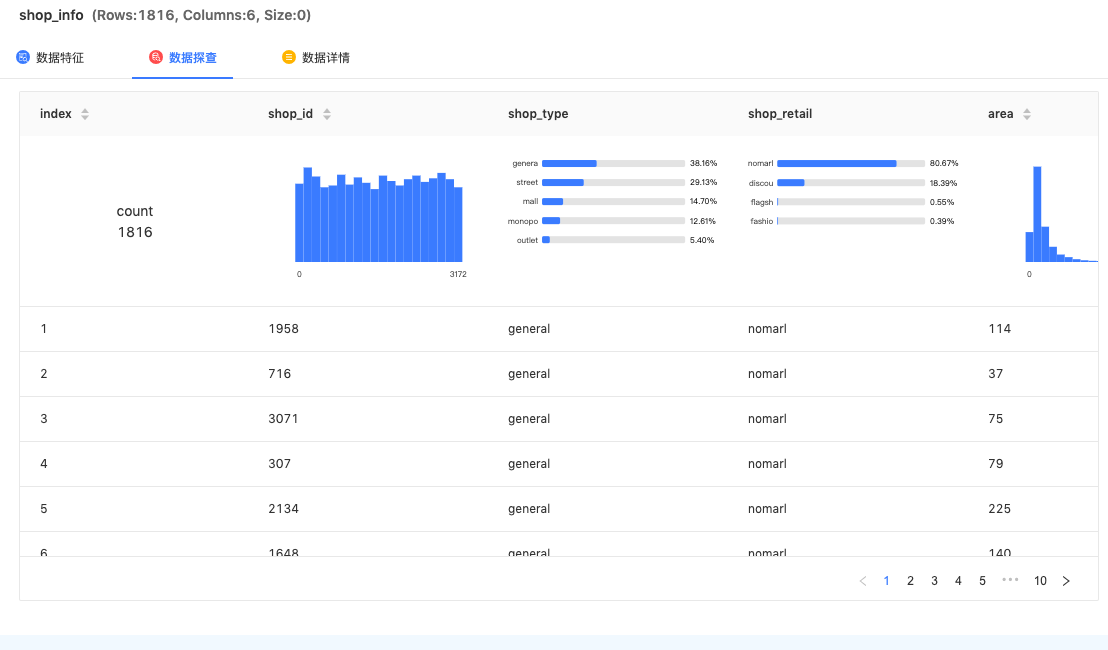
数据预览:可预览数据集前100条数据,并根据离散型、连续性数据类型通过横向条形图与纵向柱状图,展示每个字段的数据分布情况,让数据挖掘工程师更了解数据分布。
-
-
数据详情
-
数据详情:展示数据集描述、类型、表格式、HDFS存储地址、创建人与创建时间。
-