电影个性化推荐
实验基础信息
-
实验名称:电影个性化推荐
-
实验英文名:FrimRecommendate
-
所属类目:新媒体
-
实验描述:用协同过滤的方式,将用户对电影的评分矩阵进行矩阵分解,得到用户矩阵和电影矩阵,再用内积的方式得到用户对各个电影的预测评分,并以此进行推荐。
-
主要应用算法:协同过滤
实验搭建
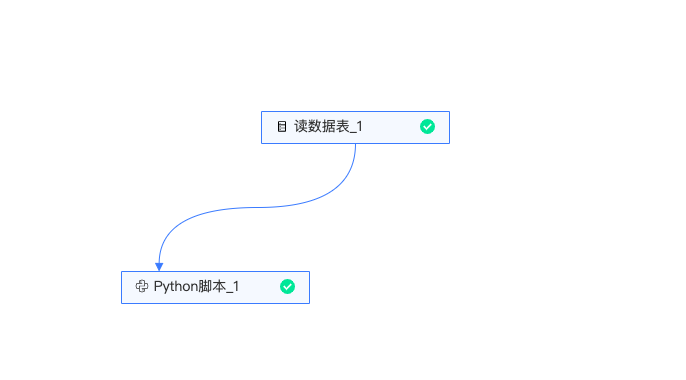
实验整体流程如下:
-
读数据表:读入原始数据。
-
Python脚本:实现了一个推荐系统SVD矩阵分解算法,利用矩阵分解,将用户电影评分矩阵分解为用户矩阵和电影矩阵。然后用某用户向量乘电影矩阵,得到这个用户对所有电影的预测评分,排序后得到推荐结果。
from datetime import datetime
from collections import defaultdict
import numpy as np
class SVD:
def __init__(self, epoch, eta, decay=0.999, method="increment", lu=0.001, lv=0.001, k=30, seed=None):
"""
梯度下降法求解矩阵分解,
当method="all"时,fit要输入评分矩阵,行代表用户,列代表物品,
当method="increment"时,fit要输入用户行为矩阵,行表示一个用户一次行为
:param epoch: 迭代次数
:param eta: 学习率
:param lu: 用户隐因子矩阵的惩罚
:param lv: 物品隐因子矩阵的惩罚
:param k: 隐因子维度
:param seed: 随机算子
"""
self.epoch = epoch
self.eta = eta
self.decay = decay
self.method = method
self.lu = lu
self.lv = lv
self.k = k
self.seed = seed
def fit(self, M):
"""
如果method="all",M是评分矩阵,行代表用户,列代表物品,
如果method="increment",M是用户行为矩阵,行表示一个用户一次行为
"""
if self.method == "all":
self._fit_all(M)
if self.method == "increment":
self._fit_increment(M)
def _fit_all(self, M):
"""
delta = R - mu - bu - bi - U*V.T
U := U + self.eta *(np.dot(delta, self.V) - lu * U)
V += self.eta * (np.dot(delta.T, self.U) - lv * V)
bu += self.eta * (np.sum(delta, axis=1) - lu * bu)
bi += self.eta * (np.sum(delta, axis=0) - lv * bi)
:param M: 评分矩阵,行代表用户,列代表物品
"""
self.userNums = M.shape[0]
self.itemNums = M.shape[1]
self.mean_grade = np.nanmean(M)
# 初始化U, V, bu, bi
np.random.seed(self.seed)
mu = np.sqrt((self.mean_grade - np.nanmin(M)) / self.k)
self.U = np.random.uniform(-0.1, 0.1, [self.userNums, self.k]) + mu
self.V = np.random.uniform(-0.1, 0.1, [self.itemNums, self.k]) + mu
self.bu = np.zeros(self.userNums)
self.bi = np.zeros(self.itemNums)
for i in range(self.epoch):
# 计算delta
self.eta *= self.decay
M_ = self.transform()
delta = M - M_
delta_U = np.dot(delta, self.V) - self.lu * self.U
delta_V = np.dot(delta.T, self.U) - self.lv * self.V
delta_bu = np.sum(delta, axis=1) - self.lu * self.bu
delta_bi = np.sum(delta, axis=0) - self.lv * self.bi
# 更新参数
self.U += self.eta * delta_U
self.V += self.eta * delta_V
self.bu += self.eta * delta_bu
self.bi += self.eta * delta_bi
if i % 100 == 0:
print("{} Epoch {} train rmse: {}".format(datetime.now(), i, self.rmse(M, self.transform())))
def _fit_increment(self, M):
"""
delta = Rui - mu - bu[uid] - bi[iid] - U[uid]*V[iid].T
U[uid] := U[uid] + eta * (delta * V[iid] - lu * U[uid])
V[iid] := V[iid] + eta * (delta * U[uid] - lv * V[iid])
bu[uid] := bu[uid] + eta * (delta - lu * bu[uid])
bi[iid] := bi[iid] + eta * (delta - lv * bi[iid])
:param M: 用户行为矩阵,行表示一个用户一次行为
"""
l = len(M)
self.userNums, self.itemNums = np.max(M[:, 0:2], axis=0) + 1
self.mean_grade = np.mean(M[:, 2])
# 初始化U, V, bu, bi
np.random.seed(self.seed)
mu = np.sqrt((self.mean_grade - np.min(M[:, 2])) / self.k)
self.U = np.random.uniform(-0.1, 0.1, [self.userNums, self.k]) + mu
self.V = np.random.uniform(-0.1, 0.1, [self.itemNums, self.k]) + mu
self.bu = np.zeros(self.userNums)
self.bi = np.zeros(self.itemNums)
for i in range(self.epoch):
self.eta *= self.decay
rmse = 0.0
# 计算delta
for sample in M:
uid = sample[0]
iid = sample[1]
vui = sample[2]
pui = self.transform(uid, iid)
delta = vui - pui
rmse += delta * delta
delta_u = delta * self.V[iid] - self.lu * self.U[uid]
delta_v = delta * self.U[uid] - self.lv * self.V[iid]
delta_bu = delta - self.lu * self.bu[uid]
delta_bi = delta - self.lv * self.bi[iid]
# 更新参数
self.U[uid] += self.eta * delta_u
self.V[iid] += self.eta * delta_v
self.bu[uid] += self.eta * delta_bu
self.bi[iid] += self.eta * delta_bi
print("{} Epoch {} train rmse: {}".format(datetime.now(), i, np.sqrt(rmse/l)))
def transform(self, u=None, i=None):
"""
返回用户u对物品i的预测评分值,如果u为None,返回所有用户的预测评分值,如果u不为None,i为None,返回用户u所有物品的预测评分值
:param u: 用户
:param i: 物品
:return:
"""
if u is None:
return self.mean_grade + self.bu.reshape([-1, 1]) + self.bi.reshape([1, -1]) + np.dot(self.U, self.V.T)
if i is None:
return self.mean_grade + self.bu[u] + self.bi + np.dot(self.U[u], self.V.T)
return self.mean_grade + self.bu[u] + self.bi[i] + np.dot(self.U[u], self.V[i])
def rmse(self, M, M_):
return np.sqrt(np.nanmean((M-M_)**2))
svd = SVD(epoch=10,eta=0.15,method='increment')
svd.fit(table0[['user_id','movie_id','rating']].as_matrix())
df_res = pd.DataFrame(svd.transform(1)).sort_values(by=0,ascending=False).reset_index()
df_res.columns = ['movie_id','score']数据结果:数据user_id为1的用户的电影推荐类表,如下