保险出险预测
实验基础信息
-
实验名称:保险出险预测
-
实验英文名:PersonalAccidentPrediction
-
所属类目:金融类
-
实验描述:根据购买保险客户的相关指标,预测保险公司是否将需要理赔以及理赔的概率。
-
主要应用算法:随机森林分类
实验搭建
实验整体流程如下:
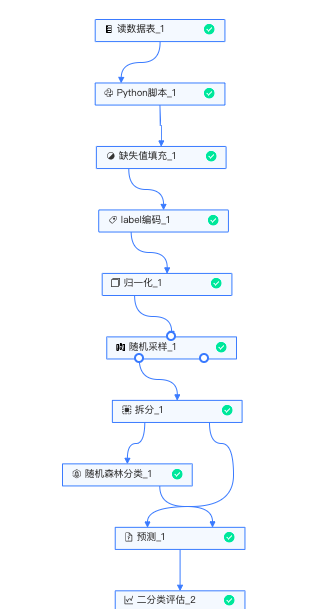
-
读数据表:读入投保人相关数据。
字段 |
注释 |
feature_0 |
编号 |
feature_1 |
身份证号 |
feature_2 |
购买险种 |
feature_3 |
是否真实出险(理赔) |
feature_4 |
身份证号关联的平均每个合作方的借款事件数 |
feature_5 |
身份证360天内非银金融行业下申贷事件中30日平台数的标准差 |
feature_6 |
身份证365天内一般消费平台行业下所有事件中的不同平台个数占相应时间下所有不同平台个数的比例 |
feature_7 |
身份证180天内全行业下所有风险集中包含Reject的次数所占比例 |
feature_8 |
身份证365天内全行业下所有策略集中包含Accept的次数所占比例 |
feature_9 |
身份证270天内非银金融行业下所有事件中近90日的新增平台数 |
feature_10 |
身份证关联到的近365天内一般消费平台下所有事件中出现的机构数 |
feature_11 |
身份证365天内非银金融行业下申贷事件中的不同平台个数占相应时间下所有不同平台个数的比例 |
feature_12 |
身份证365天内消费金融行业下申贷事件中的记录条数占相应时间下所有记录条数的比例 |
feature_13 |
身份证号一度关联节点数 |
feature_14 |
身份证关联到的近365天内所有行业中下申贷事件中最大风险分 |
feature_15 |
身份证365天内消费金融行业下所有事件中的记录条数占相应时间下所有记录条数的比例 |
feature_16 |
身份证365天内全行业下所有策略集中包含Review的次数所占比例 |
feature_17 |
身份证关联到的近365天内非银行金融下申贷事件中出现的机构数 |
feature_18 |
身份证365天内消费金融行业下申贷事件中的不同平台个数占相应时间下所有不同平台个数的比例 |
feature_19 |
身份证关联到的近90天内小额贷款公司下申贷事件中出现的机构数 |
feature_20 |
身份证号所在社群节点平均每个合作方的借款事件数 |
feature_21 |
身份证365天内银行行业下申贷事件中的不同平台个数占相应时间下所有不同平台个数的比例 |
feature_22 |
身份证关联到的近365天内非银行金融下所有事件中出现的机构数 |
feature_23 |
身份证365天内一般消费平台行业下申贷事件中的记录条数占相应时间下所有记录条数的比例 |
feature_24 |
身份证关联到的近365天内消费金融下申贷事件中出现的机构数 |
-
python脚本:删掉feature_0(编号)字段。

-
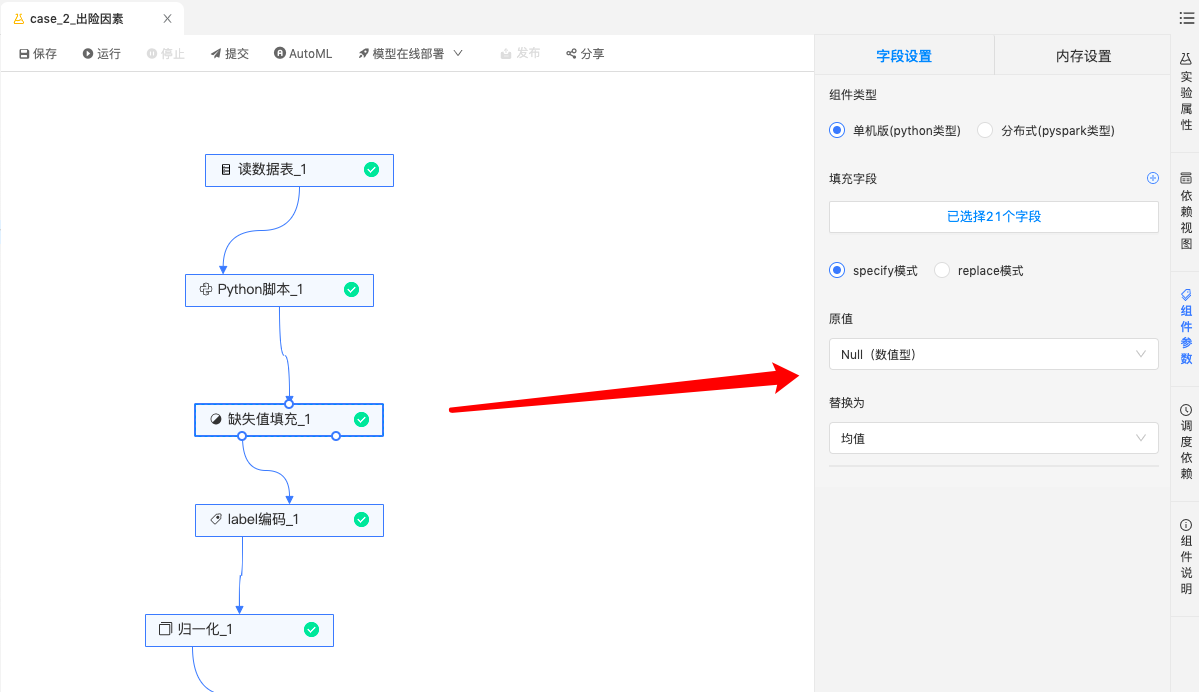
缺失值填充:针对有缺失列的字段进行缺失值填充,此处针对缺失列采用取均值的方法进行填充。
-
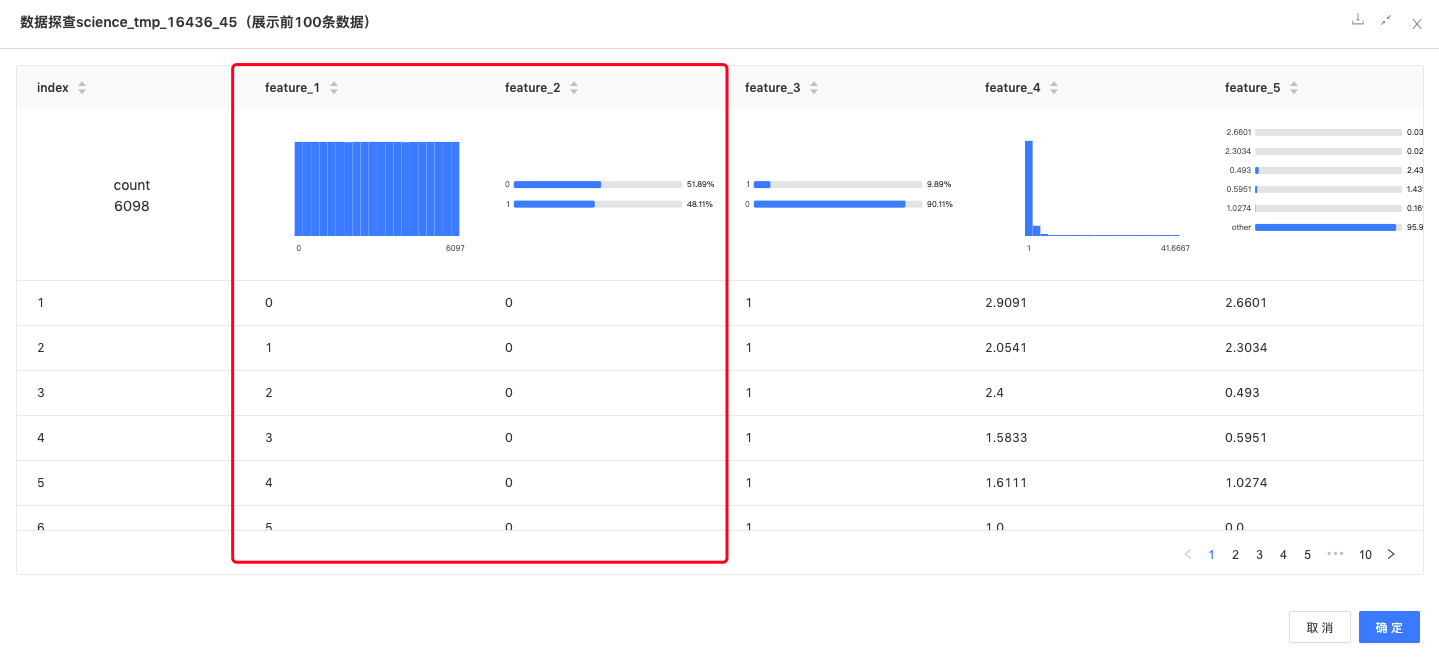
label编码:feature_1(身份证号)、feature_2(购买险种)字段进行label编码,将字符类型的离散型特征,转化为数值类型的连续特征。
-
归一化:将所有特征归一化在0-1之间,可消除不同列数据量纲的差异型,最优解的寻优过程会变得平缓,更容易正确的收敛最优解。
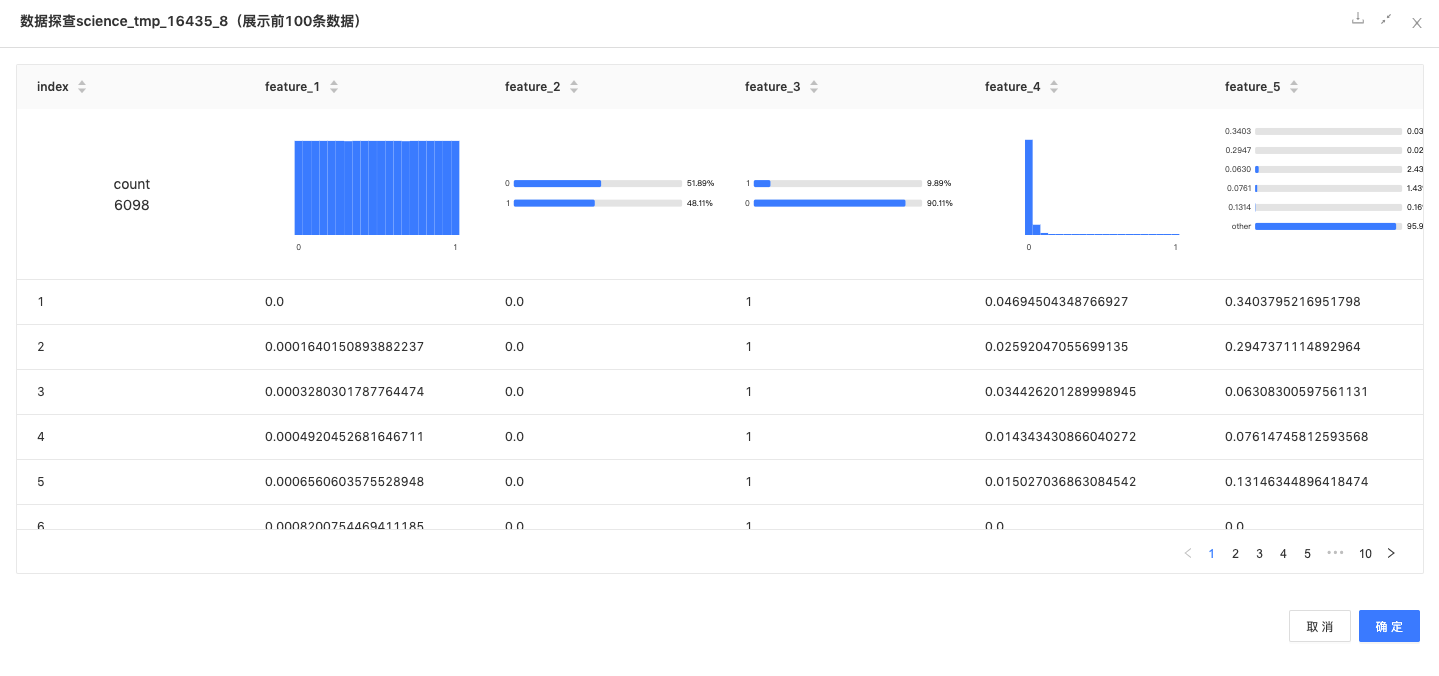
-
随机采样:针对标签列,扩大标签列中类别少的那一类的数据行数,使数据分布尽量均匀,模型训练效果更好。

-
拆分:将数据按照8:2的比例拆分,80%的数据进行模型训练,20%的数据进行预测。
-
随机森林分类:选定特征列与标签列,采用随机森林模型进行模型训练,以及每个特征的重要性如下:
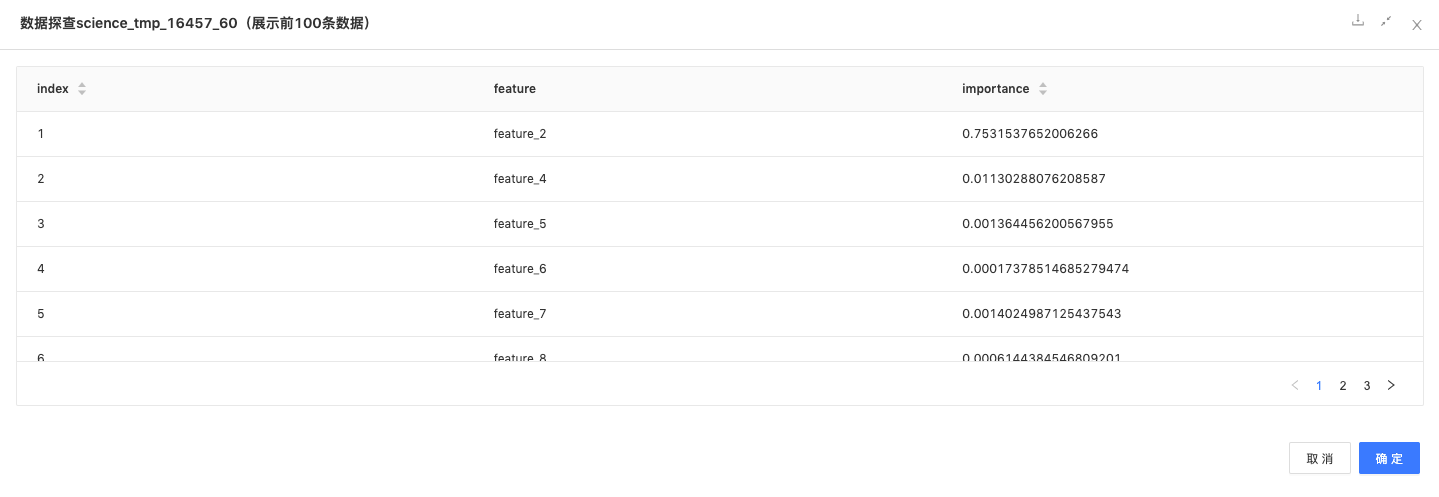
-
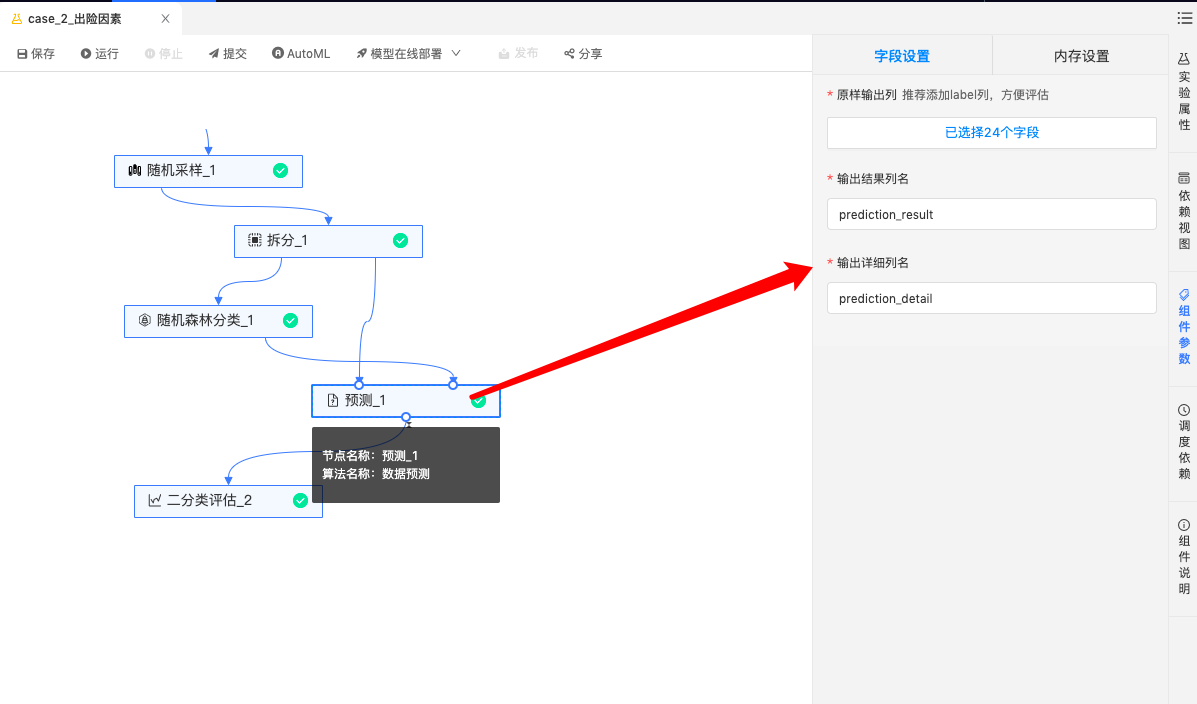
预测:用模型预测测试集数据的结论和概率。
-
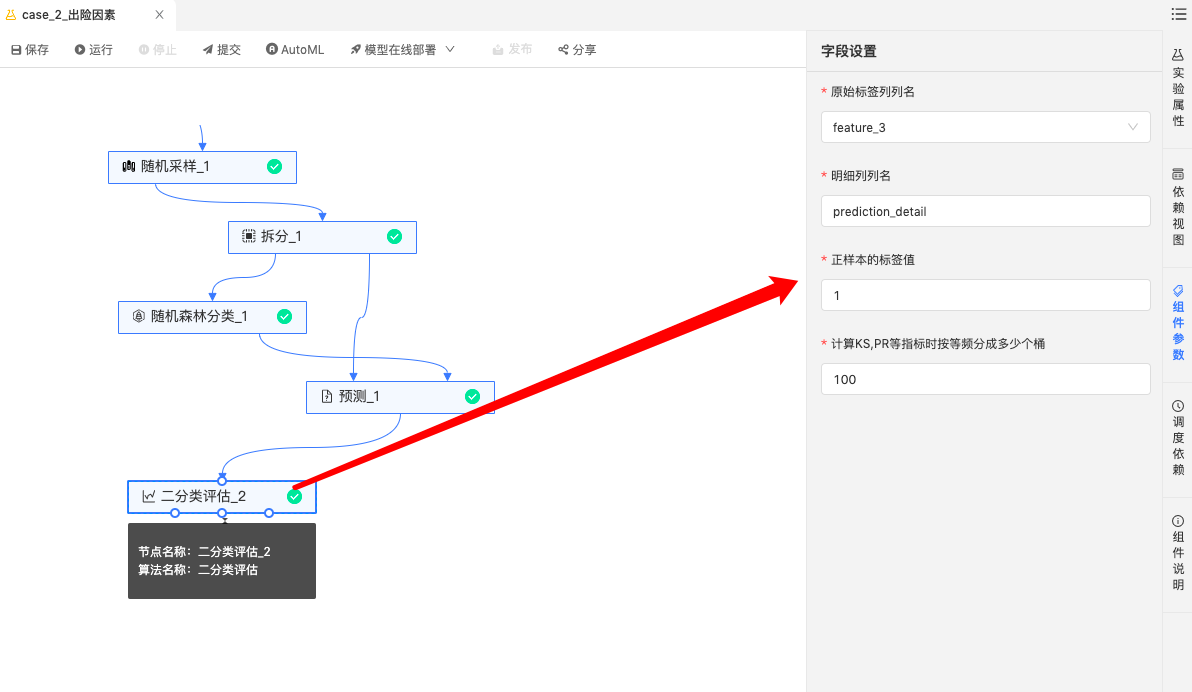
二分类评估、混淆矩阵评估:评估模型结果,查看模型准确率、精确率、召回率、AUC、KS值等指标。
评估报告结果如下:
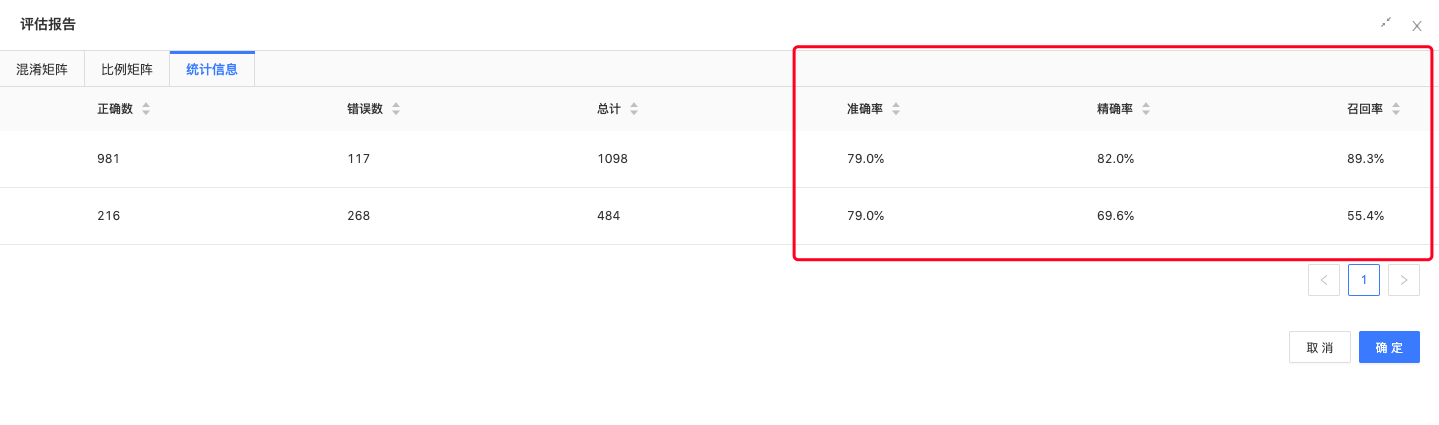
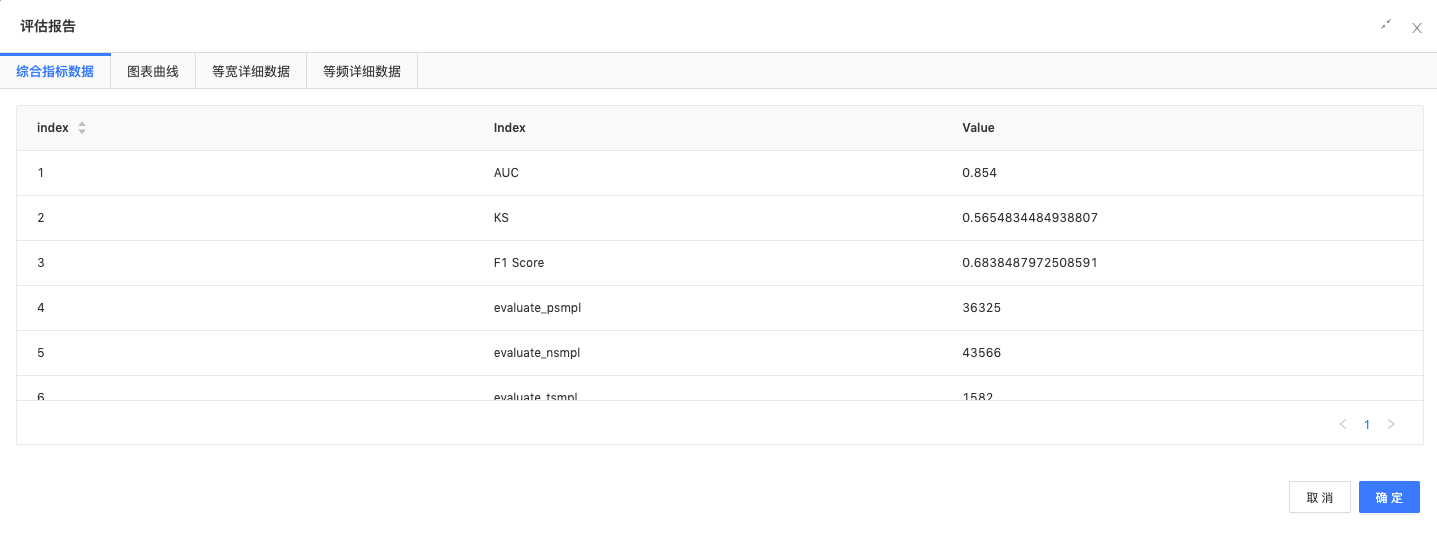
模型效果达到预期,建模结束。