门店聚类
实验基础信息
-
实验名称:门店聚类
-
实验英文名:ShopCluser
-
所属类目:新零售
-
实验描述:根据线下零售门店的大小、类型、地理位置、会员分布对门店进行聚类,以此提供决策依据
-
主要应用算法:K-Means聚类
实验搭建
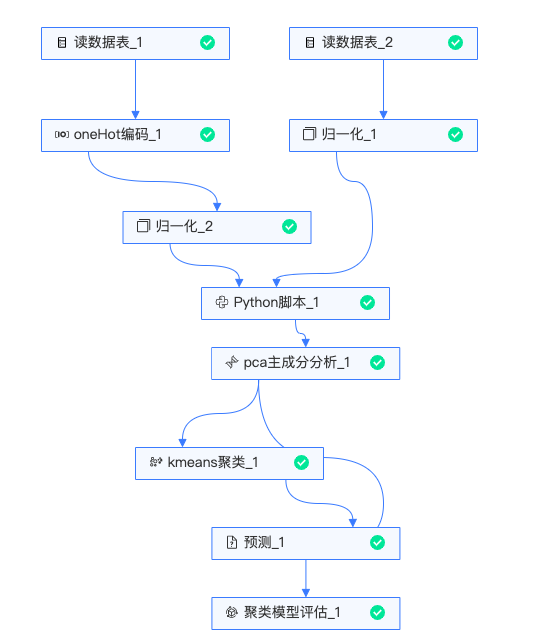
实验整体流程如下:
-
读数据表:读入门店基础数据与门店经纬度数据;
-
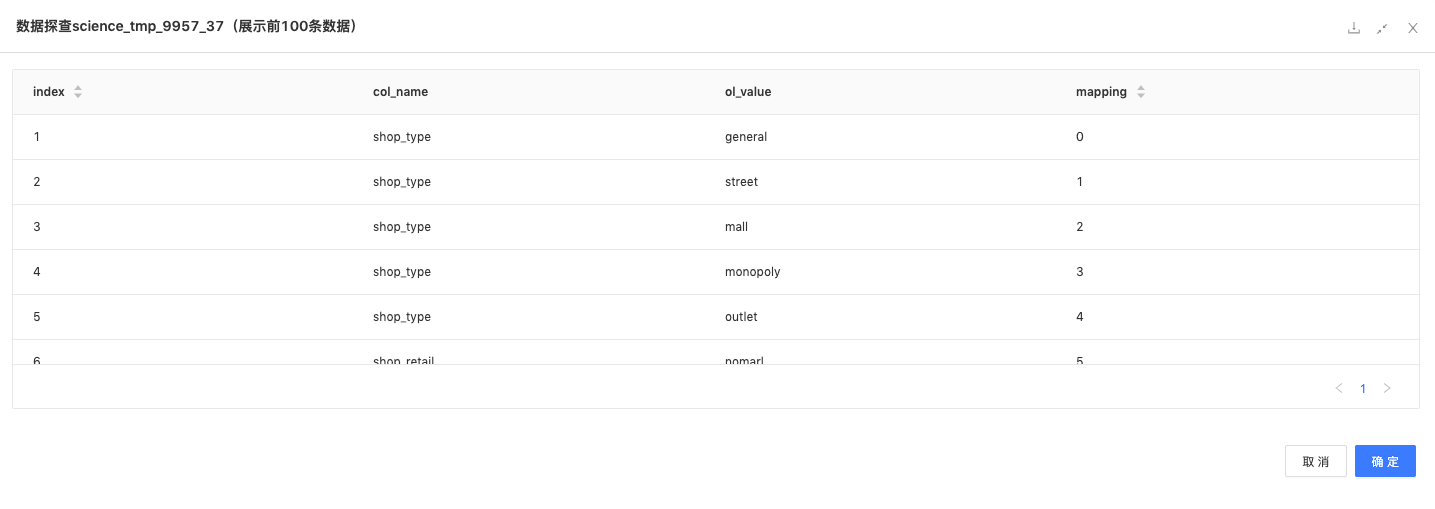
onehot编码:对门店基础数据的店铺类型和零售类型2个字段进行onehot编码,将数据映射成数字;
-
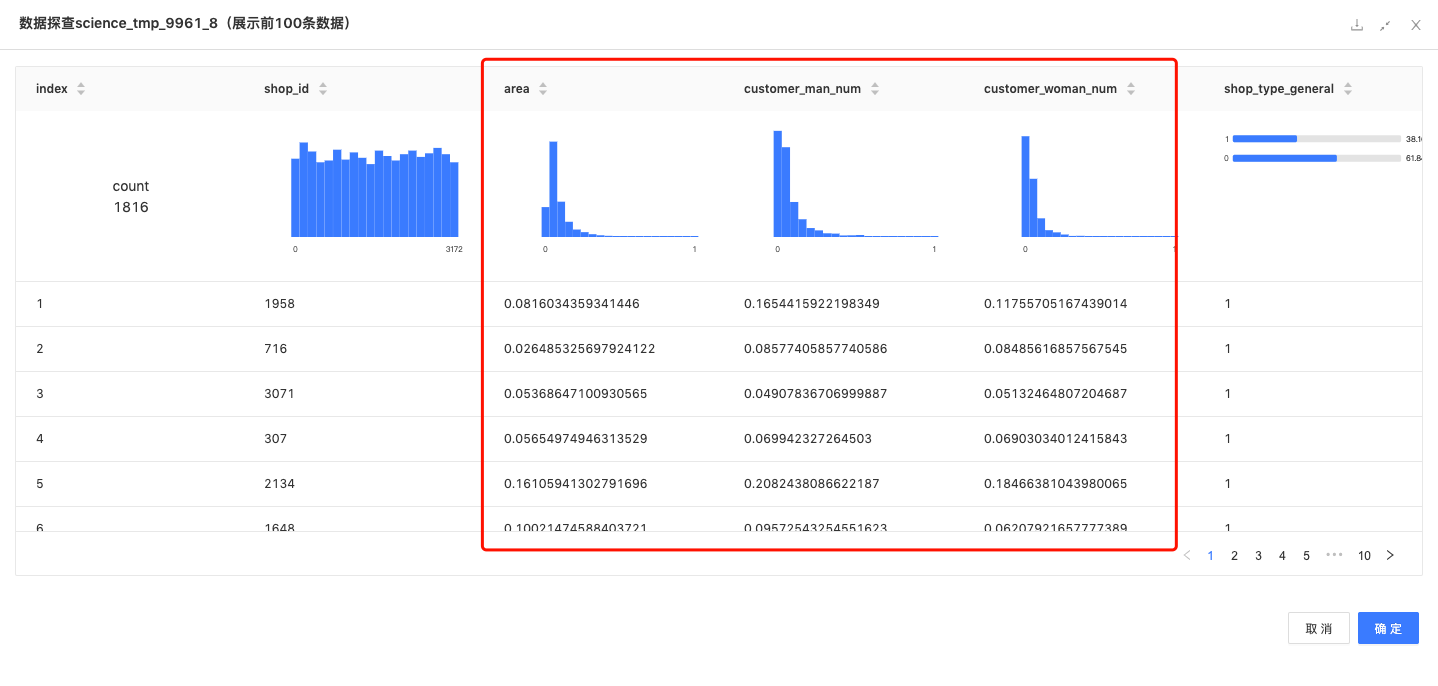
归一化:分别对两张表中的面积、男会员数、女会员数、门店经纬度进行归一化;
-
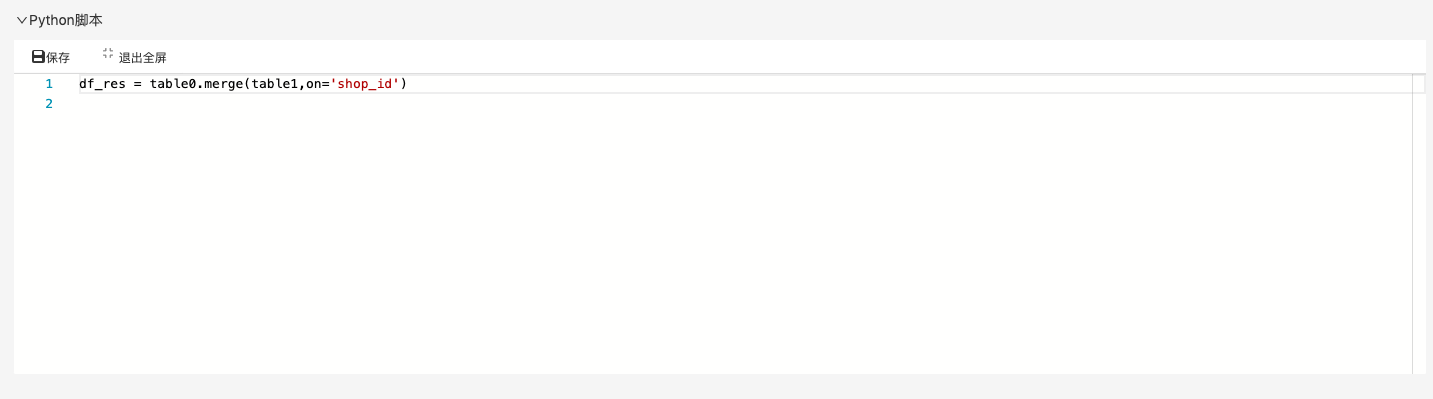
Python脚本:对两张表中的数据进行merge;
-
PCA主成分分析:通过PCA组件进行降维,减少变量;
-
Kmeans聚类:通过Kmeans聚类算法,以样本间距离为基础,将n个对象分为k个簇,使群体与群体之间的距离尽量大,而簇内具有较高的相似度,对门店进行聚类;
-
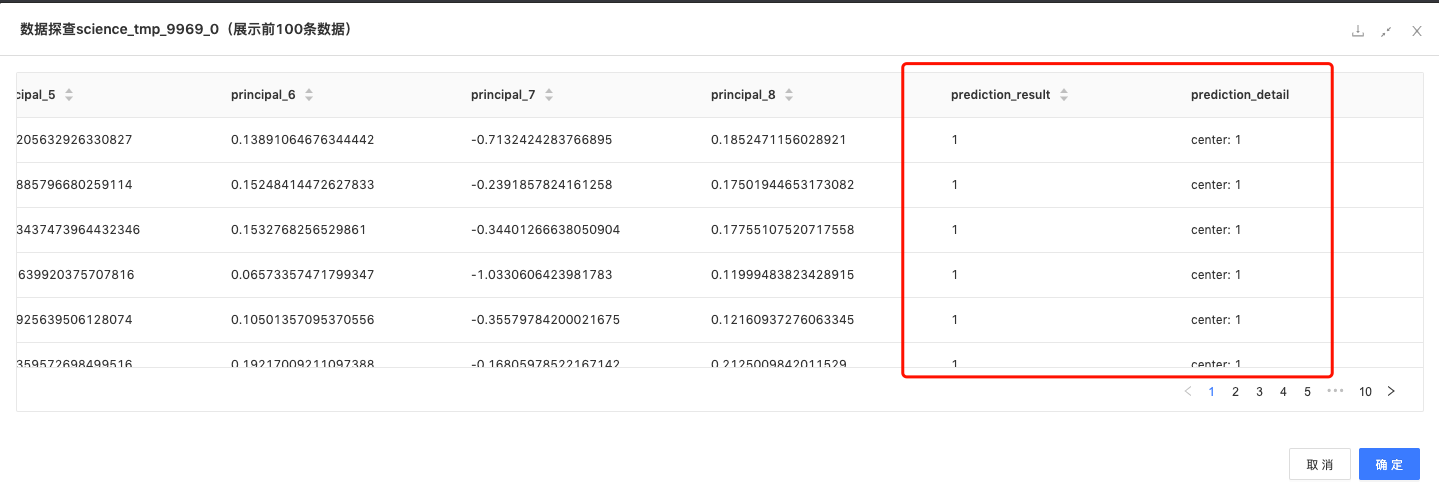
预测:对输入数据进行模型预测;
-
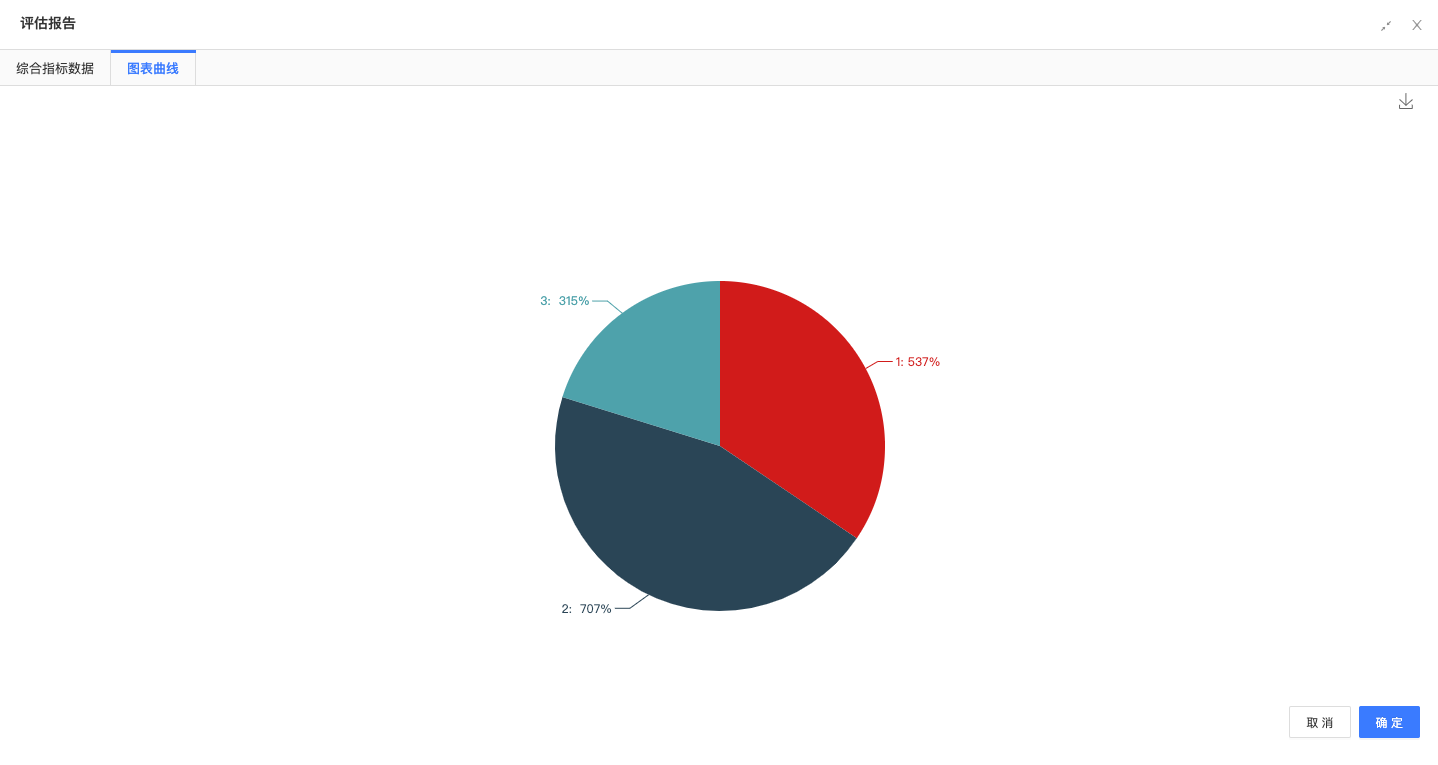
聚类评估:通过聚类评估组件,查看评估效果;
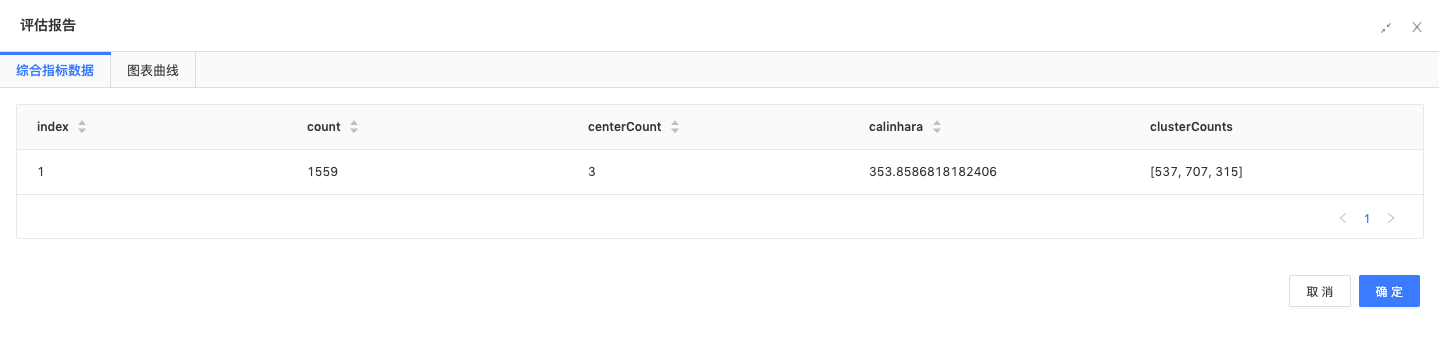
聚类成3类,每类数量分别是537、707、315。