CPU使用率预测
实验基础信息
-
实验名称:CPU使用率预测
-
实验英文名:CpuUsage
-
所属类目:智能运维
-
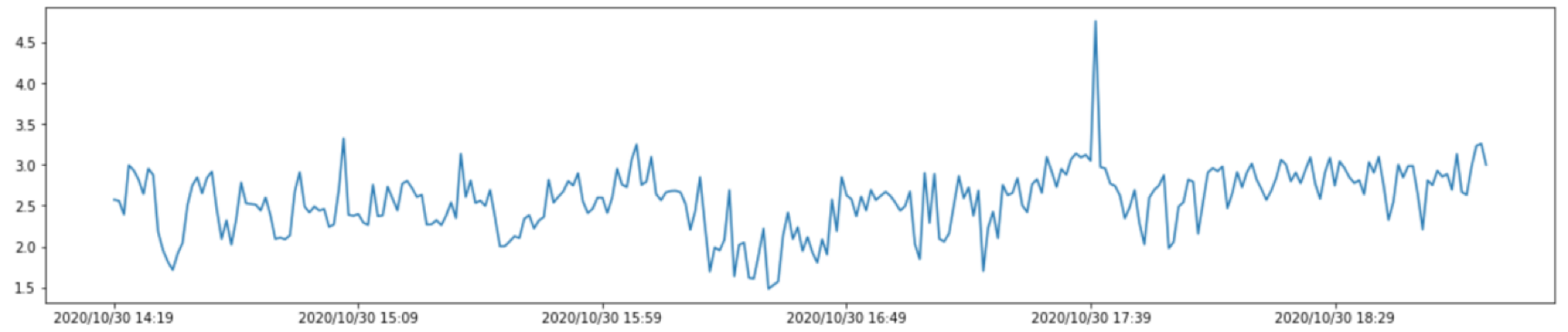
实验描述:根据CPU使用率的历史数据,通过时间序列Serima预测未来几个时刻的CPU使用率,同时利用滑动均值算法,检测当前时刻的CPU使用率是否发生异常。
-
主要应用算法:Serima
-
应用场景:当遇到动态变化的平台和租户软硬件故障时,面对海量监控数据和庞大复杂的分布式系统,运维人员无法在高压下人力做出迅速、准确的运维决策,希望对服务性能指标进行监控、异常预测,反哺优化应用体验。现基于监控数据,利用算法能力,实现CPU与内存的动态阈值基线预测、磁盘容量预测、告警收敛等场景。
实验搭建
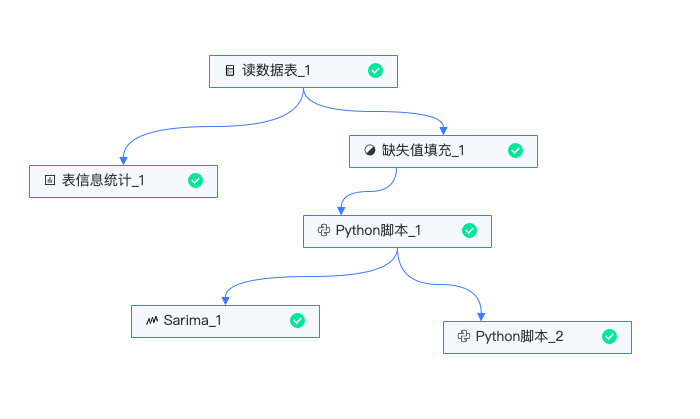
实验整体流程如下:
-
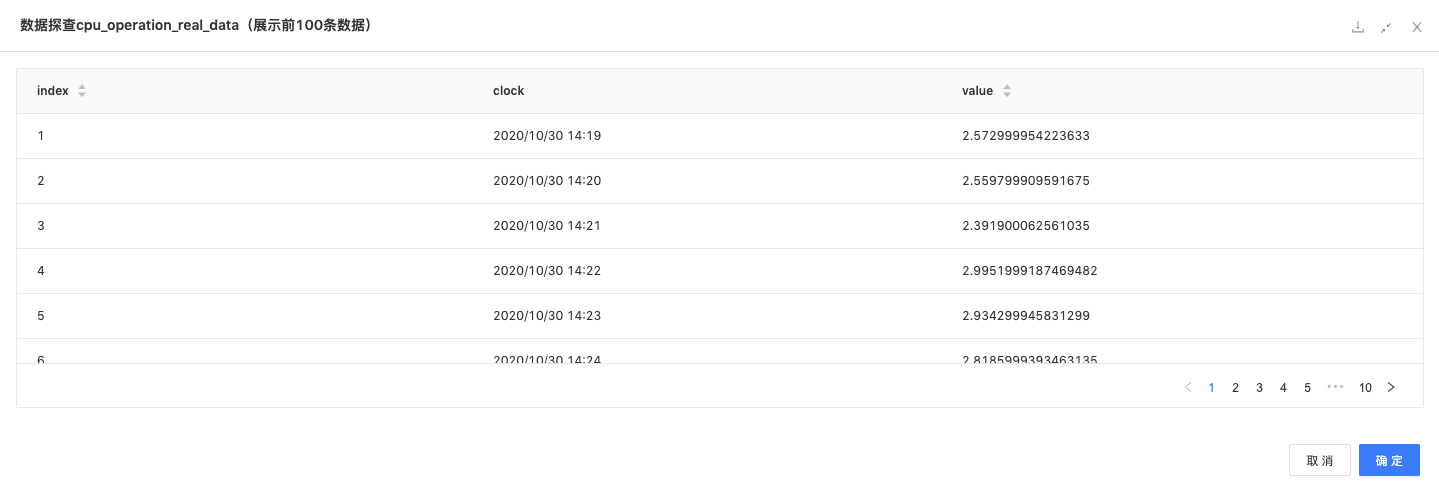
读数据:读入原始数据,及历史时间点的CPU使用率。
-
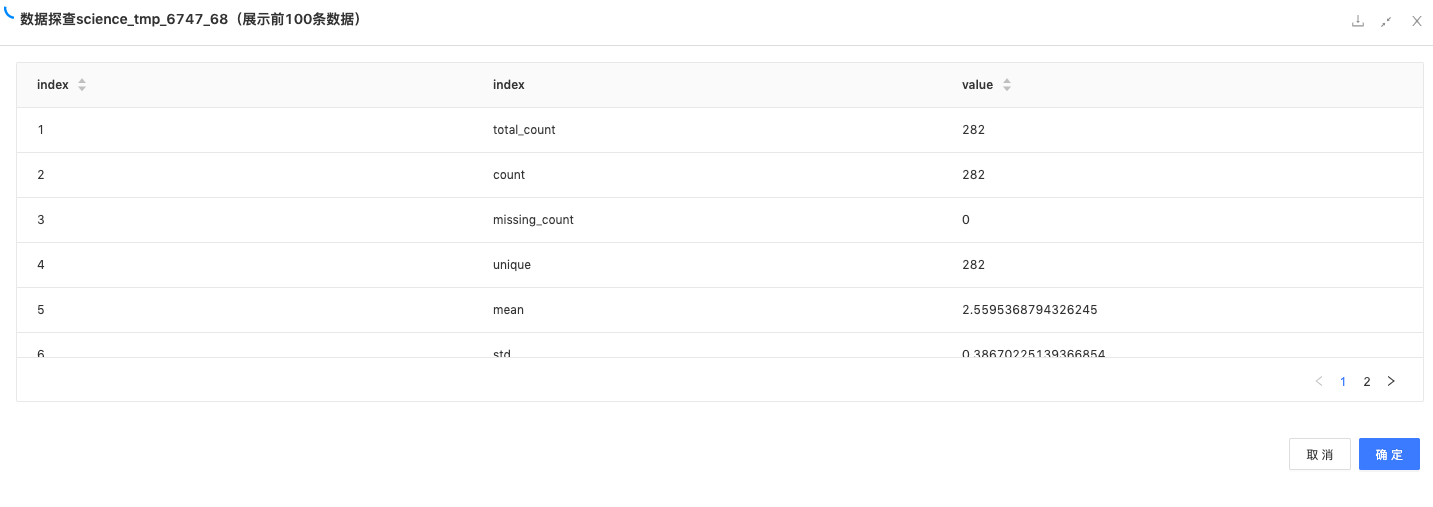
表信息统计:统计该表的count值、缺失值、unique数、均值、标准差、最最小值、二分位数、四分位数等指标。
-
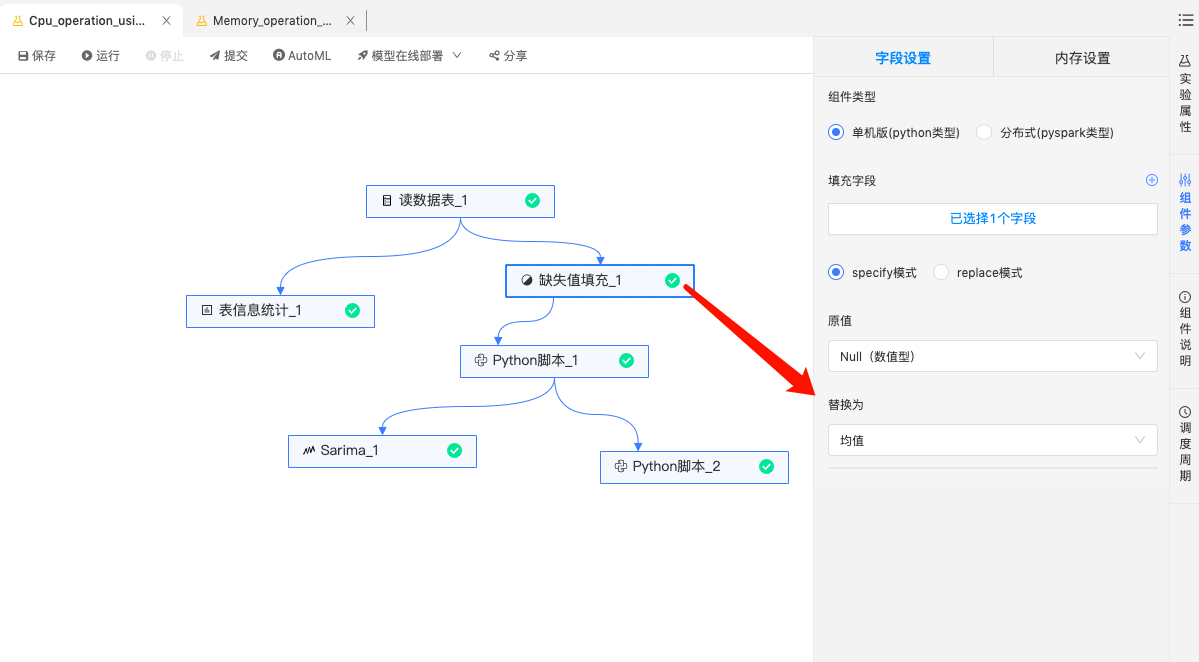
填充缺失值:缺失值采用均值填充。
-
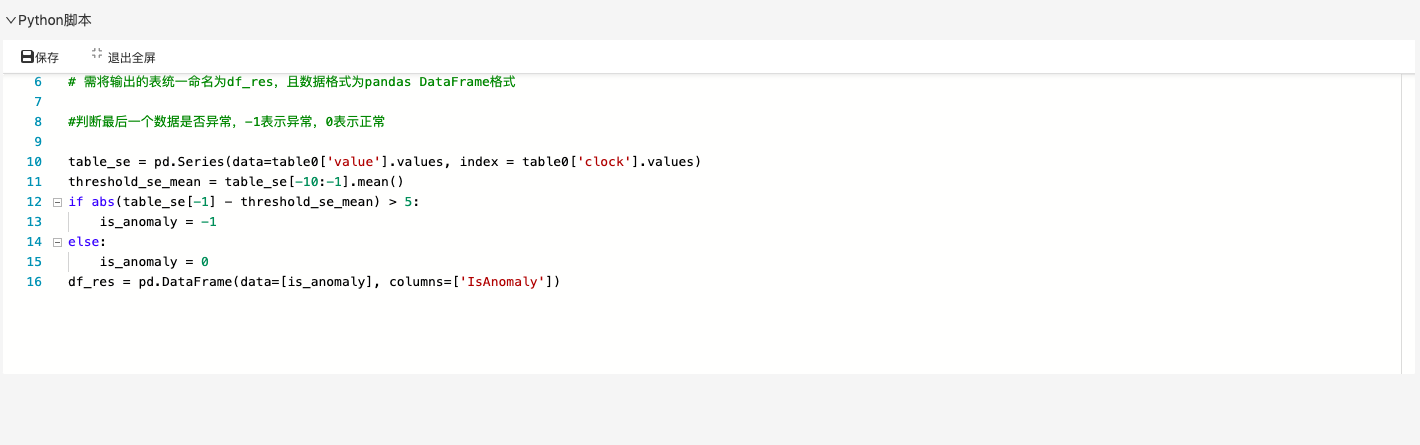
Python脚本:采用3-omega法则删除异常值,并用上下限来填补异常值。由于序列较为平稳,没有明显的周期或趋势,因此做异常值填充。
import numpy as np
col1 = table0.columns[1]
_std = np.std(table0[col1])
_mean = np.mean(table0[col1])
upper_data = _mean + 3 * _std
lower_data = _mean - 3 * _std
def bound_x(x):
if x > upper_data:
return upper_data
elif x < lower_data:
return lower_data
else:
return x
table0[col1] = table0[col1].apply(lambda x: bound_x(x))
df_res = table0-
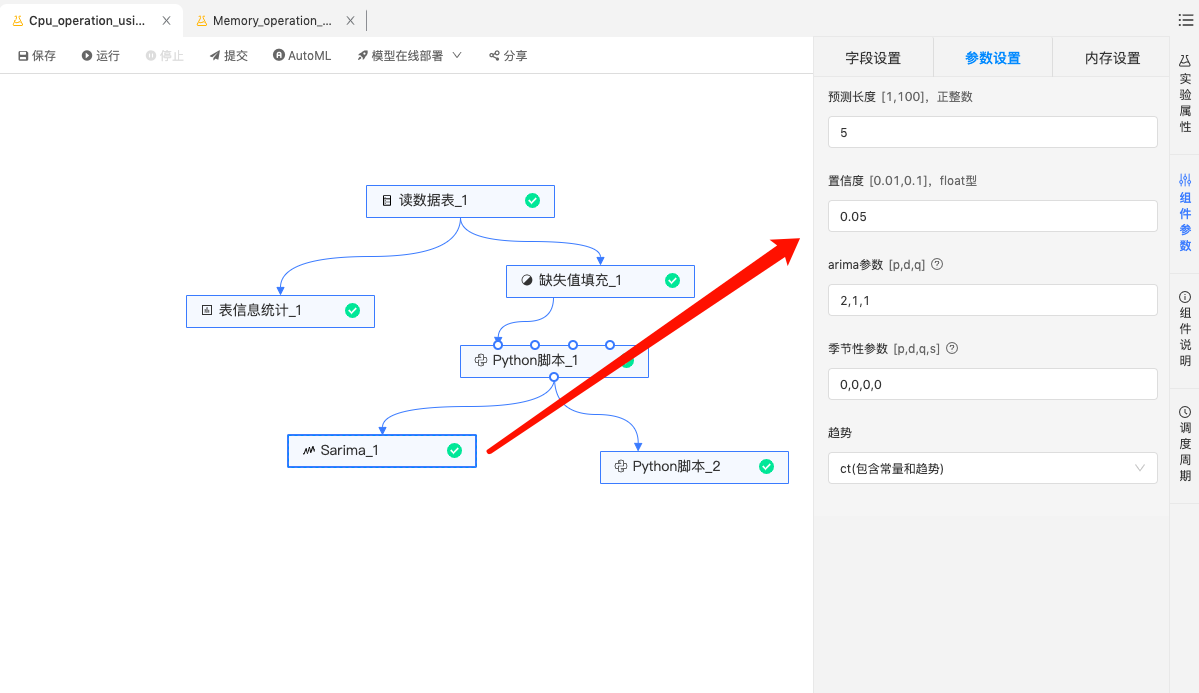
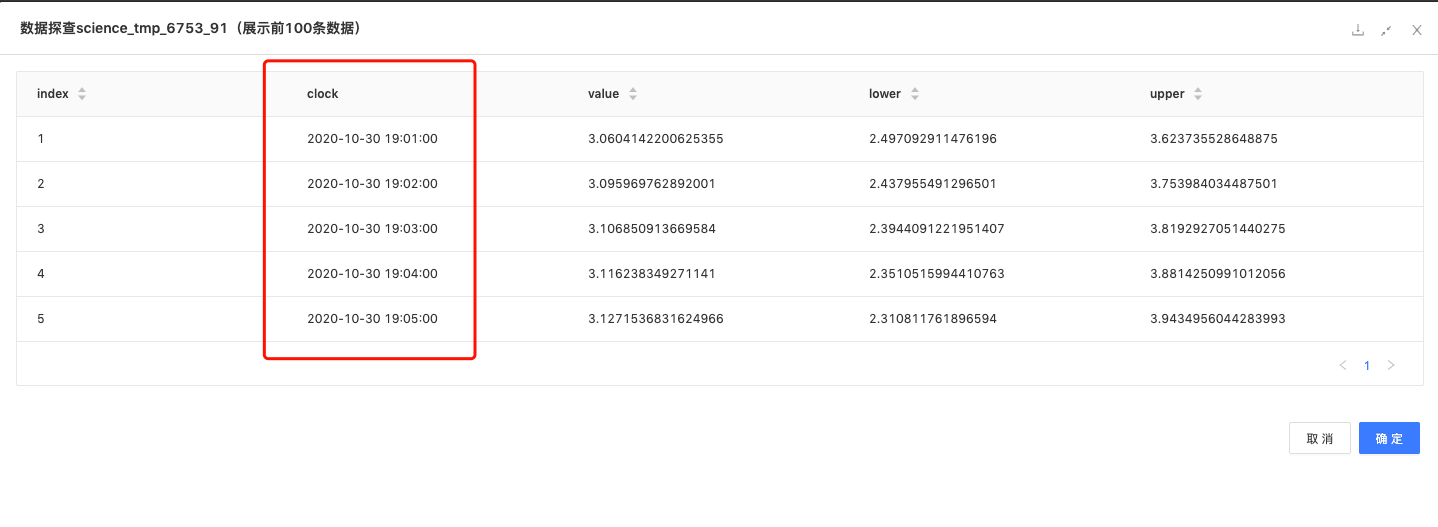
Sarima预测:通过Sarima算法预测未来5个值。
数据结果为:[3.060, 3.095, 3.106, 3.116, 3.127]。
-
Python脚本:比较当前值与前几个值均值,判断当前cpu使用率是否异常。