评论情感分析
实验基础信息
-
实验名称:评论情感分析
-
实验英文名:EmotionAnalysisOfComment
-
所属类目:智能运维
-
实验描述:根据用户的外卖评论数据,分析评论中的情感偏向,得出该评论是正向还是负向评价
-
主要应用算法:分词、LDA、XGB分类
实验搭建
实验整体流程如下:
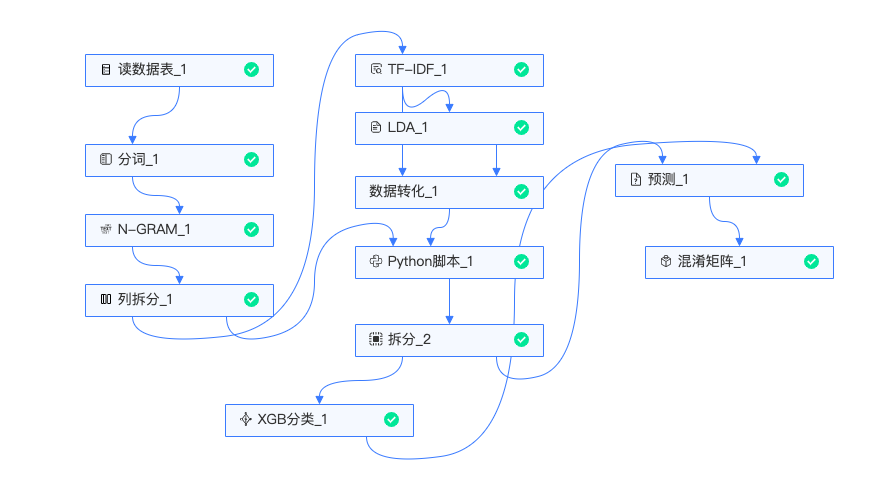
-
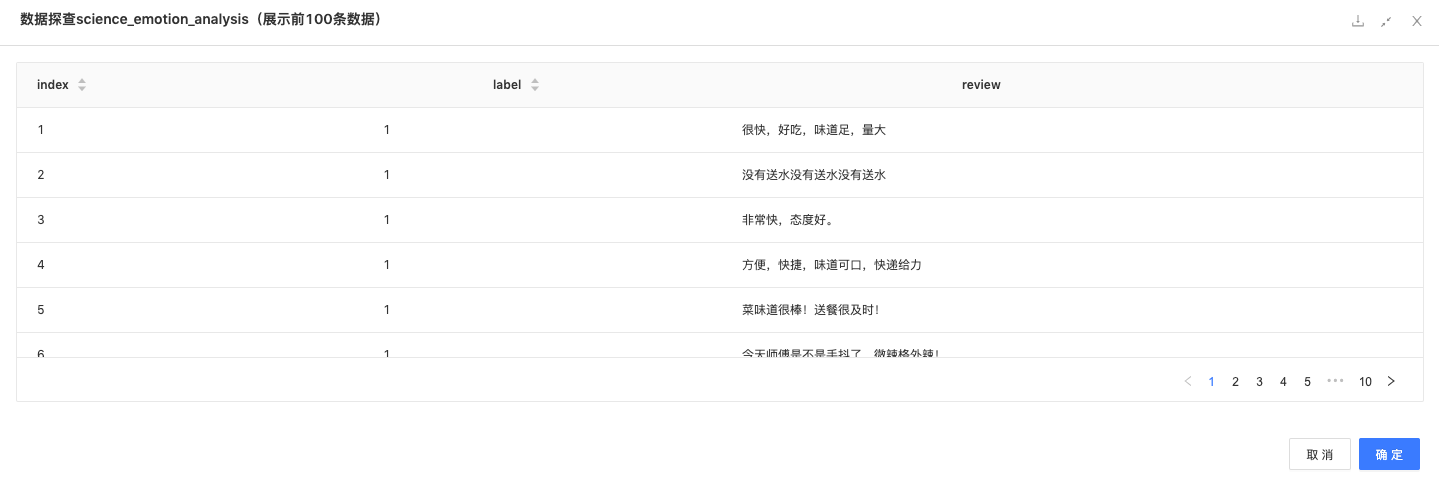
读入数据:读入外卖评论原始数据。
-
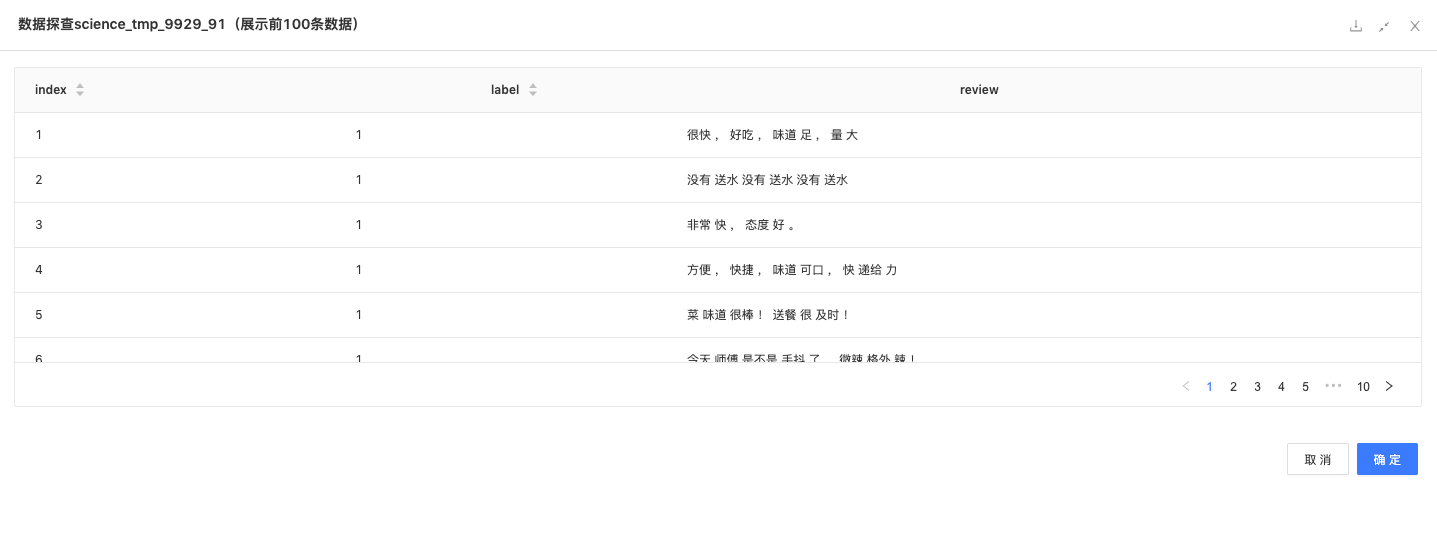
分词:通过Tokenization组件将用户评论的每句话分解成字词单位,方便后续的处理的分析。
-
N-Gram:将分词后的数据进行再组合。
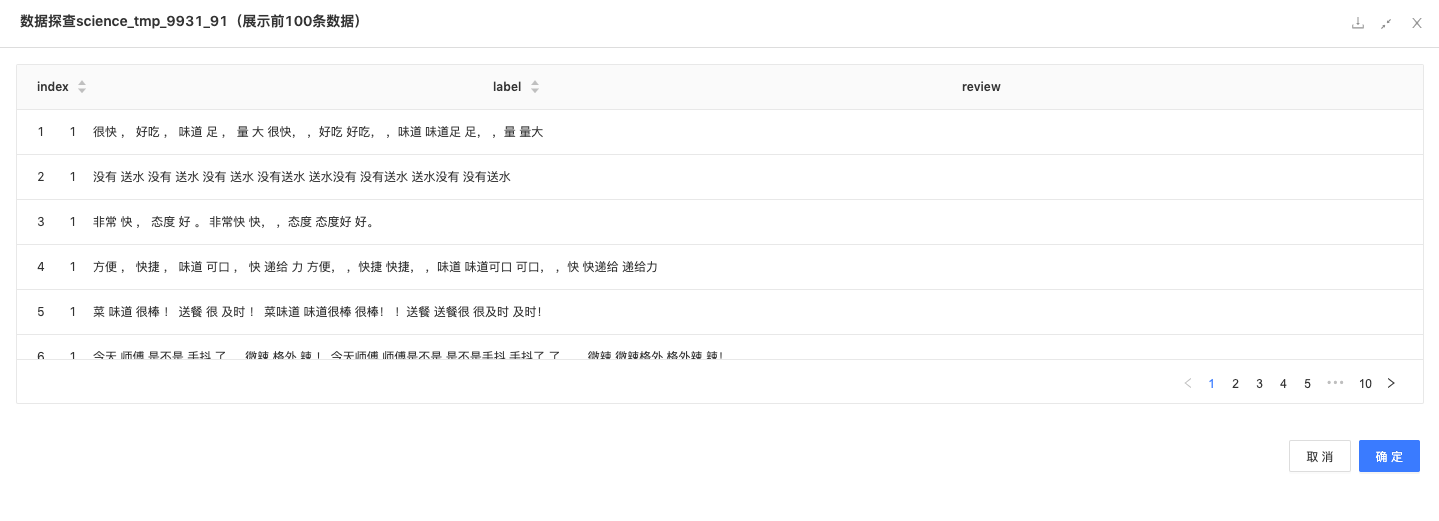
-
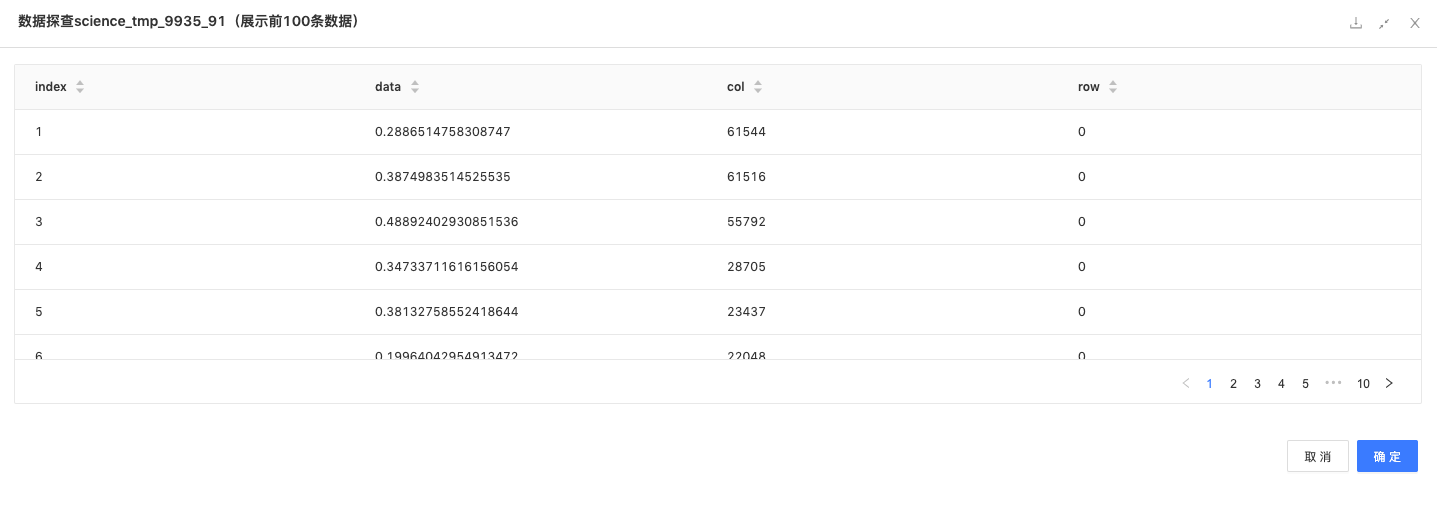
TF-IDF:将分词后的数据用TF-IDF算法转化为数值。
-
TF-LDF组件:用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。
-
-
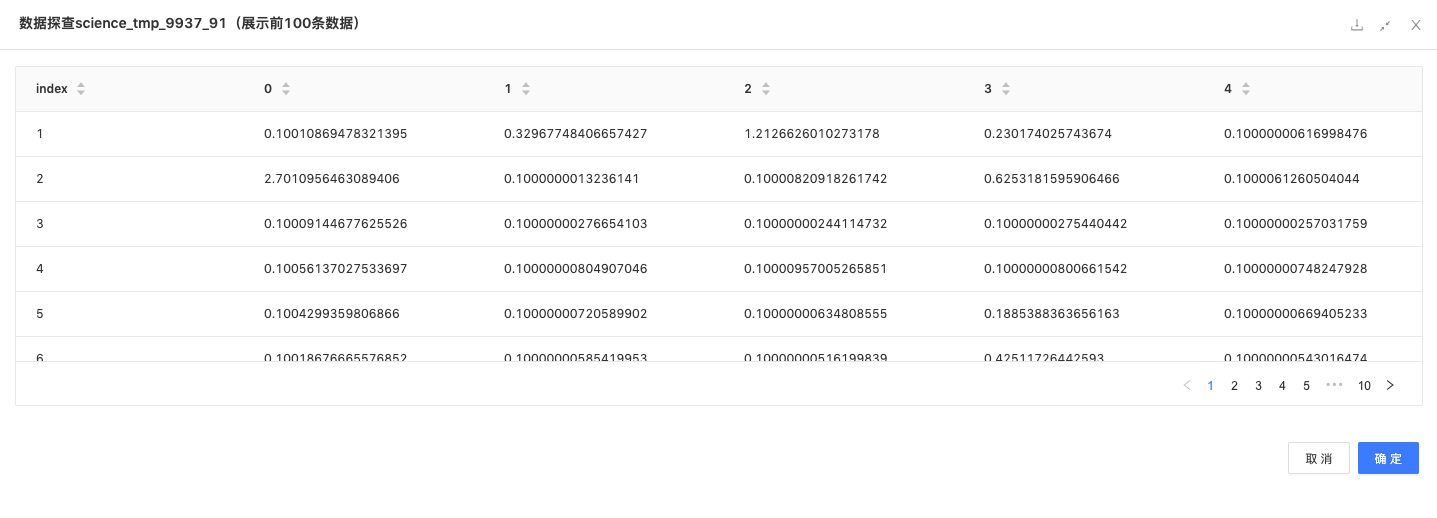
LDA:获取每句话的隐语义。
-
LDA组件:Latent Dirichlet Allocation组件,又称为LDA,是一种文档主题生成模型,也称为一个三层贝叶斯概率模型,包含词、主题和文档三层结构。
-
-
列拆分、Python脚本:将隐语义和用户评分数据拼接。
table1['label'] = table0['label']
df_res = table1-
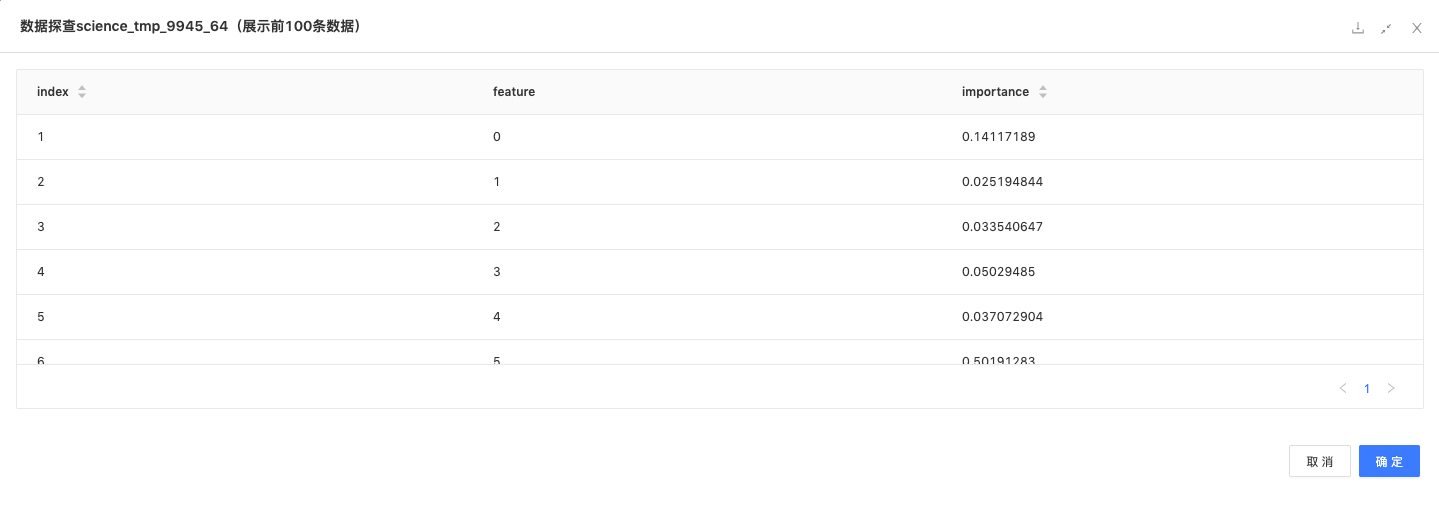
XGB分类:训练一个分类模型拟合隐语义和用户评分之间的关系。
模型特征重要性如下:
-
拆分:将数据按照8:2比例拆分成训练数据与测试数据。
-
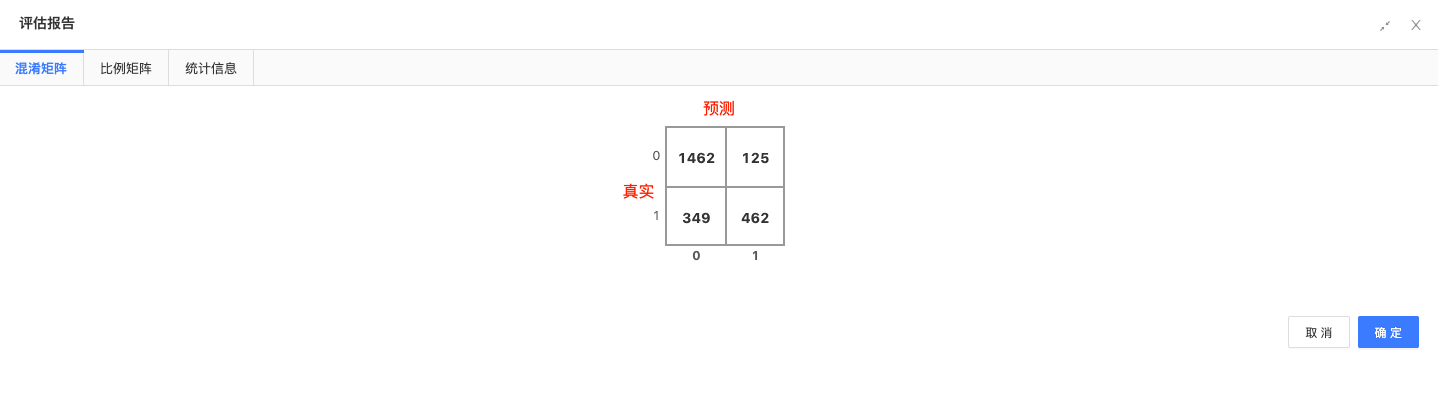
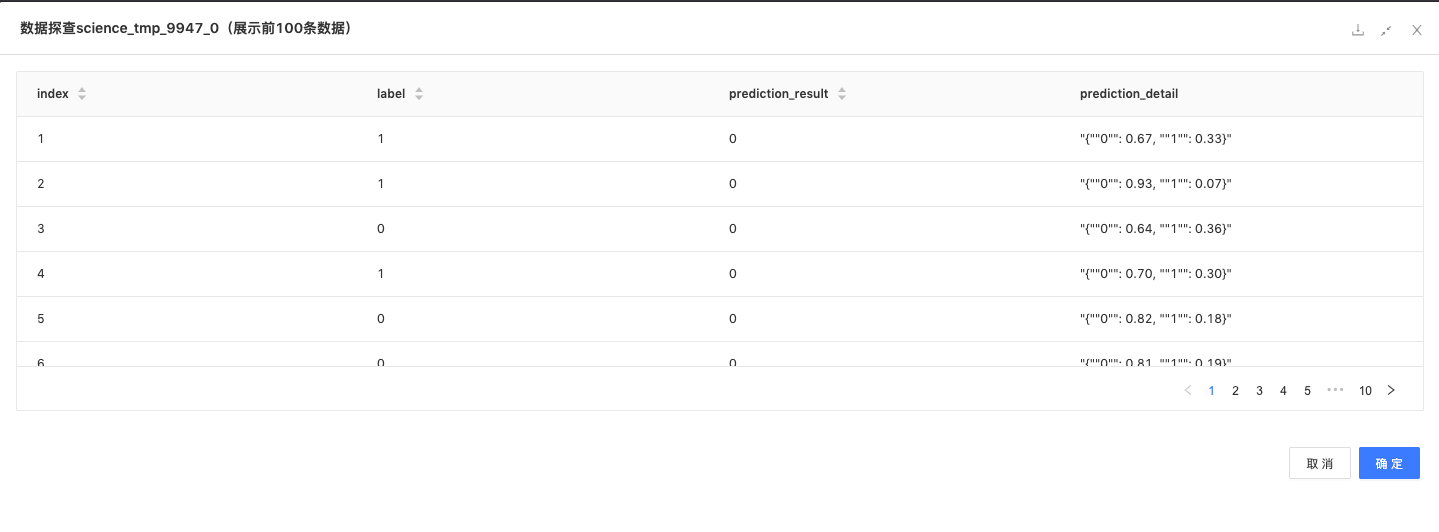
预测:用训练好的模型预测测试数据,预测结果如下:
-
混淆矩阵:进行模型评价,混淆矩阵结果比例为[0.92,0.08,0.43,0.57]